Hadoop综合大作业 要求:
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
启动hadoop

Hdfs上创建文件夹


上传文件至hdfs

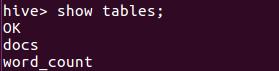
启动Hive

创建原始文档表

导入文件内容到表docs并查看

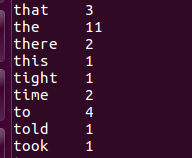
用HQL进行词频统计,结果放在表word_count里

查看统计结果
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
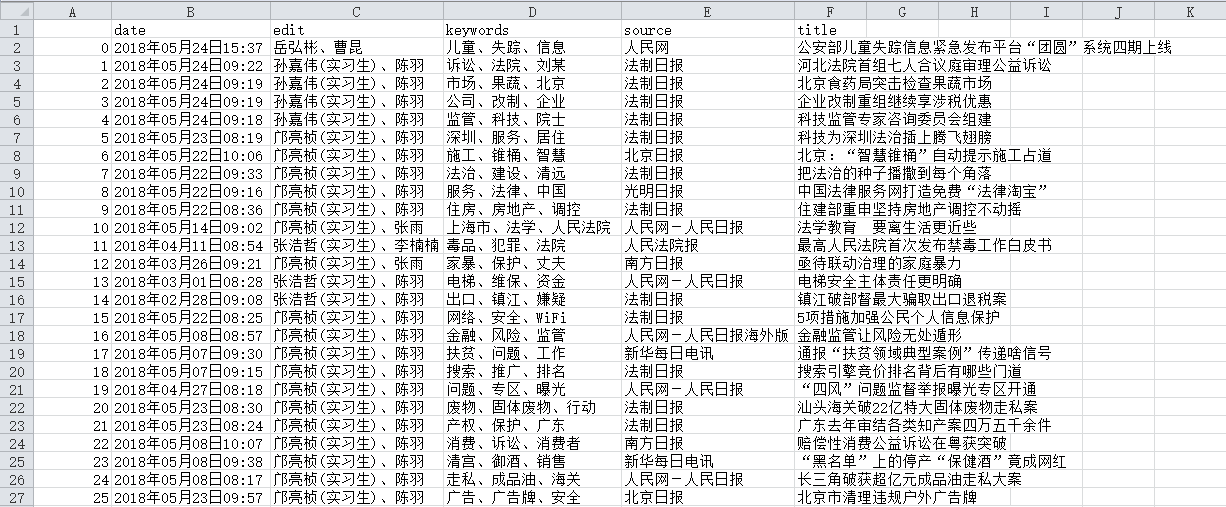
我爬的是人民网-法治频道-最新报道
下图是爬虫大作业产生的csv文件部分数据
将news.csv文件上传到百度云盘,然后在Linux系统上登录云盘下载
建立一个用于运行本作业的目录bigdata,给hadoop赋予bigdata的各种操作权限,然后将下 载好的news.csv文件复制到bigdata
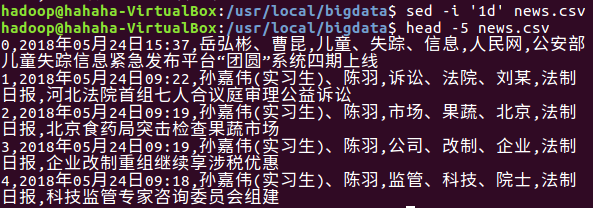
查看本地数据
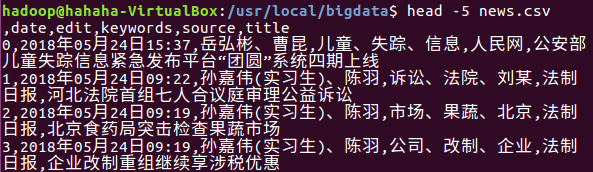
删除文件第一行记录,即字段名