一:分组原理(HashPartitioner)
/** Partition keys by their {@link Object#hashCode()}. */ @InterfaceAudience.Public @InterfaceStability.Stable public class HashPartitioner<K, V> extends Partitioner<K, V> { /** Use {@link Object#hashCode()} to partition. */ public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }
传入key和value,获取一个组号:
(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
默认numReduceTasks为1,求余数之后为0,所以对于所有的key都只会有一个组号。不会对数据进行分组操作。比如上篇文章中的数据,可以全部由一个reduce处理。
二:对流量实现自定义分组(按照省份)
(一)实验目标
对流量原始日志进行流量统计,将不同省份的用户统计结果输出到不同文件中
(二)实现思路---自定义改造两个机制
1.自定义一个partitioner,改造分区的逻辑。
2.自定义reducer task的并发任务数
(三)对于我们设置的分组,我们应该设置大于等于分组数的Reduce数量才对
三:代码实现
(一)自定义数据结构


package cn.hadoop.dg; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class FlowBean implements WritableComparable<FlowBean> { private String phoneNB; private long up_flow; private long down_flow; private long sum_flow; public FlowBean() {} //无参构造函数,用于反序列化时使用 public FlowBean(String phoneNB, long up_flow, long down_flow) { this.phoneNB = phoneNB; this.up_flow = up_flow; this.down_flow = down_flow; this.sum_flow = up_flow + down_flow; } public String getPhoneNB() { return phoneNB; } public void setPhoneNB(String phoneNB) { this.phoneNB = phoneNB; } public long getUp_flow() { return up_flow; } public void setUp_flow(long up_flow) { this.up_flow = up_flow; } public long getDown_flow() { return down_flow; } public void setDown_flow(long down_flow) { this.down_flow = down_flow; } public long getSum_flow() { return up_flow + down_flow; } //用于序列化 @Override public void write(DataOutput out) throws IOException { // TODO Auto-generated method stub out.writeUTF(phoneNB); out.writeLong(up_flow); out.writeLong(down_flow); out.writeLong(up_flow+down_flow); } //用于反序列化 @Override public void readFields(DataInput in) throws IOException { // TODO Auto-generated method stub phoneNB = in.readUTF(); up_flow = in.readLong(); down_flow = in.readLong(); sum_flow = in.readLong(); } @Override public int compareTo(FlowBean o) { return sum_flow > o.sum_flow ? -1 : 1; //返回值为-1,则排在前面 } @Override public String toString() { return "" + up_flow + " " + down_flow + " "+ sum_flow; } }
(二)自定义分组
package cn.hadoop.dg; import java.util.HashMap; import org.apache.hadoop.mapreduce.Partitioner; public class CustomPartitioner<KEY, VALUE> extends Partitioner<KEY, VALUE>{ private static HashMap<String, Integer> areaMap = new HashMap<>(); static { //向手机号归属地字典中插入数据 areaMap.put("135", 0); areaMap.put("136", 1); areaMap.put("137", 2); areaMap.put("138", 3); areaMap.put("139", 4); //对于其他13x开头的手机分组value值为5 } @Override public int getPartition(KEY key, VALUE value, int numPartitions) { //从key中拿取手机号,查询手机归属地字典 //传入的key是手机号 int areaGroupId = areaMap.get(key.toString().substring(0, 3))==null?5:areaMap.get(key.toString().substring(0, 3)); return areaGroupId; } }
(三)Map程序实现
package cn.hadoop.dg; import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class FlowGroupMapper extends Mapper<LongWritable, Text, Text, FlowBean>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException { //先获取一行数据 String line = value.toString(); //进行文本切分 String[] fields = StringUtils.split(line, " "); //获取我们需要的数据 String phoneNB = fields[1]; long up_flow = Long.parseLong(fields[7]); long down_flow = Long.parseLong(fields[8]); //封装数据为KV并输出 context.write(new Text(phoneNB), new FlowBean(phoneNB,up_flow,down_flow)); } }
(四)Reduce程序实现
package cn.hadoop.dg; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FlowGroupReducer extends Reducer<Text, FlowBean, Text, FlowBean>{ @Override protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) throws IOException, InterruptedException { long up_flow_c = 0; long down_flow_c = 0; for(FlowBean bean: values) { up_flow_c += bean.getUp_flow(); down_flow_c += bean.getDown_flow(); } context.write(key, new FlowBean(key.toString(),up_flow_c,down_flow_c)); } }
(五)主函数实现
package cn.hadoop.dg; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import cn.hadoop.dg.FlowGroupMapper; import cn.hadoop.dg.FlowGroupReducer; public class FlowGroupRunner { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FlowGroupRunner.class); job.setMapperClass(FlowGroupMapper.class); job.setReducerClass(FlowGroupReducer.class); //设置我们自定义的分组逻辑 job.setPartitionerClass(CustomPartitioner.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //设置对应分组的reduce task数量 job.setNumReduceTasks(6); //设置reduce task并发数 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1); } }
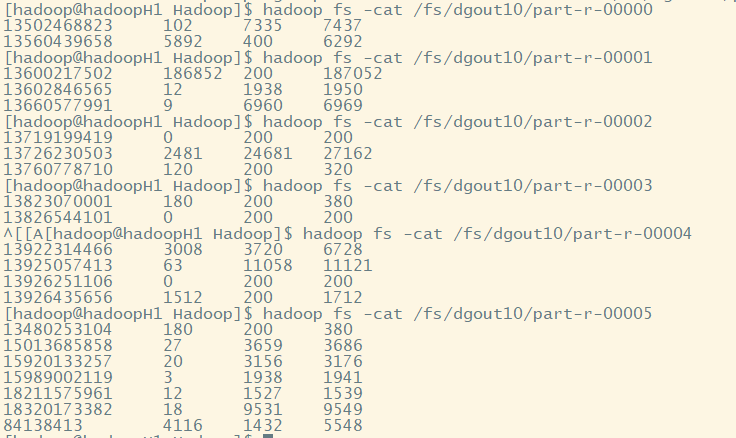
(六)结果查看
存在启动多个reduce程序的情况
hadoop jar dg.jar cn.hadoop.dg.FlowGroupRunner /fs/input /fs/dgout10

已实现分组: