使用go关键字启动一个goroutine
程序员唯一需要做的,是把任务封装成一个函数
程序启动之后会创建一个主goroutine去执行(main也是一个goroutine)
package main
import("fmt""sync")//开启goroutine将0~20的数发送到ch1中
//开启goroutine从ch1中接收值,将该值的平方发送到ch2中,最后把ch2中的所有值打印出来
var wg sync.WaitGroup
var once sync.Once
func f(ch1, ch2 chan int) {wg.Done()for n := range ch1 {ch2 <- n * n}once.Do(func(){ close(ch2) })// close(ch2) //报错 ,一个goroutine关闭,另一个再关闭就会报错}
func main() {var ch1 chan int = make(chan int, 100)var ch2 chan int = make(chan int, 100)
// wg.Add(1) //这里没必要加,因为下面这个goroutine不会阻塞go func(ch chan int) {for i:=0;i<20;i++{ch1 <- i}close(ch1) // 放完之后必须要关闭(这样接收端就知道我接收完就退出),不关闭接收端不知道该阻塞还是该退出}(ch1)wg.Add(2)go f(ch1, ch2)go f(ch1, ch2)
wg.Wait()
for i := range ch2 {fmt.Println(i)}}
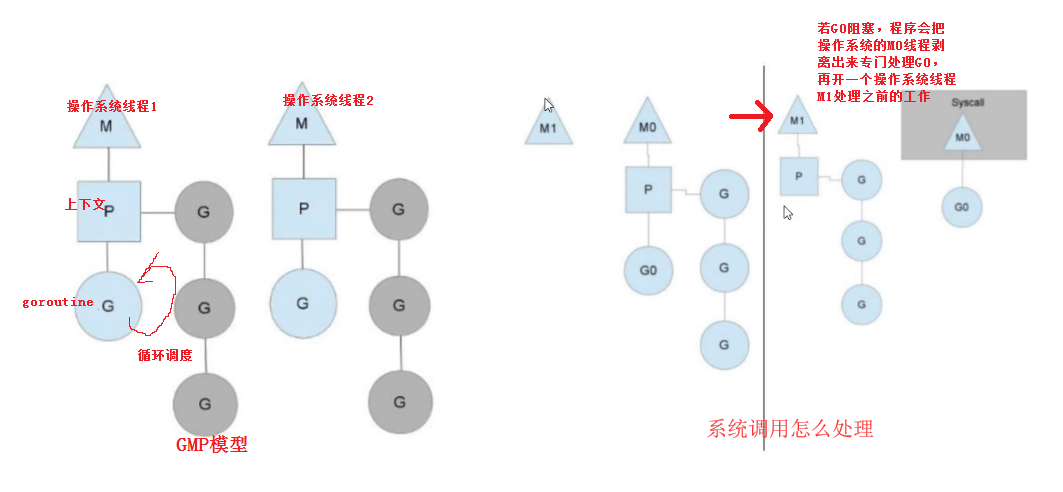
goroutine调度模型 GMP
1、m:n 把m个goroutine分配给n个操作系统线程去执行
2、goroutine初始栈的大小是2k
3、runtime.GOMAXPROCS(1) 可以修改n的值
现实中并发的目的是执行任务
比如第一种任务,每个任务的执行都依赖上一个任务的结果,这种并发是没有意义的
任务链:f1() -> f2() - > f3()
比如第二种任务,某个任务的执行依赖多个任务的结果,这多个任务可以并发执行
任务链:f1()|f2()|f3() -> f4()
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言的并发模型是CSP(Communicating Sequential Processes)
提倡通过通信共享内存而不是通过共享内存而实现通信,就是使用chanel实现通信,而不是用全局变量通信。
Goroutine使用陷阱

产生原因:
1. range自带的坑:不管循环多少次,v是同一块地址,每次循环变的是v指向的值
2. 而func (p *Person) SayName()表明传的是地址,那根据第1点,循环三次都传的同一个地址
3.循环执行太快,执行完成后,地址都指向值:{name: "alex3"}
改进1:循环时,让range判断出要传v的值
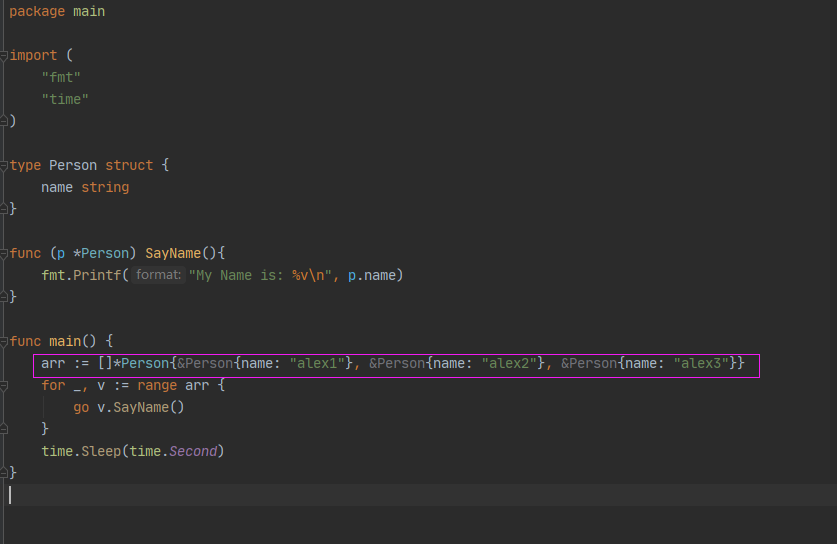
改进2: 把struct当成值类型来使用

无缓冲的通道 VS 有缓冲的通道(重要)
c1:=make(chan int) //无缓冲
c2:=make(chan int,1) //有缓冲
无缓冲的通道:发送 goroutine 和接收 goroutine 同时准备好,才能完成发送和接收操作。
