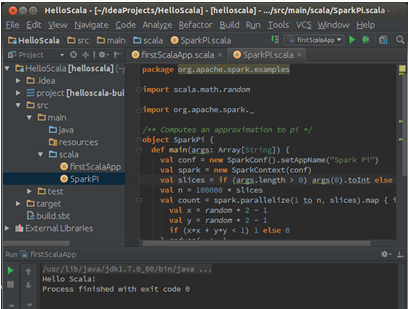
第四步:通过Spark的IDE搭建并测试Spark开发环境
Step 1:导入Spark-hadoop对应的包,次选择“File”–> “Project Structure” –> “Libraries”,选择“+”,将spark-hadoop 对应的包导入:
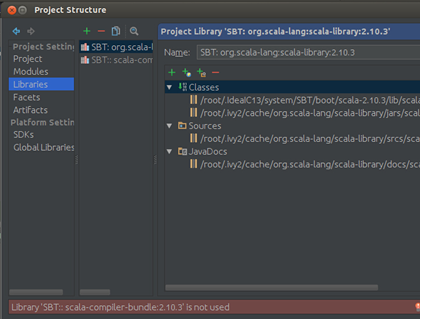
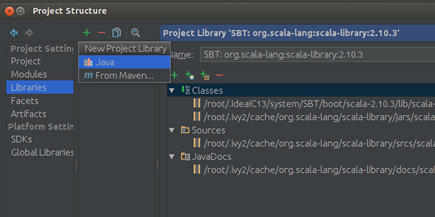
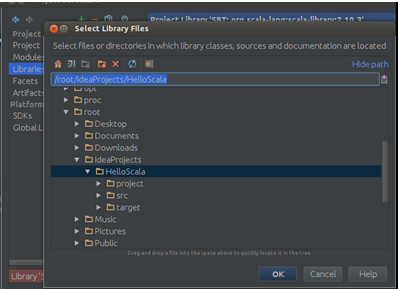
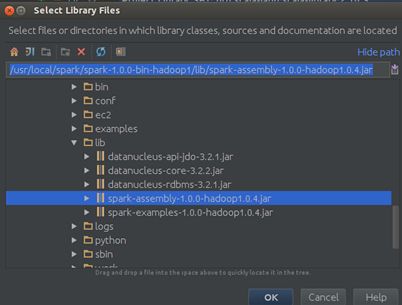
点击“OK”确认:
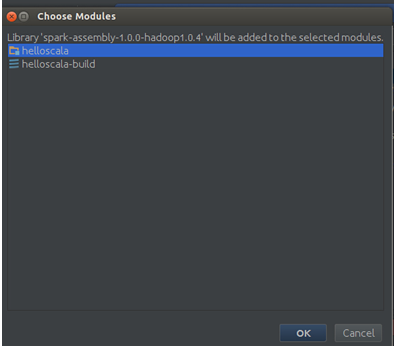
点击“OK”:
IDEA工作完成后会发现Spark的jar包导入到了我们的工程中:
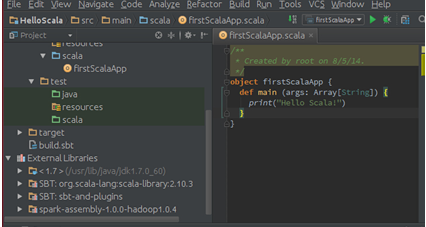
Step 2:开发第一个Spark程序。打开Spark自带的Examples目录:
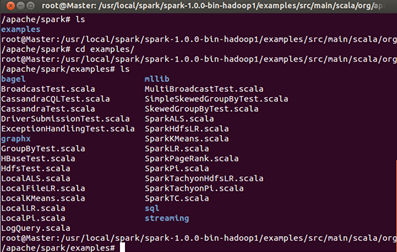
此时发现内部有很多文件,这些都是Spark给我提供的实例。
在我们的在我们的第一Scala工程的src下创建一个名称为SparkPi的Scala的object:
此时打开Spark自带的Examples下的SparkPi文件:
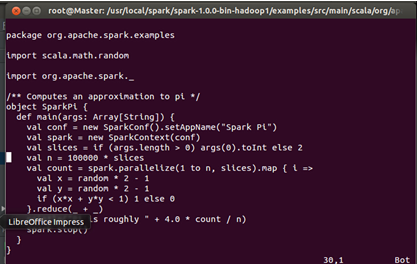
我们把该文的内容直接拷贝到IDEA中创建的SparkPi中: