本节课主要从以下二个方面来解密SparkStreaming:
一、解密SparkStreaming运行机制
二、解密SparkStreaming架构
SparkStreaming运行时更像SparkCore上的应用程序,SparkStreaming程序启动后会启动很多job,每个batchIntval、windowByKey的job、框架运行启动的job。例如,Receiver启动时也启动了job,此job为其他job服务,所以需要做复杂的spark程序,往往多个job之间互相配合。SparkStreaming是最复杂的应用程序,如果对SparkStreaming了如指掌的话,做其他的Spark应用程序没有任何问题。看下官网:Spark sql,SparkStreaming,Spark ml,Spark graphx子框架都是后面开发出来的,我们要洞悉Spark Core 的话,SparkStreaming是最好的切入方式。
进入Spark官网,可以看到SparkCore和其他子框架的关系:
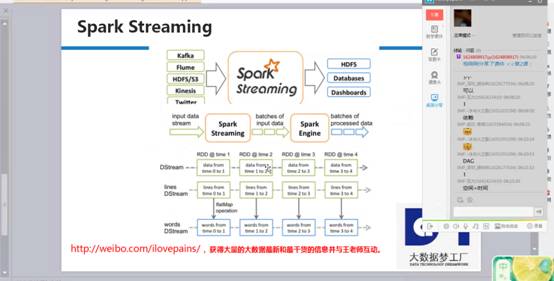
SparkStreaming启动后,数据不断通过inputStream流进来,根据时间划分成不同的job、就是batchs of input data,每个job有一序列rdd的依赖。Rdd的依赖有输入的数据,所以这里就是不同的rdd依赖构成的batch,这些batch是不同的job,根据spark引擎来得出一个个结果。DStream是逻辑级别的,而RDD是物理级别的。DStream是随着时间的流动内部将集合封装RDD。对DStream的操作,转过来是对其内部的RDD操作。
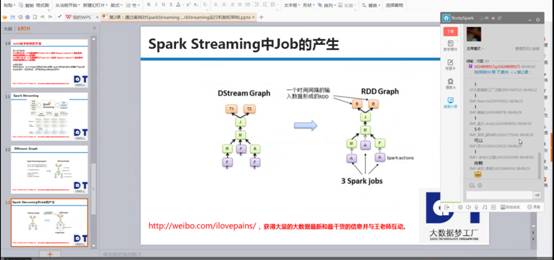
我是使用SparkCore 编程都是基于rdd编程,rdd间有依赖关系,如下图右侧的依赖关系图,SparkStreaming运行时,根据时间为维度不断的运行。Rdd的dag依赖是空间维度,而DStream在rdd的基础上加上了时间维度,所以构成了SparkStreaming的时空维度。
SparkStreaming在rdd的基础上增加了时间维度,运行时可以清晰看到jobscheduler、mappartitionrdd、shuffledrdd、blockmaanager等等,这些都是SparkCore的内容,而DStream、jobgenerator、socketInputDstream等等都是SparkStreaming的内容,如下图运行过程可以很清晰的看到:

