一、对find_all()方法举例
"""基于bs4库的HTML内容查找方法""" import requests from bs4 import BeautifulSoup import re url = "https://python123.io/ws/demo.html" r = requests.get(url) demo = r.text soup = BeautifulSoup(demo, "html.parser") # 查找所有a标签 print(soup.find_all('a')) # 查找a标签和b标签,[]表示 print(soup.find_all(['a','b'])) # 查找所有标签 print(soup.find_all(True)) # 输出所有标签名 for tag in soup.find_all(True): print(tag.name) print('*'*30) # 查找所有以b开头的标签 for tag in soup.find_all(re.compile('b')): print(tag.name) # 查找P标签中属性包含course字符串的信息 print(soup.find_all('p', 'course')) print('*'*30) # 查找id属性为某一特定值的属性(是精确查找) # [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>] print(soup.find_all(id = 'link1')) # []没有属性完全为link的标签 print(soup.find_all(id='link')) # [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, # <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>] # 根据属性部分信息进行查找,需要用正则表达式 print(soup.find_all(id=re.compile('link')))
########################################### # 是否对子孙全检索,默认为True。设为False时只查找子元素 print(soup.find_all('a', recursive=False)) # [] print(soup.find_all('a')) # 所有a标签
########################################### # 对string的精确查找 print(soup.find_all(string="Basic Python")) # ['Basic Python'] # 查找含有Python字符串的string print(soup.find_all(string=re.compile("Python")))
二、find_all()函数非常常用
所以有:
# <tag>(..) 等价于 <tag>.find_all(..)
# soup(..) 等价于 soup.find_all(..)

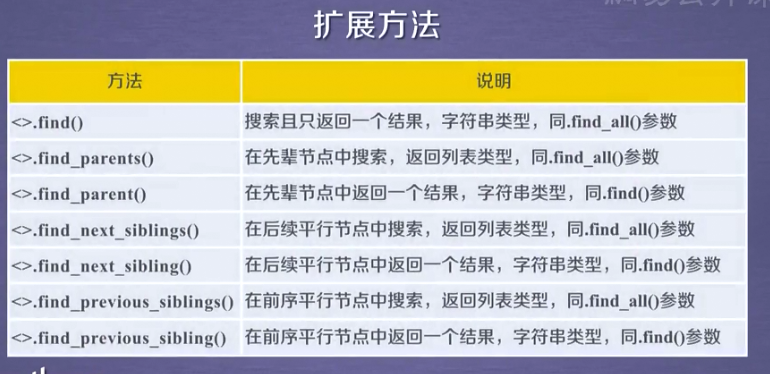
三、和find_all()方法类似的方法