摘要:
图像超分辨率(SR)是提高计算机视觉中图像和视频分辨率的一类重要图像处理技术。近年来,利用深度学习技术实现图像超分辨率技术取得了显著进展。在调查中,我们的目的是给出在一个系统的方式中使用深度学习方法来实现图像超分辨率的最新进展。我们可以将现有的SR技术研究大致分为三类
有监督的SR(supervised SR)、无监督的SR(unsupervised SR)和特定领域的SR(and domain-specifific SR)。此外,我们还讨论了一些其他重要的问题,比如公开的基准数据集和性能评估指标。
最后,我们在总结这项调查时,强调了未来的几个方向和有待社会进一步解决的问题
索引词:—Image Super-resolution, Deep Learning, Convolutional Neural Networks (CNN), Generative Adversarial Nets (GAN)生成的对抗性网络
介绍:
图像的超分辨率(SR)是从低分辨率图像中恢复高分辨率图像是计算机视觉和图像处理中的重要一类图像处理技术。它具有广泛的现实应用,如医学成像,监视和安全 等等。除了提高图像感知质量,它还有助于改善其他计算机视觉任务。一般来说,这个问题非常具有挑战性,而且本质上是ill-posed的,因为总是有多个HR图像对应一个LR图像。在论文中,提出了多种经典的SR方法,包括:
基于预测的方法,
基于边缘的方法,
统计方法
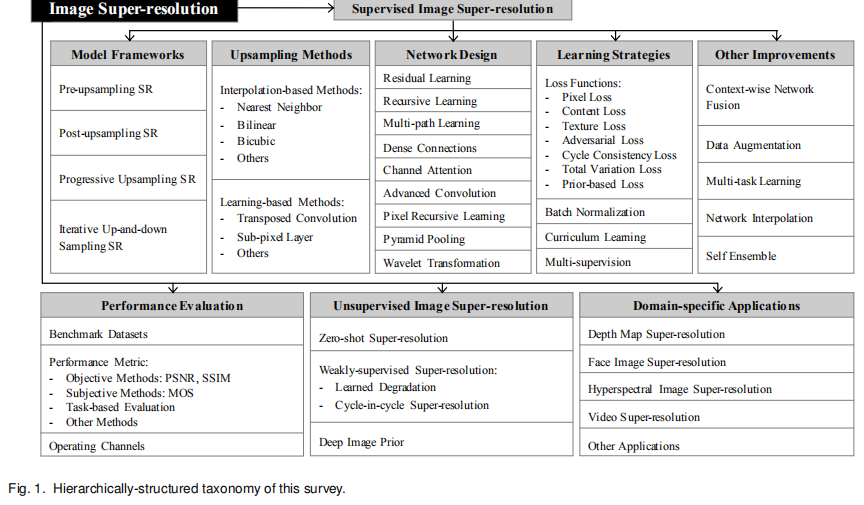
3 监督式的SR
3.1 SR的框架
现存的SR框架可以分为四类:pre-upsampling SR, post-upsampling SR, progressive upsampling SR and iterative up-and-down sampling SR
3.1.1 Pre-upsampling SR(先上采样超分辨率)
方法:利用传统的上采样算法获得更高分辨率的图像,然后使用深度神经网络对其进行细化
优点:①较困难的上采样任务是通过预定义的传统算法完成的,深度cnn只需要对粗图像进行细化,大大降低了学习难度
②这些模型可以以任意大小和缩放因子的插值图像作为输入并给出与单尺度SR模型性能相当的精确结果
缺点:预先定义的上采样方法通常会引入一些副作用(例如,噪声放大和模糊),而且由于大多数操作是在高维空间中执行的,时间和空间成本比其他框架要高得多
3.1.2 Post-upsampling SR(后上采样超分辨率)
目的:为了解决Pre-upsampling SR计算效率问题,充分利用深度学习(DL)技术自动提高图像分辨率
方法:在取代先上采样操作,在低维空间进行mapping操作,然后在最后放置一个端到端可学习的上采样层
优点:计算量大的非线性卷积特征提取过程只发生在低维空间中,并且分辨率只有在网络的最末端才会增加。使得计算复杂度和空间复杂度大大降低,同时训练速度和推理速度也大大提高
缺点:一方面,上采样操作只有一步,大大增加了大尺度因子的学习难度,
另一方面,每个尺度因子都需要一个单独的SR模型,无法满足多尺度SR的需要
3.1.3 Progressive Upsampling Super-resolution(渐进式上采样超分辨率)
目的:解决后上采样的缺点
方法:该框架下的模型基于串联的cnn,逐步重构出更高分辨率的图像。即:在每一阶段,图像上采样到一个更高的分辨率,并由cnn进行细化
优点:通过将困难task分解为简单task,该框架下的模型不仅极大地降低了学习难度,获得了更好的性能,特别是在large factors的情况下,而且在不引入过多的空间和时间代价的情况下解决了多尺度的超分辨率问题。
缺点:多阶段模型设计复杂,训练难度大,需要更多的设计结构设计指导和更高级的训练策略。
3.1.4 Iterative Up-and-down Sampling Super-resolution(迭代式的上下采样)
目的:为了更好地捕捉LR-HR图像对的相互依赖性
方法:一种称为back-projection的迭代过程被纳入到SR中用来缩小LR-HR之间的关系。迭代的使用这种过程来进行微调,也就是先计算重建的错误,然后用它来调节HR图像的亮度。这种思想被用来构建了DBPN(deep back-projection networks),结合着上-下采样层,可以交替的在上采样层和下采样层之间互相连通,最终使用中间的HR图像的特征图的串联得到最后的结果。
优点:可以获得LR-HR图像之间深层次的关系,并以此获得更好的重建结果
缺点:对back-projection的设计标准并不明确,结构很复杂,需要手动设计。有很大的探索与改进空间
3.2上采用的方法
上采样:在应用在计算机视觉的深度学习领域,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(e.g.:图像的语义分割),这个采用扩大图像尺寸,实现图像由小分辨率到大分辨率的映射的操作,叫做上采样(Upsample)。
【https://www.zhihu.com/question/48279880/answer/525347615】
除了在模型中何处应用上采样操作外,如何实现上采样也非常重要
3.2.1 基于插值的上采样
最近邻插值:
双线性插值:
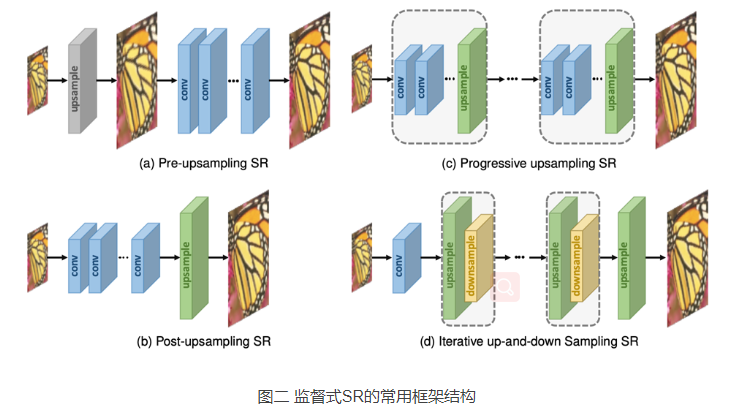
图3 灰板为像素坐标,蓝点、黄点、绿点分别为初始像素、中间像素和最终像素。
双三次插值:
和双线性插值很像,在两个维度上进行三次插值,涉及x了 4×4 的区域,效果更加平滑,但是速度慢点,这种方法也广泛用于构建SR数据集(也就是从HR到LR的生产)以及应用于先上采样SR框架
总的来说,基于插值的上采样方法只是根据图像本身的内容来提高图像的分辨率,而不会带来更多的信息。相反,它们经常在SR模型中引入一些副作用,如计算复杂度、噪声放大、结果模糊等
3.2.2 基于学习的上采样
为了克服基于插值的方法的缺点,以端到端方式学习上采样操作,在超分辨率域中引入了转置卷积层(transposed convolution layer )和亚像素层(sub-pixel layer)。
反卷积层:
反卷积是一种特殊的正向卷积,先按照一定的比例通过补 来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积。
图4展示了如何使用 3×3 的卷积核来获得两倍的上采样。新增的像素点设置为0,然后利用一个 3×3 的卷积核(padding=1,stride=1)来执行卷积操作。首先对原图扩大两倍通过这样的操作,将输入特征图的上采样扩大2倍,此时接受视野最大为2x2,
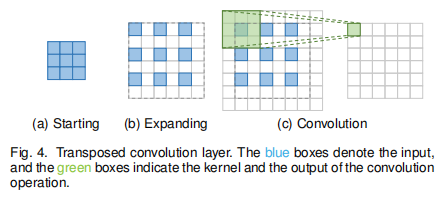
输入是3x3(如a),论文想输出一个6x6的,所以将输入的按2倍扩展(如b,扩展不是padding),由之前的3x3扩展为6x6(想要输出多大,就扩展多大),在扩展的基础上进行padding(如图c左,灰色虚线的最外层,则为padding的),然后用3x3的卷积核进行卷积,得到6x6的输出
亚像素层:
如何评价超分辨率
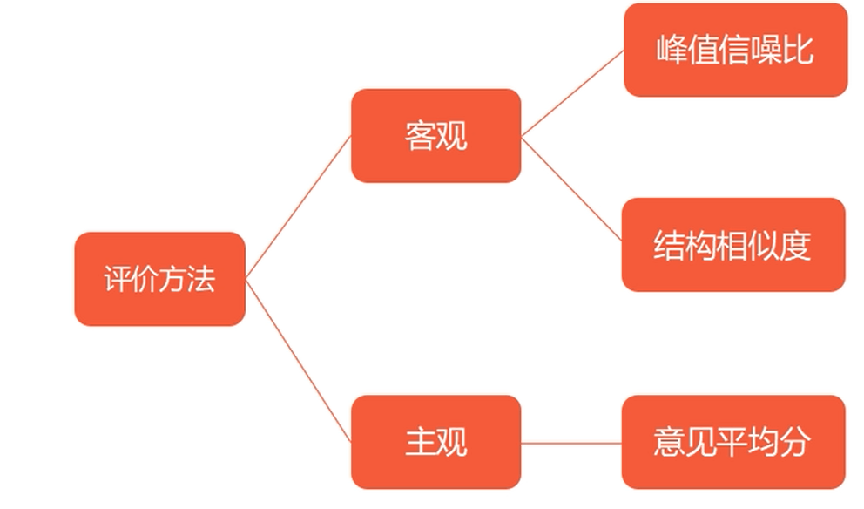

PSNR:比较原始图像与生成图像之间的偏移程度。PSNR越大,表明HR与SR偏移程度就越小
SSIM:结构像素度。SSIM从亮度,对比度和结构三个方面来评估两幅图片的相似性。

MOS:意见平均分。每个评分人对同一幅图的评分结果可能不一样。但是当有多个评分人的时候,此方法还是可行的。【但是也有费力不讨好】
基于上面几种评判标准,引入了perpetual loss。即从对原图输入网络中的到的特征图与超分辨率图片输入网络中得到的特征图进行loss【即特征图与特征图之间计算loss】
perpetual loss 比较的是特征语义之间的差异而不是像素上的差异。