现在通过SparkStreaming的时空维度来细致说明SparkStreaming运行机制

时间维度:按照固定时间间隔不断地产生job对象,并在集群上运行:
包含有batch interval,窗口长度,窗口滑动时间等
空间维度:代表的是RDD的依赖关系构成的具体的处理逻辑的步骤,是用DStream来表示的:
1、需要RDD,DAG的生成模板
2、TimeLine的job控制器、
3、InputStream和outputstream代表的数据输入输出
4、具体Job运行在Spark Cluster之上,此时系统容错就至关重要
5、事务处理,在处理出现奔溃的情况下保证Exactly once的事务语义一致性
随着时间的流动,基于DStream Graph不断生成RDD Graph,也就是DAG的方式生成job,并通过Job Scheduler的线程池的方式提交给Spark Cluster不断的执行,
由上图可知,RDD 与 DStream之间的关系如下:
1、RDD是物理级别的,而 DStream 是逻辑级别的;
2、DStream是RDD的封装模板类,是RDD进一步的抽象;
3、DStream要依赖RDD进行具体的数据计算;
Spark Streaming源码解析
1、StreamingContext方法中调用JobScheduler的start方法:
val ssc = new StreamingContext(conf, Seconds(5))
val lines = ssc.socketTextStream("Master", 9999)
......//业务处理代码略
ssc.start()
