概要:利用python进行web数据抓取方法和实现。
1、python进行网页数据抓取有两种方式:一种是直接依据url链接来拼接使用get方法得到内容,一种是构建post请求改变对应参数来获得web返回的内容。
一、第一种方法通常用来获取静态页面内容,比如豆瓣电影内容分类下动画对应的链接:
http://www.douban.com/tag/%E5%8A%A8%E7%94%BB/?focus=movie
纪录片对应的链接:
http://www.douban.com/tag/%E7%BA%AA%E5%BD%95%E7%89%87/?focus=movie
tag 与 /?foucus中间的代表关键字,每次将页面对应的关键字进行替换就能抓取到相应的页面。
二、第二种方法是通过使用post请求来进行获取web内容抓取,由于许多网站是动态网站,每次请求返回的对应链接都是无变化,所以不能直接使用get方法来抓取网站内容,基本思路是只能依据每次发送的post数据请求观察其中的参数,并模拟构造post请求实现相应的页面获取。
2、python简易代码实现web抓取:
1 #coding=utf-8 2 3 import urllib,urllib2 4 5 #继续以抓取豆瓣电影分类链接为例 6 7 movie_list = ['%E7%BA%AA%E5%BD%95%E7%89%87','%E6%96%87%E8%89%BA','%E5%8F%B2%E8%AF%97'] 8 9 for i in movie_list: 10 url = http://www.douban.com/tag/%E5%8F%B2%E8%AF%97/?focus=movie 11 url = url.replace('%E5%8F%B2%E8%AF%97',i) 12 request = urllib2.Request(url) 13 html = urllib2.open(request)
3、使用phantomJS 模拟浏览器进行数据抓取
http://www.cnblogs.com/chenqingyang/p/3772673.html
这是我学习爬虫比较深入的一步了,大部分的网页抓取用urllib2都可以搞定,但是涉及到JavaScript的时候,urlopen就完全傻逼了,所以不得不用模拟浏览器,方法也有很多,此处我采用的是selenium2+phantomjs,原因在于:
selenium2支持所有主流的浏览器和phantomjs这些无界面的浏览器,我开始打算用Chrome,但是发现需要安装一个什么Chrome驱动,于是就弃用了,选择phantomjs,而且这个名字听起来也比较洋气。
上网查了很多资料,发现网上selenium2+phantomjs的使用方法的中文资源十分欠缺,不得不阅读晦涩的官方文档,所以这里记下目前已经实现的操作,再加上一些我个人遇到的问题以及对应的解决方案。
背景知识:
phantomjs是一个基于webkit的没有界面的浏览器,所以运行起来比完整的浏览器要高效。
selenium的英文原意是Se,化学元素,这里是一个测试web应用的工具,目前是2.42.1版本,和1版的区别在于2.0+中把WebDrive整合在了一起。
selenium2支持的Python版本:2.7, 3.2, 3.3 and 3.4
如果需要进行远程操作的话,就需要额外安装selenium server
安装:
先装selenium2,哪种方式装都可以,我一般都是直接下载压缩包,然后用python setup.py install命令来装,selenium 2.42.1的下载地址:https://pypi.python.org/pypi/selenium/2.42.1
然后下载phantomjs,https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-1.9.7-windows.zip,解压后可以看到一个phantomjs.exe的文件
范例1:

#coding=utf-8
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='C:\Users\Gentlyguitar\Desktop\phantomjs-1.9.7-windows\phantomjs.exe')
driver.get("http://duckduckgo.com/")
driver.find_element_by_id('search_form_input_homepage').send_keys("Nirvana")
driver.find_element_by_id("search_button_homepage").click()
print driver.current_url
driver.quit()
其中的executable_path就是刚才phantomjs.exe的路径,运行结果:
https://duckduckgo.com/?q=Nirvana
Walk through of the example:
值得一提的是:
get方法会一直等到页面被完全加载,然后才会继续程序
但是对于ajax: It’s worth noting that if your page uses a lot of AJAX on load then WebDriver may not know when it has completely loaded
send_keys就是填充input
范例2:
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver import ActionChains
import time
import sys
driver = webdriver.PhantomJS(executable_path='C:\Users\Gentlyguitar\Desktop\phantomjs-1.9.7-windows\phantomjs.exe')
driver.get("http://www.zhihu.com/#signin")
#driver.find_element_by_name('email').send_keys('your email')
driver.find_element_by_xpath('//input[@name="password"]').send_keys('your password')
#driver.find_element_by_xpath('//input[@name="password"]').send_keys(Keys.RETURN)
time.sleep(2)
driver.get_screenshot_as_file('show.png')
#driver.find_element_by_xpath('//button[@class="sign-button"]').click()
driver.find_element_by_xpath('//form[@class="zu-side-login-box"]').submit()
try:
dr=WebDriverWait(driver,5)
dr.until(lambda the_driver:the_driver.find_element_by_xpath('//a[@class="zu-top-nav-userinfo "]').is_displayed())
except:
print '登录失败'
sys.exit(0)
driver.get_screenshot_as_file('show.png')
#user=driver.find_element_by_class_name('zu-top-nav-userinfo ')
#webdriver.ActionChains(driver).move_to_element(user).perform() #移动鼠标到我的用户名
loadmore=driver.find_element_by_xpath('//a[@id="zh-load-more"]')
actions = ActionChains(driver)
actions.move_to_element(loadmore)
actions.click(loadmore)
actions.perform()
time.sleep(2)
driver.get_screenshot_as_file('show.png')
print driver.current_url
print driver.page_source
driver.quit()
这个程序完成的是,登陆知乎,然后能自动点击页面下方的“更多”,以载入更多的内容
Walk through of the example:
from selenium.webdriver.common.keys import Keys,keys这个类就是键盘上的键,文中的send_keys(Keys.RETURN)就是按一个回车
from selenium.webdriver.support.ui import WebDriverWait是为了后面一个等待的操作
from selenium.webdriver import ActionChains是导入一个动作的类,这句话的写法,我找了很久
find_element推荐使用Xpath的方法,原因在于:优雅、通用、易学
Xpath表达式写法教程:http://www.ruanyifeng.com/blog/2009/07/xpath_path_expressions.html
值得注意的是,避免选择value带有空格的属性,譬如class = "country name"这种,不然会报错,大概compound class之类的错
检查用户密码是否输入正确的方法就是在填入后截屏看看
想要截屏,这么一句话就行:
driver.get_screenshot_as_file('show.png')
但是,这里的截屏是不带滚动条的,就是给你把整个页面全部照下来
try:
dr=WebDriverWait(driver,5)
dr.until(lambda the_driver:the_driver.find_element_by_xpath('//a[@class="zu-top-nav-userinfo "]').is_displayed())
except:
print '登录失败'
sys.exit(0)
是用来通过检查某个元素是否被加载来检查是否登录成功,我认为当个黑盒子用就可以了。其中5的解释:5秒内每隔500毫秒扫描1次页面变化,直到指定的元素
对于表单的提交,即可以选择登录按钮然后使用click方法,也可以选择表单然后使用submit方法,后者能应付没有登录按钮的情况,所以推荐使用submit()
对于一次点击,既可以使用click(),也可以使用一连串的action来实现,如文中:
loadmore=driver.find_element_by_xpath('//a[@id="zh-load-more"]')
actions = ActionChains(driver)
actions.move_to_element(loadmore)
actions.click(loadmore)
actions.perform()
这5句话其实就相当于一句话,find element然后click,但是action的适用范围更广,譬如在这个例子中,要点击的是一个a标签对象,我不知道为什么直接用click不行,不起作用
print driver.current_url
print driver.page_source
即打印网页的两个属性:url和source
总结:除了能解决动态页面的问题以外,用selenium用来模拟登陆也比urllib2简单得多。
参考文献:
http://selenium-python.readthedocs.org/getting-started.html
http://www.cnblogs.com/paisen/p/3310067.html
4、使用代理防止抓取ip被封
实时动态抓取代理可用Ip,生成可用代理地址池
5、scrapy爬虫代理——利用crawlera神器,无需再寻找代理IP
由于工作需要,利用scrpay采集某个商业网站的数据。但是这个网站反扒非常厉害。因此不得不采用代理IP来做,但是做了几天后几乎能用的代理IP全被禁掉了。而且这种找代理、然后再验证的流程非常麻烦,于是博主想到了第三方平台crawlera.
