Branch 向量化
问题发现定位
昨天晚上小伙伴告诉我有一个case的性能不太理想,让我看看
这个查询长这样:
SELECT SUM(CASE WHEN LO_SUPPLYCOST + 10000 > 100000 then 1 else 0 END) FROM lineorder_flat;
lineorder_flat 这个表是标准的SSB测试数据集的宽表
看起来很简单的一个查询。并行度调整为1跑跑看
+-------------------------------------------------------------------+
| sum(CASE WHEN `LO_SUPPLYCOST` + 10000 > 100000 THEN 1 ELSE 0 END) |
+-------------------------------------------------------------------+
| 299718458 |
+-------------------------------------------------------------------+
1 row in set (10.33 sec)
??? 咋回事,是因为操作系统page cache吗,再试试
mysql> SELECT SUM(CASE WHEN LO_SUPPLYCOST + 10000 > 100000 then 1 else 0 END) FROM lineorder_flat;
+-------------------------------------------------------------------+
| sum(CASE WHEN `LO_SUPPLYCOST` + 10000 > 100000 THEN 1 ELSE 0 END) |
+-------------------------------------------------------------------+
| 299718458 |
+-------------------------------------------------------------------+
1 row in set (10.45 sec)
好家伙,还真就这么慢。
显然这个case很有问题,先看一下Profile:
PROJECT_NODE (id=1):(Active: 10s267ms[10267379182ns], % non-child: 96.18%)
- CommonSubExprComputeTime: 2.752ms
- ExprComputeTime: 9s922ms
- PeakMemoryUsage: 0.00
- RowsReturned: 600.037902M (600037902)
- RowsReturnedRate: 58.441194M /sec
Profile 上面的 ExprComputeTime 是表达式执行的耗时,这个就表明了这个是 CASE WHEN 表达式执行的效率太低,可以排除SCAN和AGG的问题了
瓶颈出现在计算上那就好办了,直接用perf看热点代码在哪就行了
ps -ef|grep starrocks_be|grep stdpain|awk '{print $2}'
perf top -p $pid

很显然,问题出在 VectorizedCaseExpr和ColumnBuilder 上面。
向量化下Case When 执行原理
为了方便理解先简单说一下CASE WHEN的处理逻辑,当然也可以看一下这个向量化传送门
举个例子:
CASE WHEN col1 + 10000 > 100000 then col2 + 200 else col2 - 200 END
首先需要把所有的分支都要执行一遍
- 执行表达式
col1 + 10000 > 100000选择列为 res1 - 执行表达式
col2 + 200结果列为 res2 - 执行表达式
col2 - 200结果列为 res3 - 通过选择列 (res1) 来选择结果列 (res2, res3) ,作为 res4 返回
这样上面的每一个步骤都可以进行向量化计算
优化1 - 优化不必要的分支
ColumnBuilder是构建Column的一个帮助类,可以简化很多逻辑,看一下ColumnBuilder的代码是这样的
void append(const DatumType& value) {
_null_column->append(DATUM_NOT_NULL);
_column->append(value);
}
_null_column 和 _column 这两个成员可以认为是 std::vector<int8>
具体的调用是这样的:
builder.reserve(size);
// 对于每一行来说
for (int row = 0; row < size; ++row) {
// 先遍历选择列,来决定选的是哪一列
int i = 0;
while (i < view_size && !(when_viewers[i].value(row))) {
i += 1;
}
// 插入数据
if (!then_viewers[i].is_null(row)) {
builder.append(then_viewers[i].value(row));
} else {
builder.append_null();
}
}
这段代码问题很多
- 没有必要的null值判断,如果 then表达式不可能返回null,那也没必要检查null,另外即使then列真的可能返回null,那也不应该在循环中进行处理
- 没有必要的循环套循环
- builder调用append虽然看上去是没什么问题,而且也事先分配了空间,但是vector在调用append的时候还是会检查一下是否空间足够这样循环体里面又多了一堆 if 分支
我们先特殊优化 只有一个when的情况来验证我们的想法:
// 选择向量
uint8_t select_vector[size];
// 先拿到选择列
const auto& cond1_data = when_viewers[0].column() -> get_data();
// 构建选择向量
for (int i = 0; i < size; i++) {
select_vector[i] = cond1_data[i];
}
using ResCol = RunTimeColumnType<ResultType>;
auto res = ResCol::create();
// 先把常量展开成向量,后面再优化
