数据结构:
线性结构,元素存在一对一的关系,例如列表
树结构,元素存在一对多的关系,例如层级结构
图结构,元素存在多对多的关系,例如地图
列表:
列表:
1、列表中的元素是怎么存储的?
是顺序存储的,是一块连续的内存
2、列表的操作:按下标查找,插入元素,删除元素
先说C中的数组:
查找的时间复杂度是O(1),因为知道首地址+每个元素的大小*index就找到了地址
数组与列表有两点不同:
1、数组元素类型要相同
2、数组长度固定
python中的列表如何实现?
Python中列表的类型可以不同
Python中的列表存放的不是值而是地址,32位机器一个地址占4个字节,地址的长度是固定的
列表长度不固定
Python解释器自动维护的,发现长度不够会新开辟一块内存,把之前的列表进行拷贝
python下标查找和append复杂度是O(1)
python列表的插入和删除的复杂度是O(n)
栈:
栈(stack)是一个数据集合,可以理解为只能在一端进行插入或删除操作的列表
栈的特点:LIFO
栈的概念:栈顶,栈底
栈的基本操作:(用列表可以实现)
进栈:li.append
出栈: li.pop()
取栈顶: li[-1]
class Stack(object):
def __init__(self):
self.stack = []
def pop(self):
return self.stack.pop()
def push(self, element):
return self.stack.append(element)
def get_top(self):
if self.stack:
return self.stack[-1]
else:
return None
栈的应用:括号匹配问题 '{[()[]{}]}'遇到左括号就入栈,遇到右括号就看栈顶的左括号,把匹配的左括号出栈,匹配完后栈为空说明匹配。
队列:
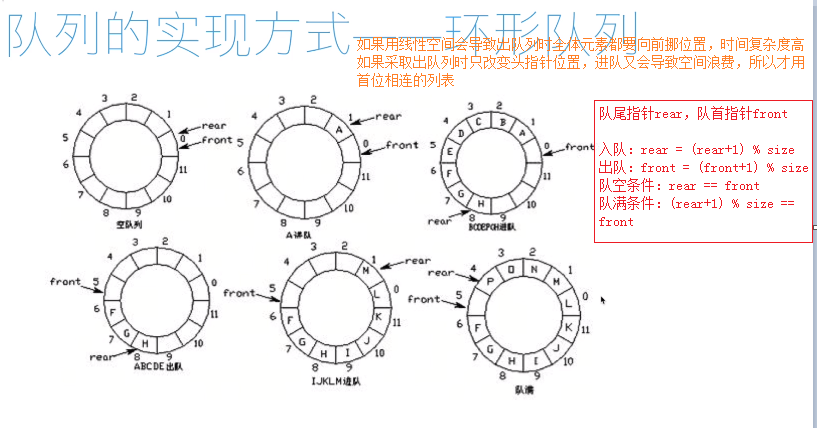
队列的实现:


class Queue: def __init__(self, size=100): self.queue = [0 for _ in range(size)] self.size = size self.rear = 0 self.front = 0 def push(self, element): if self.is_filled(): raise IndexError("Queue is filled.") self.rear = (self.rear + 1) % self.size self.queue[self.rear] = element def pop(self): if self.is_empty(): raise IndexError("Queue is empty.") self.front = (self.front + 1) % self.size return self.queue[self.front] def is_empty(self): return self.rear == self.front def is_filled(self): return (self.rear + 1) % self.size == self.front q = Queue(5) for i in range(4): q.push(i) print(q.is_filled())
Python队列内置模块
python中有线程queue,进程queue,这里是普通的双向queue
使用方法:from collections import deque
创建队列:q = deque([1, 2, 3], maxlen=5)
进队:append()
出队:popleft()
队首进队:appendleft()
队尾出队:pop()
栈和队列的应用:迷宫问题
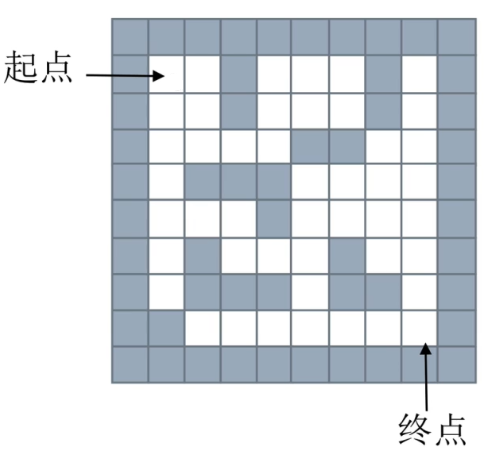
# 用栈实现迷宫问题:找到的不一定是最短路径
# 深度优先搜索,又叫回溯法
# 栈里存放走的路径,先选一个方向,走一步,入栈,再选方向,走一步,入栈....,当前所在位置就是栈顶的值
# 如果某一步走不通,退一步,出栈,再换方向走,循环,直到到达终点
# 用栈实现迷宫问题: # 深度优先搜索,又叫回溯法 # 栈里存放走的路径,先选一个方向,走一步,入栈,再选方向,走一步,入栈....,当前所在位置就是栈顶的值 # 如果某一步走不通,退一步,出栈,再换方向走,循环,直到到达终点 maze = [ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 1, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 0, 0, 0, 1], [1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 1, 0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 1, 1, 0, 1], [1, 1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], ] # 四个方向的坐标 dirs = [ lambda x, y: (x + 1, y), lambda x, y: (x - 1, y), lambda x, y: (x, y - 1), lambda x, y: (x, y + 1), ] def maze_path(x1, y1, x2, y2): stack = [] stack.append((x1, y1)) while (len(stack) > 0): curNode = stack[-1] if curNode[0] == x2 and curNode[1] == y2: # 走到终点了 print(stack) return # 四个方向,随便选一个能走通的路走,走过的标记为2,下次不走 for dir in dirs: nextNode = dir(curNode[0], curNode[1]) # 如果下个节点能走 if maze[nextNode[0]][nextNode[1]] == 0: stack.append(nextNode) maze[nextNode[0]][nextNode[1]] = 2 break else: stack.pop() else: print('没有路') maze_path(1, 1, 8, 8)
# 使用队列实现迷宫问题,广度优先搜索,找到的一定是最短路径
# 使用队列存储当前正在考虑的节点

# 为了计算路径,还需要用一个列表来保存“哪个点让这个点进队列的”
maze = [ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 1, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 0, 0, 0, 1], [1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 1, 0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 1, 1, 0, 1], [1, 1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], ] # 四个方向的坐标 dirs = [ lambda x, y: (x + 1, y), lambda x, y: (x - 1, y), lambda x, y: (x, y - 1), lambda x, y: (x, y + 1), ] from collections import deque def print_path(path): ''' 打印路径 ''' curNode = path[-1] realpath = [] while curNode[2] != -1: realpath.append(curNode[0:2]) curNode = path[curNode[2]] realpath.append(curNode[0:2]) # 起点 realpath.reverse() print(realpath) def maze_path_queue(x1, y1, x2, y2): queue = deque() queue.append((x1, y1, -1)) # 第三个数表示谁引发它进队列的,存path中的下标 path = [] while