集成开发环境:Pycharm
python版本:2.7(anaconda库)
用到的库:科学计算库numpy,数据分析包pandas,画图包matplotlib,机器学习库sklearn
大体步骤分为三步:
1.数据分析
2.交叉验证
3.预测并输出结果
导入库函数
import numpy as np import pandas as pa import matplotlib.pyplot as pl from sklearn.linear_model import LogisticRegression from sklearn import model_selection # 最后一个库是原来cross_validation的替代,原来那个过时了,再用会有警告,其实里边的函数都没变
第一步:数据分析
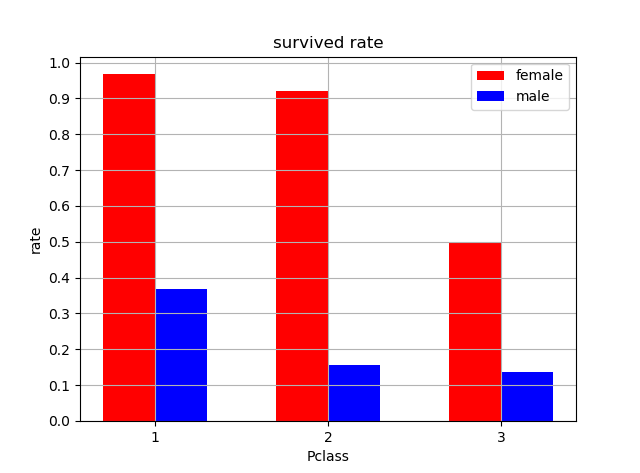
1.1通过画图分析出数据中对预测影响很小的特征值,忽略这些特征可以减小工作量
1 # pandas库里的read_csv可以把csv文件读取为dataFrame对象,这个对象就是很多列(数组)共享一个index,这个index 是真的存在的且可以指定,每一列都有name 2 # 其形状大小是真实数据的形状,不包括index和name 3 # 路径可以是绝对路径和相对路径,注意路径中的反斜线是两根,或者一根/ 4 train_obj = pa.read_csv('train.csv') 5 test_obj = pa.read_csv('test.csv') 6 7 # 首先把一看就知道对结果没有影响的数据去掉 8 # DataFrame对象的drop方法:删除行或者列,可以多行,drop('行名或者列名',axis=0/1(0是行,1是列)),多个行名或者列名:['',''] 9 trainData = train_obj.drop(['Name', 'Ticket', 'Cabin'], axis=1) 10 testData = test_obj.drop(['Name', 'Ticket', 'Cabin'], axis=1) 11 12 # 下面用画图的形式对其他变量对最后结果的影响作出判断: 13 # 首先考察船舱和性别,用groupby函数对的数据进行分类,groupby('列名'),根据给出的列,把具有相同数值的合为一组,组数为列值的种数 14 # 如果groupby(['列名1','列名2']),则列1为分大类,大类中再根据列2进行分类 15 train_group1 = trainData.groupby(['Sex', 'Pclass']) # 返回类型是Groupby类型,里边有key1*key2组 16 # sum()是将各组内每个特征的所有数据相加,返回也是key1*key2组,只不过每组里只有一行数据,是所有数据之和 17 # count()是统计各组每个特征的数据量(由于有缺失数据,所以各个特征间是不一定一样的) 18 rate = (train_group1.sum() / train_group1.count())['Survived'] # 有6组,每组都只有一个值,生存率 19 20 # 下面开始画图,柱状图 21 x = np.array([1, 2, 3]) 22 wi = 0.15 23 # bar(left,height,width,color)用来化柱状图,参数分别是每个柱子的中心位置坐标,高度(一般就是数据),宽度,颜色,前三个一般都是集合 24 pl.bar(x-wi, rate.female, wi*2, color='r') 25 pl.bar(x+wi, rate.male, wi*2, color='b') 26 pl.title("survived rate") 27 # 坐标轴名称 28 pl.xlabel("Pclass") 29 pl.ylabel("rate") 30 # 指定网格线格式 31 pl.grid(True, linestyle='-', color='0.7') 32 # 轴的刻度 33 pl.xticks([1, 2, 3]) 34 # arange(起点,终点,间隔),创建一个等差序列 35 pl.yticks(np.arange(0.0, 1.1, 0.1)) 36 # 对不同的柱做标记 37 pl.legend(['female', 'male']) 38 pl.show() 39 # 接下来的过程和上边差不多,分别是判断了年龄、上船地点、船上亲属人数
分析性别和上船地点的结果,结果显示两个特征的影响都需要保留
1.2数据预处理,将特征中比较相似的直接相加作为一个,非数值类型转为数值类型,对缺失值进行处理
1 # 船上的亲属人数就是把两个代表家属的变量相加 2 trainData['family'] = trainData['SibSp'] + trainData['Parch'] 3 # pandas中的map()函数一般是用来进行数据转换的,参数是函数或者字典,一个series调用map(),会对照字典用的key,将series中的key全部改成相应的value,map()函数返回一个新的,对源对象不操作 4 trainData['Sex'] = trainData['Sex'].map({'female': 0, 'male': 1}) 5 trainData['Embarked'] = trainData['Embarked'].map({'C': 0, 'Q': 1, 'S': 2}) 6 # numpy.isnan()函数的作用是返回一个Boolean数组,对应input的下标,若当前位置是nan那么就是true,否则false 7 # 对一个数组挑选时可以用array[True,False,True...]True就是选择 8 # 挑选出age为nan的,这个集合不用age这个特征,做四特征预测 9 train_age_nan = trainData[np.isnan(trainData['Age'])] 10 # 挑选出age不为空的数据,直接调用dropna(),这个方法会去掉输入数组中有nan特征的数据,挑选后的具备所有特征,所以可以用所有特征 