比方说:如果 发送方goroutine向 c1 <- 1, 除非接收方goroutine执行<-c1 接手了 这个参数,那么c1<- 1才会继续下去,否则就一直阻塞,想不阻塞也是有方法的,加select {case c1<-1: ..default: }
------应用场景:通知消息,接收端先准备好,发送端一发出通知,接收端就开始运行
有缓冲的通道:发送goroutine不阻塞,把缓冲区放满之后才阻塞。
通道chan的使用
var b chan int //声明管道
b = make(chan int) //给管道开辟空间,无缓冲
b = make(chan int, 5) //带缓冲的通道,可预存5个值,存满后再放就阻塞
b <- 2 //给通道放值
var n int; n = <- b //从通道取值,方式一
n := <-b // 从通道取值,方式二
<- b //取出值扔掉
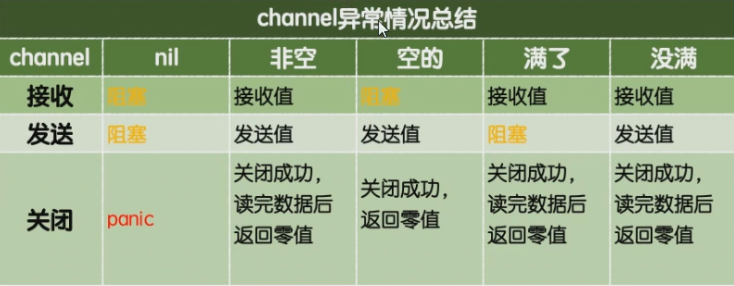
close(b) //关闭通道,关闭分为两端,读的一端和写的一端。例如: f1函数写,f1里面close,表示不能向管道里写了,但是能读。 f2函数读,f2里面close,表示不能从f2里面读了,但是能向f2里面写。
在运行中,确定不用了,要手动关闭通道。不关闭很容易造成deadlock。。如果不关闭通道,v, ok := < ch 中的ok一直不为false,造成死锁
waitGroup可能导致死锁,调试时可以先不加WaitGroup
for i:= range b {
fmt.Println(i) //从通道里循环取值
}
通道里内存占用小的值直接扔通道里,内存占用大的值扔指针或者包装成结构体,扔结构体的指针
通道的关闭方式(重要)
1-N N-1 M-N(生产者-消费者)
在N的那一端可以使用sys.Once(func(){ close(chanel) }) 来关闭
1-N:关闭生产者
生产者执行close(chanel)
N-1:关闭消费者
每个生产者都用select监听一个无缓冲通道,当无缓冲通道有反应就结束goroutine。当消费者执行close(无缓冲通道)时,生产者端产生反应,结束goroutine
N-N:不定
结合具体应用场景,sys.Once 和 无缓冲通道 结合使用
单向通道
多用在函数的参数中。
对通道来说是可存可取的,但在某个函数里,如果只想在该函数内存或者取,就应使用单通道
ch1 <-chan int 只能取
ch2 chan<- int 只能存
select多路复用
(使用场景:同时向通道里存和取, 如果取的goroutine挂了,会造成通道阻塞,可以在select中一个取,一个扔掉,如果通道满了就扔掉)
在某些场景下我们需要同时从多个通道接收数据。通道在接收数据时,如果没有数据可以接收将会发生阻塞。你也许会写出如下代码使用遍历的方式来实现:
for{
// 尝试从ch1接收值
data, ok := <-ch1
// 尝试从ch2接收值
data, ok := <-ch2
…
}
这种方式虽然可以实现从多个通道接收值的需求,但是运行性能会差很多。为了应对这种场景,Go内置了select关键字,可以同时响应多个通道的操作。
select的使用类似于switch语句,它有一系列case分支和一个默认的分支。每个case会对应一个通道的通信(接收或发送)过程。
select会一直等待,直到某个case的通信操作完成时,就会执行case分支对应的语句。具体格式如下:
select{
case <-ch1:
...
