一、论文的目的
提高非常低分辨率的人脸图像的质量和理解
图像的质量:我们的目标是提高分辨率和恢复真实世界的低分辨率面部图像的细节
图像的理解:我们希望通过对一组预定义的具有语义意义的面部标志(如鼻尖、眼角等)进行定位来提取中高级面部信息(这个任务也称为人脸对齐)
二、 论文解决的两个挑战:
1)提高低分辨率人脸图像的质量
2)在低分辨率图像上准确定位人脸特征点
三、论文的五大贡献:
(1)提出Super-FAN:一个同时提高人脸分辨率并进行人脸对齐的端到端系统,主要通过热图回归(Heatmap Regression)整合子网络进行人脸关键点定位,然后进入基于GAN的超分辨率处理网络,并将其并入到一个新的热图损失中。
(2)展示了联合训练两个网络在处理任意人脸姿势的生成图像以及真实世界的低分辨率图像上的优势
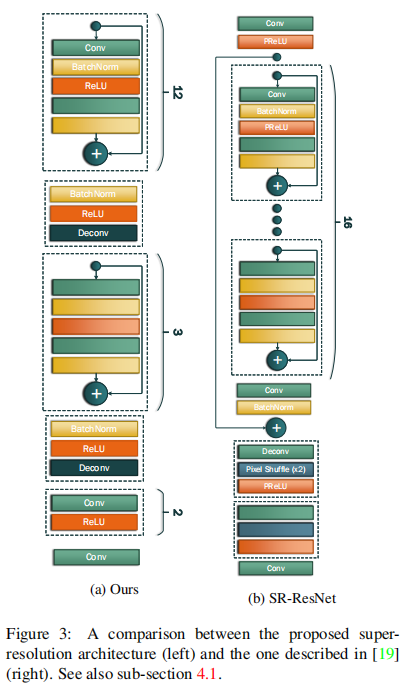
(3)提出了一个改进的残差网络结构(Super-resolution network中的)来得到较好的超分辨率图像
(4)首次提交了处理LS3D-W数据集各种人脸姿势的结果,并在超分辨率和人脸对齐方面做出了领先的结果。
(5)首次在真实世界的低分辨率人脸图像(WiderFace数据集)上做出了良好的视觉效果
四、方法

作者提出的网络结构主要由三个连接在一起的子网络构成:第一个是超分辨率网络,用于提升LR图像的分辨率;第二个是一个判别器网络,用于区别得到的超分辨图像和原始LR图像;第三个是FAN网络,是一个在超分辨率图像上进行人脸关键点定位的人脸对齐网络。其中超分辨率网络和判别器网络构成一个GAN模型,如上图所示
4.1Super-resolution network
4.1.1Pixel and perceptual losses

W和H表示ILR的大小,r为上采样因子
Perceptual loss
虽然像素的MSE损失达到了很高的PSNR值,但它经常导致图像缺乏细节,模糊和不现实。为了解决这点作者用了perceptual loss。
perceptual loss用于衡量高分辨率图像和低分辨率图像在特征空间的相近程度。作者根据前面超分辨率网络的结构,用三个块(B1,B2,B3)
对应的低、中、高级特征来计算perceptual loss:

其中φi表示Bi块的最后一个卷积层的特征图。Wi和Hi表示它的大小
4.2. Adversarial network
对抗网络的主要目的是提升超分辨率的效果。在这个GAN模型中,GAN的生成器G(超分辨率网络)通过判别器以及对抗损失(adversarial loss)可以强制性的生成一些更加现实的超分辨率图像,作者使用的GAN是改进的WGAN(M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein gan. 和 I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, and A. Courville. Improved training of wasserstein gans.)
Adversarial loss
根据WGAN的定义,人脸超分辨率网络的损失为:


4.3. Face Alignment Network
发现 pixel, perceptual and adversarial损失函数单独使用时,与姿势或表情相关的细节可能会丢失或面部部分可能定位不正确。
为了获得更好的细节,作者通过热图回归(heatmap regression)将人脸关键点定位(facial landmark localization)集成到超分辨率过程中并且优化一个适当的热图损失,从而增强超分辨率图像和原始图像的结构一致性。
根据论文内容,每个人脸关键点由一个二维高斯分布刻画,而人脸关键点的位置对应着二维高斯分布的中心,FAN则使用热图回归的概念来定位关键点,也就是需要回归对应的二维高斯分布(即热图)。根据之前的一些工作,这些热图可以捕获形状信息(姿势,表情等),空间背景和各部分结构关系。通过最小化超分辨率图像和原始图像的热图差距,可以进行人脸定位,并且保证两图像之间具有一致的人脸结构。于是作者基于两个 FAN结构 (A. Bulat and G. Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks).ICCV, 2017.),将超分辨率网络的输出图像作为一个FAN的输入并进行训练,使得这个FAN的输出与另一个直接作用在初始图像上的FAN的输出相同。
4.3.1 Heatmap loss
基于以上讨论,我们提出通过定义热图损失来加强超分辨和对应HR人脸图像之间的结构一致性

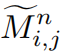 是对应于像素点(i,j)处的第n个人脸关键点(landmark)的热图,在超分辨率图像
是对应于像素点(i,j)处的第n个人脸关键点(landmark)的热图,在超分辨率图像 运行FAN产生,
运行FAN产生,![]() 是由另一个FAN在初始图像IHR上运行得到
是由另一个FAN在初始图像IHR上运行得到
我们的热图损失的另一个关键特性是,它的优化不需要访问ground truth landmark annotation,只需要访问一个预先训练好的FAN。这允许我们以一种弱监督的方式训练整个超分辨率网络
4.4. Overall training loss



疑惑:
1. discriminator与FAN两个网络的联系是什么?
2. 论文中的数学公式,中数学符号为啥要那样表示?是因为可以根据自己模型的需求来自行定义的变量吗?
答:
1. GAN中的判别器只在训练的时候用,测试的时候不用。在Super-FAN网络中的的输入图像是由清晰的图像(即ground-truth)经过上采样的方法(如双三次插值算法(bicubic))将原来的ground-truth变模糊。让变模糊的人脸图片输入到生成器的网络中,产生对应的超分辨率人脸图片。该超分辨率人脸图片和ground-truth一起输入到判别器中。如果判别器判别出ground-truth为真,生成超分辨人脸图片为假,则生成器继续生成超分辨率图像,然后再和ground-truth一起输入到判别器中判断真假。一直持续判别,直到判别器判别ground-truth和生成的超分辨率人脸图片真假都各占一半时,说明生成器生成的超分辨率人脸图像和ground-truth非常的接近。这样我们就把人脸的超分辨率图像训练成功了。记录其参数,在该参数下输入测试人脸图像,生成测试的人脸超分辨率图像,然后将生成的图像在输入到FAN网络中进行人脸对齐。
2. 如pixel loss和 perpectual loss很多论文中公式格式都一样的,只不过是他们的表示中用到的符号可能不一样
疑惑是跟师姐交流过后自己总结的,不一定完全正确,欢迎各路豪杰指正
参考链接:https://www.leiphone.com/news/201706/ty7H504cn7l6EVLd.html
https://www.leiphone.com/news/201612/Cdcb1X9tm1zsGSWD.html?viewType=weixin
https://blog.csdn.net/qq_34919953/java/article/details/83449435