一、crawlera平台注册
首先申明,注册是免费的,使用的话除了一些特殊定制外都是free的。
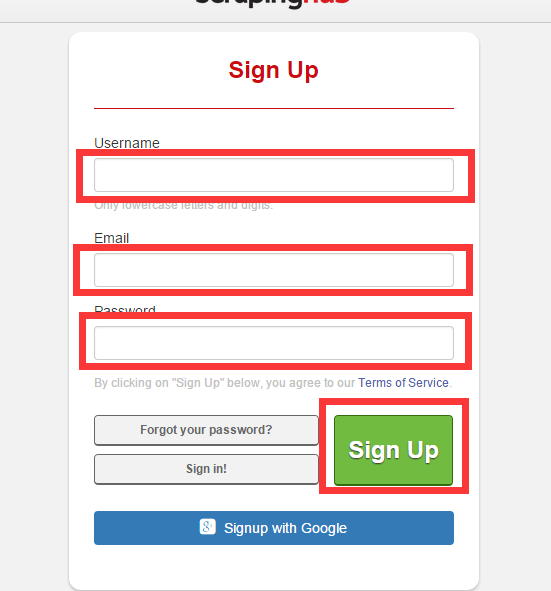
1、登录其网站 https://dash.scrapinghub.com/account/signup/
填写用户名、密码、邮箱,注册一个crawlera账号并激活
2、创建Organizations,然后添加crawlear服务
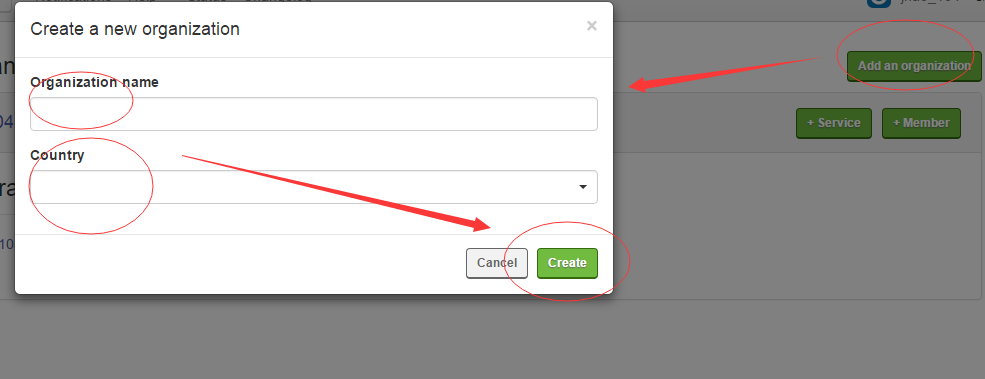
然后点击 +Service ,在弹出的界面点击Crawlear,输入名字,选择信息就创建成功了。
创建成功过后点击你的Crawlear名字便可以看到API的详细信息。
二、部署到srcapy项目
1、安装scarpy-crawlera
pip install 、easy_install 随便你采用什么安装方式都可以
|
1
|
pip install scrapy-crawlera |
2、修改settings.py
如果你之前设置过代理ip,那么请注释掉,加入crawlera的代理
|
1
2
3
4
5
|
DOWNLOADER_MIDDLEWARES = { # 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110, # 'partent.middlewares.ProxyMiddleware': 100,'scrapy_crawlera.CrawleraMiddleware': 600} |
为了是crawlera生效,需要添加你创建的api信息(如果填写了API key的话,pass填空字符串便可)
|
1
2
3
|
CRAWLERA_ENABLED = TrueCRAWLERA_USER = '<API key>'CRAWLERA_PASS = '' |
为了达到更高的抓取效率,可以禁用Autothrottle扩展和增加并发请求的最大数量,以及设置下载超时,代码如下
|
1
2
3
4
|
CONCURRENT_REQUESTS = 32CONCURRENT_REQUESTS_PER_DOMAIN = 32AUTOTHROTTLE_ENABLED = FalseDOWNLOAD_TIMEOUT = 600 |
如果在代码中设置有 DOWNLOAD_DELAY的话,需要在setting.py中添加
|
1
|
CRAWLERA_PRESERVE_DELAY = True |
如果你的spider中保留了cookies,那么需要在Headr中添加
|
1
2
3
4
5
|
DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', # 'Accept-Language': 'zh-CN,zh;q=0.8', 'X-Crawlera-Cookies': 'disable'} |
三、运行爬虫
这些都设置好了过后便可以运行你的爬虫了。这时所有的request都是通过crawlera发出的,信息如下

更多的crawlera信息请参考官方文档:http://doc.scrapinghub.com/index.html