常用集合
set
Set不按特定方式进行排序,并且没有重复的对象,它的有些实现类能对集合中的对象按照特定的顺序排序。主要有两个实现类:HashSet和TreeSet
HashSet按照哈希算法来存取集合中的对象,存取速度比较快。
TreeSet实现了SortSet接口,具有排序功能。
List
List主要特征是以线性方式存储,集合中允许存放重复对象主要实现类包括ArrayList和LinkList
ArrayList代表长度可变的数组,允许对元素进行快速的随机访问,但是向ArrayList中插入与删除元素较慢。
LinkList在实现中采用链表的结构,插入和删除元素较快,随机访问则相对较慢。
LinkList单独具有addFirst(),addLast(),getFirst(),getLast(),removeFirst(),removeLast()等方法这些方法使得LinkList可以作为堆栈,队列和双向队列使用
Queue
Queue队列中的对象按照先进先出的规则来排列。在队列末尾添加元素,在队列的头部删除元素。可以有重复对象。
双向队列Deque则允许在队列的尾部和头部添加和删除元素。
因为LinkList可以作为双向队列使用,所以Queue和Deque使用比较少
Map
HashMap不保证映射的顺序,特别是它不保证该顺序恒久不变。(也就是无序)
HashMap底层基于散列表实现,由数组加链表组成,数组是HashMap的主体,链表用来解决Hash冲突
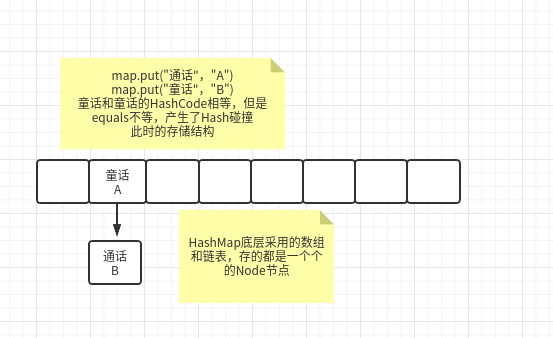
采用key的hashCode()方法结合数组长度通过无符号右移>>> 异或^ 计算出数组索引,通过链表法解决哈希冲突(如果key值equals()则替换旧的value),
平方去中法 取余数 伪随机数法
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// aka 16 默认初始容量是2的n次幂,可以减少哈希碰撞3&(8-1)=3 2&(8-1)=2 | 3&(9-1)=0 2&(9-1)=0
DEFAULT_LOAD_FACTOR=0.75 代表数组满的程度,如果小 则数组利用率不高,太大 则更容易产生Hash碰撞(每个桶的链表会变多)
JDK1.8之后链表长度超过8,并且数组长度大于64会进化成红黑树(红黑树查询O(logn) 链表O(n))
TreeMapTreeMap基于红黑树(Red-Black tree)的 NavigableMap 实现,有序。
HashMap是使用hashCode和equals方法去重的。而TreeMap依靠Comparable或Comparator来实现key去重
并发类容器(集合)
在java集合框架中,Set List Queue Map的实现类都没有采取同步机制。在单线程环境中,这种实现方式会提高操纵集合的效率,java虚拟机不必会因为管理用不锁而产生额外的开销。
在多线程环境中,可能会有多个线程同时操纵一个集合,比如一个线程在为集合排序,而另外一个线程正不断的向集合中添加新的元素。
为了避免并发问题,可以直接采用java.util.concurrent并发包提供线程安全的集合。列如
ConcurrentHashMap 、ConcurrentSkipListMap、ConcurrentSkipListSet和ConcurrentLinkedQueue。
这些集合的底层实现采用了复杂的算法,保证多线程访问集合时,既能保证线程之间的同步,又具有高效的并发性能。
Hashtable:
Hashtable,用作键的对象必须实现 hashCode 方法和 equals 方法。HashTable 由于所有方法都加了 synchronized 关键字所以是线程安全的。
如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
历史集合类 :Vector Hashtable Stack Enumeration 在实现中都采用了同步机制,并发性能较差,因此不提倡使用它们。
ConcurrentHashMap:
JDK7:ConcurrentHashMap采用了分段锁的,把容器默认分成16段,put值的时候 只是锁定16断中的一个部分,就是把锁给细化了
JDK8:
疑问:HashMap有线程安全的ConcurrentHashMap 但是TreeMap为什么没有ConcurrentTreeMap
因为CAS操作用在红黑树实现起来太复杂