len(queue) > 0: curNode = queue.popleft() path.append(curNode) # 出队列的放入path,用于计算路径 if curNode[0] == x2 and curNode[1] == y2: # 走到终点了 print_path(path) return for dir in dirs: nextNode = dir(curNode[0], curNode[1]) if maze[nextNode[0]][nextNode[1]] == 0: queue.append((nextNode[0], nextNode[1], len(path) - 1)) # path中最后一个元素就是引发它进队列的点 maze[nextNode[0]][nextNode[1]] = 2 else: print("没有路") maze_path_queue(1, 1, 8, 8)
栈和队列的应用 :广度优先和深度优先遍历文件夹
import os def bfs_scan(dir): """广度优先""" queue = [] # 先进先出:queue.append() queue.pop(0) queue.append(dir) while len(queue) > 0: tmp = queue.pop(0) if os.path.isdir(tmp): for f in os.listdir(tmp): abs_path = os.path.join(tmp, f) if os.path.isdir(abs_path): queue.append(abs_path) else: print("找到文件>>", abs_path) else: print("找到文件>>", tmp) if __name__ == '__main__': dir = "C:\Users\Administrator\Desktop\test" bfs_scan(dir)
import os def dfs_scan(dir): """深度优先""" stack = [] # 后进先出:queue.append() queue.pop() stack.append(dir) while len(stack) > 0: tmp = stack.pop() if os.path.isdir(tmp): for f in os.listdir(tmp): abs_path = os.path.join(tmp, f) if os.path.isdir(abs_path): stack.append(abs_path) else: print("找到文件>>", abs_path) else: print("找到文件>>", tmp) if __name__ == '__main__': dir = "C:\Users\Administrator\Desktop\test" dfs_scan(dir)
链表:
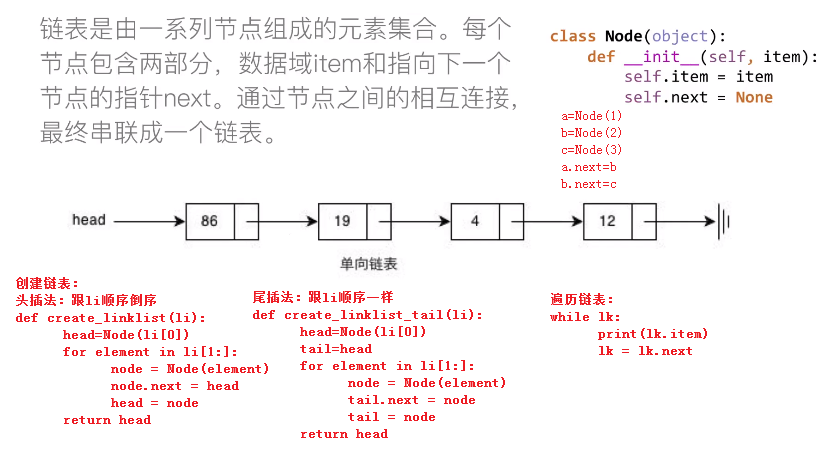
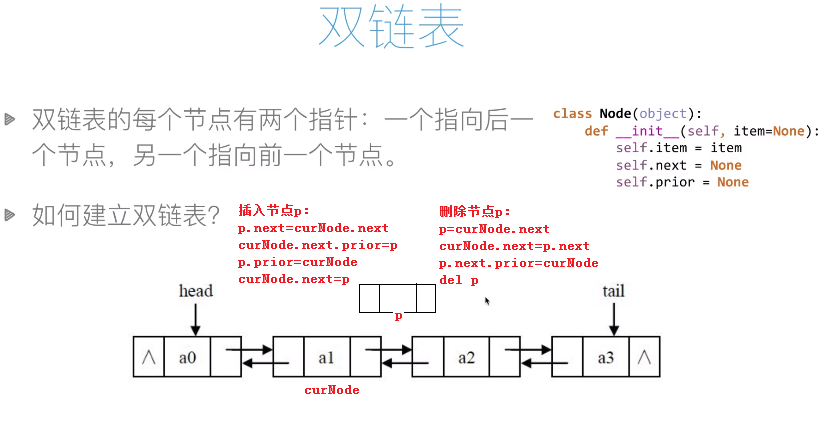
顺序表与链表时间复杂度对比:
按元素值查找:O(n)
按下标查找:O(1) O(n)
在某元素后插入:O(n) O(1)
删除某元素:O(n) O(1)
总结:
1.链表在插入和删除的操作上明显快于顺序表
2.链表的内存可以更灵活的分配
3.可以实现堆和栈
哈希表
哈希表:
哈希表通过哈希函数来计算数据存储位置的数据结构,通常支持如下操作
insert:插入键值对
get:如果存在键为key的返回其value,否则返回空
delete:删除为key的键值对
直接寻址表:
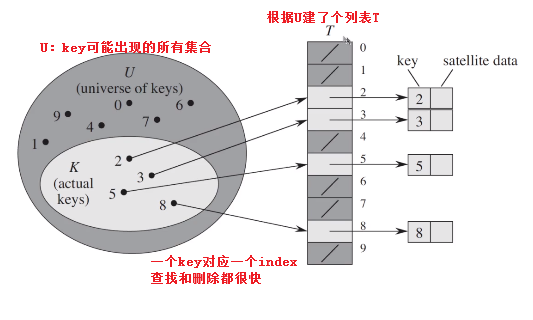
直接寻址技术缺点:
域U很大时,需要消耗大量内存,不实际
域U很大而实际出现的key很少,则大量空间被浪费
无法处理关键字不是数字的情况
直接寻址表:key=k的元素放在列表的k位置
直接寻址表改为哈希表:
1、构建大小为m的寻址表T
2、key=k的元素放到h(k)位置上
3、h(k)是一个函数,作用是将域U映射到表T[0,1,2,...,m-1]
哈希表
哈希表又称散列表,是一种线性表的存储结构。哈希表由一个