ssc.awaitTermination()
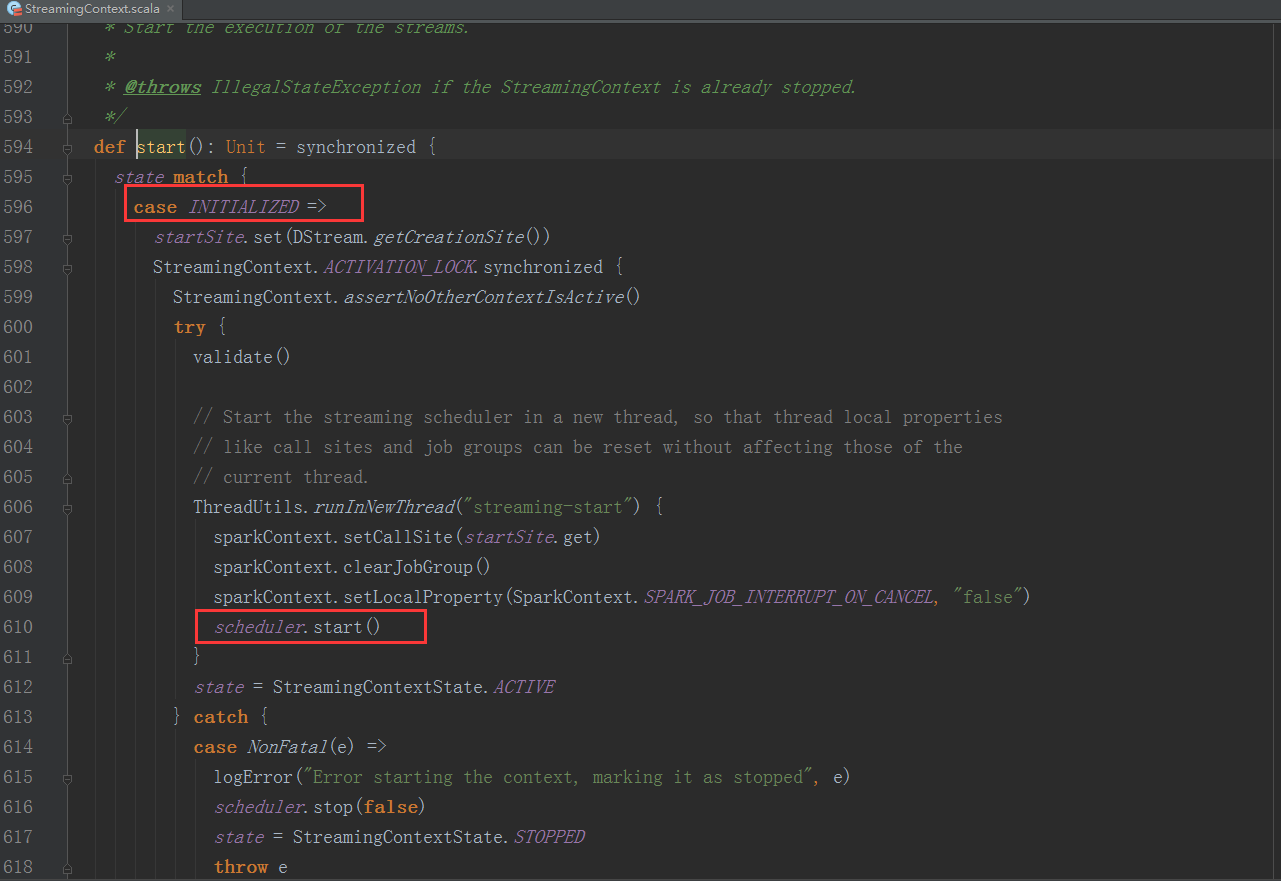
我们进入JobScheduler start方法的内部继续分析:
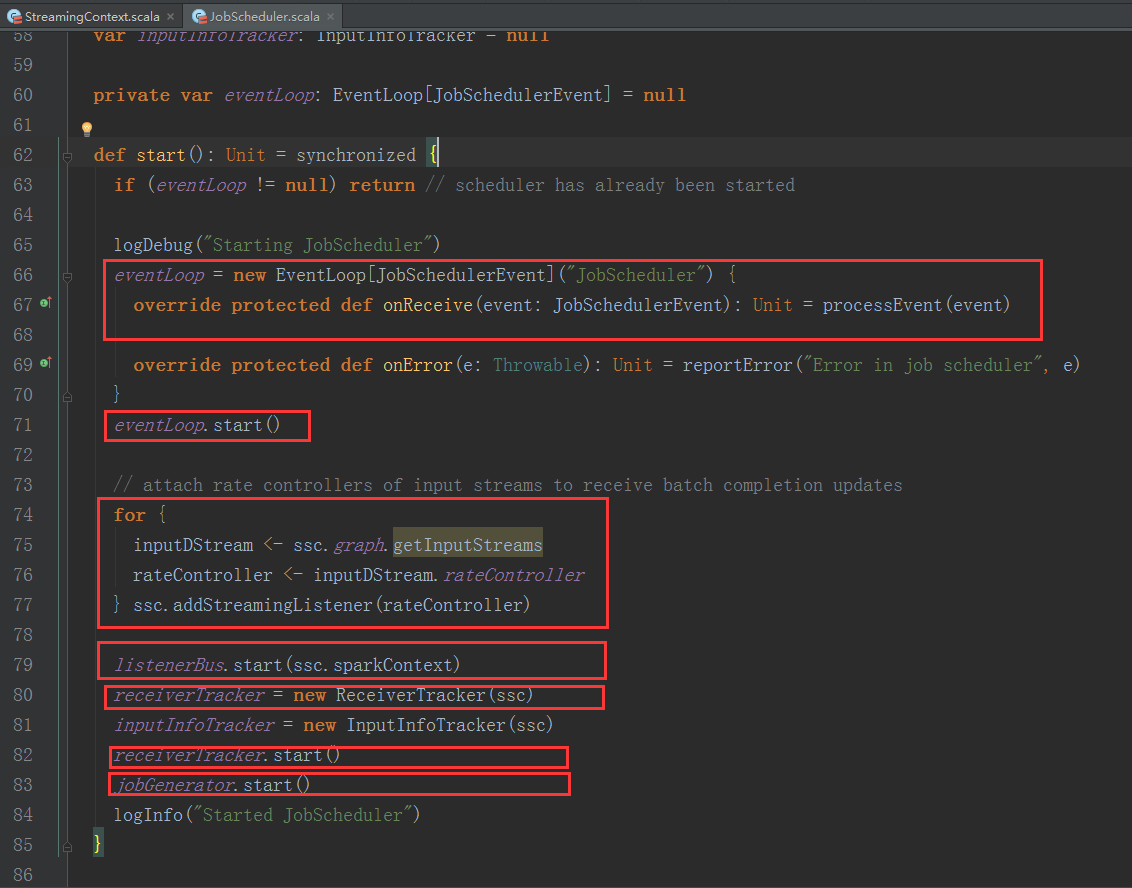
1、JobScheduler 通过onReceive方法接收各种消息并存入enventLoop消息循环体中。
2、通过rateController对流入SparkStreaming的数据进行限流控制。
3、在JobScheduler的start内部会构造JobGenerator和ReceiverTacker,并且调用JobGenerator和ReceiverTacker的start方法。
ReceiverTacker的启动方法:

1、ReceiverTracker启动后会创建ReceiverTrackerEndpoint这个消息循环体,来接收运行在Executor上的Receiver发送过来的消息。
2、ReceiverTracker启动后会在Spark Cluster中启动executor中的Receivers。
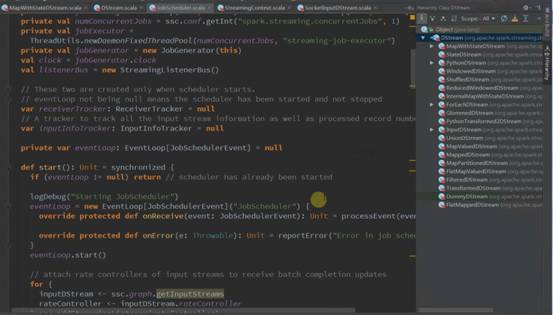
JobGenerator的启动方法:

1、JobGenerator启动后会启动以batchInterval时间间隔发送GenerateJobs消息的定时器


Spark发行版笔记2
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
邮箱:18610086859@vip.126.com