希尔排序:
希尔排序(shell_sort)
希尔排序是一种分组插入排序算法。
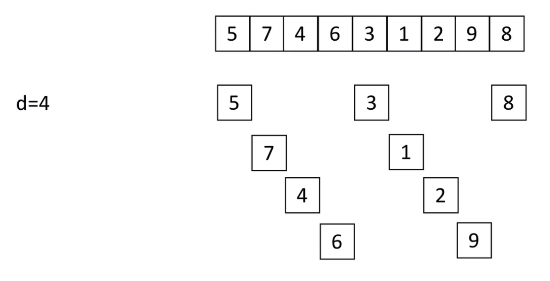
首先取一个整数d1=n//2,将元素分为d1个组,每组相邻元素之间距离是d1,在各组内进行直接插入排序
取二个整数d2=d1//2,重复上述分组排序过程,直到di=1,即所有元素在同一组内进行直接插入排序
希尔排序每趟并不使某些元素有序,而是使整体数据越来越接近有序;最后一趟使所有数据有序
希尔排序的时间复杂度取决于gap序列的形式,gap序列不同,时间复杂度就不同。
以下实现的gap序列为:n,n//2,n//4,...,1 时间比堆排序慢,但是比lowb三人组快多了
import random li = list(range(10)) random.shuffle(li) def insert_sort_gap(li, gap): # 插入排序把1改为gap for i in range(gap, len(li)): j = i - gap tmp = li[i] while j >= 0 and tmp < li[j]: li[j + gap] = li[j] j -= gap li[j + gap] = tmp def shell_sort(li): d = len(li) // 2 while d >= 1: insert_sort_gap(li, d) d //= 2 print(li) shell_sort(li) print(li)
计数排序:
计数排序:
对列表进行排序,已知列表中的数范围都在0-100之间。设计时间复杂度为O(n)的算法
就是统计每个数字出现的次数,例如对年龄排序。
使用计数排序必须要知道列表中所有可能出现的情况
优缺点:优点是时间复杂度为O(n)。缺点是1,必须知道范围2,空间复杂度为O(n)
def count_sort(li, max_count=100): # li的范围[0,99] count = [0 for _ in range(max_count + 1)] # [0,0,0,0,0...] for val in li: count[val] += 1 li.clear() for ind, val in enumerate(count): for i in range(val): li.append(ind)
桶排序

桶排序使用的情况不多。
桶排序的效率取决于数据的分布是否均匀。如果99%的数都在一个桶里,就需要改变分桶策略了
k表示平均每个桶的数据个数
平均时间复杂度:O(n+k)
最坏情况时间复杂度:O(n²k)
空间复杂度:O(nk)
def bucket_sort(li, n=100, max_num=10000): ''' 桶排序算法 :param li: :param n: 分成多少个桶 :param max_num: li的范围 :return: ''' buckets = [[] for _ in range(n)] # 创建桶 for val in li: i = min(val // (max_num // n), n - 1) # i表示val放到几号桶里 buckets[i].append(val) # 把val加到桶里 # 保持桶内顺序,用冒泡 for j in range(len(buckets[i]) - 1, 0, -1): if buckets[i][j] < buckets[i][j - 1]: buckets[i][j], buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j] else: break sorted_li = [] for buc in buckets: sorted_li.extend(buc) return sorted_li import random li = list(range(10)) random.shuffle(li) print(li) li = bucket_sort(li) print(li)
基数排序
与桶排序不同的是不在桶里进行排序
先按个位装桶,取出,再按十位装桶,取出...直到所有位数都处理完
装桶,取出,装桶,取出...直到所有位数都装完
k表示位数
时间复杂度:O(kn) 相当于O(nlog10n)比快排速度快
空间复杂度:O(k+n)
def radix_sort(li): max_num = max(li) # 最大值9->1 99->2 10000->5 it = 0 while 10 ** it <= max_num: buckets = [[] for _ in range(10)] # 分桶 for val in li: digit = (val // 10 ** it) % 10 buckets[digit].append(val) # 把数写回li li.clear() for buc in buckets: li.extend(buc) it += 1 import random li = list(range(10000)) random.shuffle(li) radix_sort(li) print(li)