11 train_all = trainData.dropna() 12 # 对于以上两个数据集分别挑选出需要的特征组成训练集,因为之前已经确认了有的是对结果没有影响的,所以可以只挑选有用的 13 # dataframe选取列的格式是两个方括号,[['列名','列名']] 14 train_five = train_all[['Sex', 'Embarked', 'family', 'Age', 'Pclass']] 15 train_four = train_age_nan[['Sex', 'Embarked', 'family', 'Pclass']] 16 17 # 两个数据集的标记数组 18 train_five_label = train_all['Survived'] 19 train_four_label = train_age_nan['Survived'] 20 21 # 至此处理数据工作全部完成,接下来就是训练模型
2.交叉验证
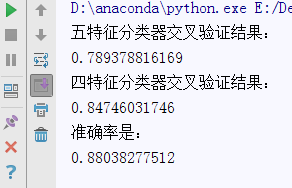
1 # 使用分类器类 2 classifier = LogisticRegression(C=10000) # 这个作为5特征分类器,这里的c是正则化系数,防止系统由于过于复杂而产生过拟合 3 # 调用cross_validation.cross_val_score(分类器,data,target,cv),这个函数返回每次交叉验证的准确率,方法是StratifiedKFold,具体看http://blog.sina.com.cn/s/blog_6a90ae320101a5rc.html 4 # 函数返回一个数组 5 score = model_selection.cross_val_score(classifier, train_five, train_five_label, cv=5) # 交叉验证 6 classifier2 = LogisticRegression() # 这个作为4特征分类器 7 score2 = model_selection.cross_val_score(classifier2, train_four, train_four_label, cv=5) # 交叉验证 8 # 查看平均值 9 print "五特征分类器交叉验证结果:" 10 print score.mean() 11 print "四特征分类器交叉验证结果:" 12 print score2.mean()
3.输出结果
1 # 下面开始输出结果 2 3 # 首先处理测试集 4 testData['Sex'] = testData['Sex'].map({'female': 0, 'male': 1}) 5 testData['Embarked'] = testData['Embarked'].map({'C': -1, 'Q': 0, 'S': 1}) 6 testData['family'] = testData['SibSp'] + testData['Parch'] 7 # 这里不能用两个数据集,因为如果将数据分开分别判断,那么无法和乘客号对应 8 # 读取官方结果 9 answer = pa.read_csv('gender_submission.csv') 10 11 # 训练分类器 12 classifier.fit(train_five, train_five_label) 13 classifier2.fit(train_four, train_four_label) 14 15 # 输出测试集结果 16 passengers = pa.DataFrame(testData['PassengerId']) 17 # 这里必须先创建一个列,直接赋值会出错 18 passengers['Survived'] = '' 19 # isnan()是numpy库里的函数 20 #这里有个问题就是如果直接对passengers['Survived'][i]每行赋值的话会有SettingCopyWarning警告,正确的方法是先生成一个数组temp,然后把数组赋值给列,直接添加会有警告 21 #这里创建数组不能用np.zeros(),因为用zeros生成的是float数组,最后结果要求int类型 22 temp = [0] * passengers.shape[0] 23 for i in range(len(testData)): 24 if np.isnan(testData['Age'][i]): 25 # 这里也有一个问题:由于需要一个一个做预测,但是predict函数要求输入二维数组,单行数据是一维的 26 #所以要把数据转为numpy中的array,然后转为二维数组 27 #reshape()函数可以利用原数组数据改变数组的尺寸,但是主要新旧数组数据量相同,而reshape(1,-1)可以将[xxx]转为[[xxx]]这种,就可以用了 28 temp[i] = int(classifier2.predict(np.array( testData[['Pclass', 'Sex', 'Embarked', 'family']].ix[i].dropna()).reshape(1,-1))) 29 else: 30 temp[i] = int(classifier.predict(np.array(testData[['Sex', 'Embarked', 'family', 'Age', 'Pclass']].ix[i]).reshape(1,-1))) 31 print temp 32 passengers['Survived'] = temp 33 # 结算准确率 34 acc = 1 - float(sum(abs(answer['Survived'] - passengers['Survived']))) / len(passengers) 35 print "准确率是:" 36 print acc 37 # 输出文件 38 passengers.to_csv('result.csv',encoding='utf-8',index=False)
最后的结果,准确率有点低,再找找原因