直接寻址表和一个哈希函数组成。哈希函数h(k)将元素关键字作为自变量,
返回元素的存储下标。
假设有一个长度为7的哈希表,哈希函数h(k)=k%7,元素集合
{14,22,3,5}的存储方式如下图:

哈希冲突:
由于哈希表的大小是有限的,而要存储的值的总数量是无限的,
因此对于任何哈希函数,都会出现两个不同元素映射到同一个位置上的情况,
这种情况叫做哈希冲突.
比如h(k)=k%7, h(0)=h(7)=h(14)=...
解决hash冲突的两种方式:
一、开放寻址法:如果哈希函数返回的位置已经有值,则可以向后探查新的位置来存储这个值。
线性探查:如果位置i被占用,则探查i+1,i+2,...查找的时候,也要进行线性探查
二次探查:如果位置i被占用,则探查i+1²,i-1²,i+2²,i-2²,...
二度哈希:有n个哈希函数,当使用第1个哈希函数h1发生冲突时,则尝试使用h2,h3...
这个方式大家不太喜欢,有可能hash表满了,就肯定没空间了
二、拉链法
哈希表每个位置都连接一个链表,当冲突发生时,冲突的元素将被加到该位置链表的最后。
查找的时候,先找到hash函数计算的位置,再在链表里找
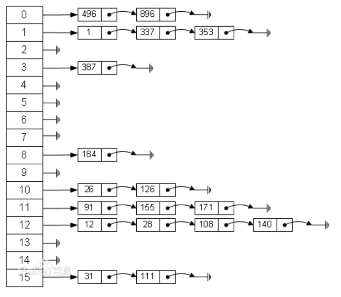
常见的哈希函数:

class LinkList: class Node: def __init__(self, item=None): self.item = item self.next = None class LinkListIterator: def __init__(self, node): self.node = node def __next__(self): if self.node: cur_node = self.node self.node = cur_node.next return cur_node.item else: raise StopIteration def __iter__(self): return self def __init__(self, iterable=None): self.head = None self.tail = None if iterable: self.extend(iterable) def append(self, obj): s = LinkList.Node(obj) if not self.head: self.head = s self.tail = s else: self.tail.next = s self.tail = s def extend(self, iterable): for obj in iterable: self.append(obj) def find(self, obj): for n in self: if n == obj: return True return False def __iter__(self): return self.LinkListIterator(self.head) def __repr__(self): return "<<" + ", ".join(map(str, self)) + ">>" # 类似于集合的结构 class HashTable: def __init__(self, size=101): self.size = size self.T = [LinkList() for _ in range(self.size)] def h(self, k): ''' hash函数 ''' return k % self.size def insert(self, k): i = self.h(k) if self.find(k): print('Duplicated Insert') else: self.T[i].append(k) def find(self, k): i = self.h(k) return self.T[i].find(k) def __repr__(self): return ",".join(map(str, self.T)) ht = HashTable() ht.insert(0) ht.insert(1) ht.insert(0) ht.insert(202) print(ht) print(ht.find(202))



23223