case data := <-ch2:
...
case ch3<-data:
...
default:
默认操作
}
举个小例子来演示下select的使用:
func main() {
ch := make(chan int, 1)
for i := 0; i < 10; i++ {
select {
case x := <-ch:
fmt.Println(x)
case ch <- i:
}
}
}
使用select语句能提高代码的可读性。
- 可处理一个或多个channel的发送/接收操作。
- 如果多个
case同时满足,select会随机选择一个。 - 对于没有
case的select{}会一直等待,可用于阻塞main函数。
sync包
并发执行全局变量n++的操作,分三步:第一步. 取出n 第二步. n+1 第三步. n写回去
假如多个goroutine都取出了50,都+1 ,赋值回去,就变成51,结果算少了。这时就需要加锁
//互斥锁Mutex(应用场景:全部或者大部分是写的场景)
保证同一时间只有一个goroutine访问公共资源
var lock sync.Mutex //Mutex是结构体。而结构体是值类型,所以Mutex作为参数一定要传指针,不然就是两把不同的锁,会出问题
lock.Lock(); // 加锁
x++;
lock.Unlock() // 释放锁
//读写互斥锁(应用场景:读的次数远远大于写的次数)
分读锁和写锁
若获取的是读锁,其他的还能继续读
若获取的是写锁,其他的必须等锁释放之后才能读或写
var rwLock sync.RWMutex
rwLock.Rlock() ; rwLockRUnlock() // 读锁 加锁和释放
rwLock.Lock() ; rwLock.Unlock() // 写锁 加锁和释放
sync.Once
为了保证并发安全,确保某个代码只执行一次
var once sync.Once
once.Do(func(){ close(ch2) }) //只关闭ch2通道1次
应用:并发安全的单例模式,不论多少个goroutine同时获取,都是同一个结构体指针
package singleton
import (
"sync"
)type singleton struct {}
var instance *singleton
var once sync.Oncefunc GetInstance() *singleton {
once.Do(func() {
instance = &singleton{}
})
return instance
}
sync.Map
Go语言中内置map不是并发安全的
Go提供了并发安全版的map,不用make初始化。
同时sync.Map内置了诸如Store、Load、LoadOrStore、Delete、Range等操作方法。
atomic包(原子操作,把变量自增等操作变成并发安全的)
之前想要并发安全的修改某个变量的值,需要:lock.Lock();n++;lock.Unlock(); 现在用原子操作一步就实现。
| 方法 | 解释 |
|---|---|
| func LoadInt32(addr *int32) (val int32) func LoadInt64(addr *int64) (val int64) func LoadUint32(addr *uint32) (val uint32) func LoadUint64(addr *uint64) (val uint64) func LoadUintptr(addr *uintptr) (val uintptr) func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer) |
读取操作 |
| func StoreInt32(addr *int32, val int32) func StoreInt64(addr *int64, val int64) func StoreUint32(addr *uint32, val uint32) func StoreUint64(addr *uint64, val uint64) func StoreUintptr(addr *uintptr, val uintptr) func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer) |
写入操作 |
| func AddInt32(addr *int32, delta int32) (new int32) func AddInt64(addr *int64, delta int64) (new int64) func AddUint32(addr *uint32, delta uint32) (new uint32) func AddUint64(addr *uint64, delta uint64) (new uint64) func AddUintptr(addr *uintptr, delta uintptr) (new uintptr) |
修改操作 |
| func SwapInt32(addr *int32, new int32) (old int32) func SwapInt64(addr *int64, new int64) (old int64) func SwapUint32(addr *uint32, new uint32) (old uint32) func SwapUint64(addr *uint64, new uint64) (old uint64) func SwapUintptr(addr *uintptr, new uintptr) (old uintptr) func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer) |
交换操作 |
| func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool) func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool) func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool) func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool) func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool) |
比较并交换操作 |