所以用ConcurrentSkipListMap用CAS实现排序(跳表代替Tree)
跳表:在链表的基础上一层一层的加一些个关键元素的链表,加了个索引。跳表的查找效率比链表本身要高,同时它的CAS实现难度比TreeMap容易很多
常用方法(Object类)
equals()方法判断两个对象是否“相等”。如果不重写这个方法,equals两个对象 除非是同一个引用,否则一直不相等(返回false)。
Eclipse默认给我们重写的equals()方法,是对象的所有成员变量是否都相等,如果该对象和比较对象的成员变量都相等 则两个对象互相equals() 也就是相等。
我们都知道Set集合存放的对象都是不可重复的,Set集合就是根据对象的equals方法判断对象是不是重复
注意:当此方法被重写时,通常有必要重写 hashCode 方法,以维护 hashCode 方法的常规协定,该协定声明相等对象必须具有相等的哈希码。
返回该对象的哈希码值。支持此方法是为了提高哈希表(例如 java.util.Hashtable 提供的哈希表)的性能。
如果根据 equals(Object) 方法,两个对象是相等的,那么对这两个对象中的每个对象调用 hashCode 方法都必须生成相同的整数结果。
如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么对这两个对象中的任一对象上调用 hashCode 方法不 要求一定生成不同的整数结果。但是,程序员应该意识到,为不相等的对象生成不同整数结果可以提高哈希表的性能。
——摘自API,大家也就理解了 为什么eclipse中 equals和HasdCode方法给我们的快捷键中,必须一起重写。
Object 类的 toString 方法返回一个字符串,该字符串由类名(对象是该类的一个实例)、at 标记符“@”和
此对象哈希码的无符号十六进制表示组成。换句话说,该方法返回一个字符串,它的值等于
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
以上是JDK默认toString方法的实现和API解释,可见Object类默认的toString方法和equals方法都和对象的哈希码有关
重写toString方法可以让我们更直观的理解对象的内容属性。
反射可以拿到一个对象的成员变量的值,但方法的参数是出现在方法被调用的时候,
你拿到了class,method,参数类型等这些都没用,这些都是静态的,固定的。
也就是说反射拿不到参数的值
String StringBuffer和StringBuilder
StringBuffer代表可变的字符序列,往StringBuffer字符串加东西,直接相加。
String代表不可变字符序列 当我们执行两个字符串相加时 需要分配另外一块内存 然后 执行两次copy。最后把字符串的指针执行新的那块内存。
StringBuilder和StringBuffer类似 区别是StringBuilder线程非安全。
HashMap为什么是线程不安全的
1.首先我们解释下HashMap的扩容:当HashMap的元素个数超过:数组长度乘以负载因子DEFAULT_LOAD_FACTOR(16*0.75)=12时,就会把数组长度扩大为16X2=32
将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。
这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
这个值只可能在两个地方,一个是原下标的位置,另一种是在下标为<原下标+原容量>的位置(JDK1.7重新计算Hash值 1.8巧妙的采用了位运算)
2.重新调整HashMap大小存在什么问题吗?
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。
在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。
如果条件竞争发生了,那么就死循环了。(多线程的环境下不使用HashMap)
推荐简述:https://www.jianshu.com/p/ecd75ea6ee5a HashMap多线程下死循环的问题
关于死循环的问题,在Java8中个人认为是不存在了,在Java8之前的版本中之所以出现死循环是因为在resize的过程中对链表进行了倒序处理;在Java8中不再倒序处理,自然也不会出现死循环。