auto then_0 = ColumnHelper::unpack_and_duplicate_const_column(size, then_columns[0]);
auto then_1 = ColumnHelper::unpack_and_duplicate_const_column(size, then_columns[1]);
auto& then0_data = ((ResCol*)then_0.get()) -> get_data();
auto& then1_data = ((ResCol*)then_1.get()) -> get_data();
auto& res_data = res -> get_data();
res_data.resize(size);
// 通过选择向量来选择
for(int i = 0;i < size; ++i) {
res_data[i] = select_vector[i] ? then0_data[i]: then1_data[i];
}
跑一下看看
mysql> SELECT SUM(CASE WHEN LO_SUPPLYCOST + 10000 > 100000 then 1 else 0 END) FROM lineorder_flat;
+-------------------------------------------------------------------+
| sum(CASE WHEN `LO_SUPPLYCOST` + 10000 > 100000 THEN 1 ELSE 0 END) |
+-------------------------------------------------------------------+
| 299718458 |
+-------------------------------------------------------------------+
1 row in set (4.26 sec)
果然,很有效果提升了一倍但是很多人会说 "我不满意" (手工滑稽)
优化2 - SIMD
那就继续看profile了

呃呃呃,上面显示大头还是VectorizedCaseExpr,看下具体热点
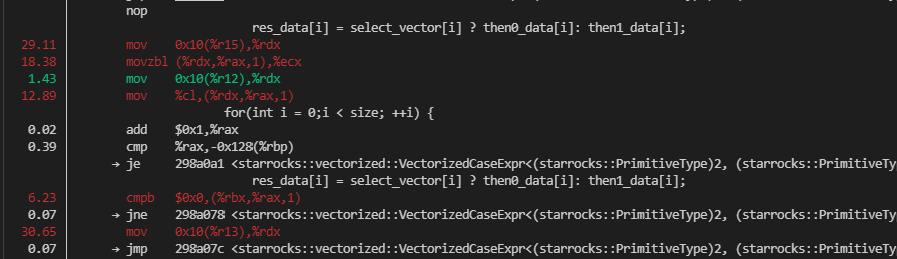
我直接 ??? 这么简单的一个循环居然没自动向量化?
for(int i = 0;i < size; ++i) {
res_data[i] = select_vector[i] ? then0_data[i]: then1_data[i];
}
一顿操作之后(各种hint restrict)发现自动挡还是不行,所以还是手动挡吧
inline void avx2_select_if(uint8_t*& selector, char*& dst, const char*& a, const char*& b, int size) {
const char* dst_end = dst + size;
while (dst + 32 < dst_end) {
__m256i loaded_mask = _mm256_loadu_si256(reinterpret_cast<__m256i*>(selector));
loaded_mask = _mm256_cmpgt_epi8(loaded_mask, _mm256_setzero_si256());
__m256i loaded_a = _mm256_loadu_si256(reinterpret_cast<const __m256i*>(a));
__m256i loaded_b = _mm256_loadu_si256(reinterpret_cast<const __m256i*>(b));
__m256i res = _mm256_blendv_epi8(loaded_b, loaded_a, loaded_mask);
_mm256_storeu_si256(reinterpret_cast<__m256i*>(dst), res);
dst += 32;
selector += 32;
a += 32;
b += 32;
}
}
template <PrimitiveType TYPE, typename Container = typename RunTimeColumnType<TYPE>::Container>
void select_if(uint8_t* select_vector, Container& dst, const Container& a, const Container& b) {
int size = dst.size();
auto* start_dst = dst.data();
auto* end_dst = dst.data() + size;
auto* start_a = a.data();
auto* start_b = b.data();
if constexpr (std::is_same_v<RunTimeCppType<TYPE>, int8_t>) {
avx2_select_if(select_vector, start_dst, start_a, start_b, size);
}
while (start_dst < end_dst) {
*start_dst = *select_vector ? *start_a : *start_b;
select_vector++;
start_dst++;
start_a++;
start_b++;
}
}
测试结果: 比较符合预期,证明思路没问题
mysql> SELECT SUM(CASE WHEN LO_SUPPLYCOST + 10000 > 100000 then 1 else 0 END) FROM lineorder_flat;
+-------------------------------------------------------------------+
| sum(CASE WHEN `LO_SUPPLYCOST` + 10000 > 100000 THEN 1 ELSE 0 END) |
+-------------------------------------------------------------------+
| 299718458 |
+-------------------------------------------------------------------+
1 row in set (1.69 sec)