python爬虫如何POST request payload形式的请求
1. 背景
最近在爬取某个站点时,发现在POST数据时,使用的数据格式是request payload,有别于之前常见的 POST数据格式(Form data)。而使用Form data数据的提交方式时,无法提交成功。
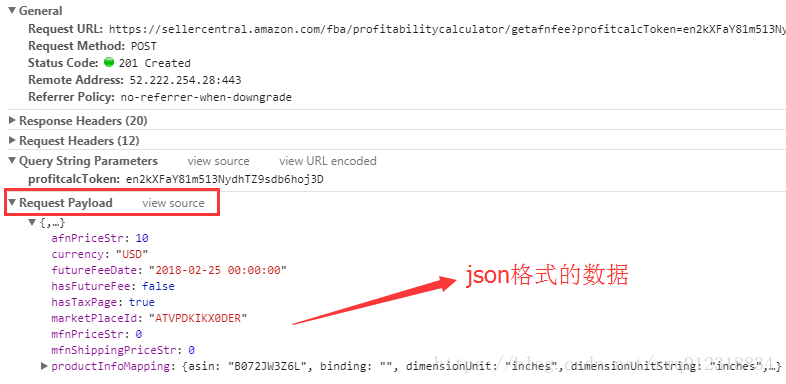
于是上网查了下二者的区别:http://xiaobaoqiu.github.io/blog/2014/09/04/form-data-vs-request-payload/,下面做了搬运工(侵权立删…)
1.1. Http请求中Form Data 和 Request Payload的区别
AJAX Post请求中常用的两种传参数的形式:form data 和 request payload
1.1.1. Form data
get请求的时候,我们的参数直接反映在url里面,形式为key1=value1&key2=value2形式,比如:
http://news.baidu.com/ns?word=NBA&tn=news&from=news&cl=2&rn=20&ct=1
而如果是post请求,那么表单参数是在请求体中,也是以key1=value1&key2=value2的形式在请求体中。通过chrome的开发者工具可以看到,如下:
RequestURL:http://127.0.0.1:8080/test/test.do
Request Method:POST
Status Code:200 OK
Request Headers
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding:gzip,deflate,sdch
Accept-Language:zh-CN,zh;q=0.8,en;q=0.6
AlexaToolbar-ALX_NS_PH:AlexaToolbar/alxg-3.2
Cache-Control:max-age=0
Connection:keep-alive
Content-Length:25
Content-Type:application/x-www-form-urlencoded
Cookie:JSESSIONID=74AC93F9F572980B6FC10474CD8EDD8D
Host:127.0.0.1:8080
Origin:http://127.0.0.1:8080
Referer:http://127.0.0.1:8080/test/index.jsp
User-Agent:Mozilla/5.0 (Windows NT 6.1)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.149 Safari/537.36
Form Data
name:mikan
address:street
Response Headers
Content-Length:2
Date:Sun, 11 May 2014 11:05:33 GMT
Server:Apache-Coyote/1.1
这里要注意post请求的Content-Type为application/x-www-form-urlencoded(默认的),参数是在请求体中,即上面请求中的Form Data。
前端代码:提交数据
xhr.setRequestHeader("Content-type","application/x-www-form-urlencoded");
xhr.send("name=foo&value=bar");
后端代码:接收提交的数据。在servlet中,可以通过request.getParameter(name)的形式来获取表单参数。
/**
* 获取httpRequest的参数
*
* @param request
* @param name
* @return
*/
protected String getParameterValue(HttpServletRequest request, String name) {
return StringUtils.trimToEmpty(request.getParameter(name));
}
1.1.2. Request payload
如果使用原生AJAX POST请求的话,那么请求在chrome的开发者工具的表现如下,主要是参数在
Remote Address:192.168.234.240:80
Request URL:http://tuanbeta3.XXX.com/qimage/upload.htm
Request Method:POST
Status Code:200 OK
Request Headers
Accept:application/json, text/javascript, */*; q=0.01
Accept-Encoding:gzip,deflate,sdch
Accept-Language:zh-CN,zh;q=0.8,en;q=0.6
Connection:keep-alive
Content-Length:151
Content-Type:application/json;charset=UTF-8
Cookie:JSESSIONID=E08388788943A651924CA0A10C7ACAD0
Host:tuanbeta3.XXX.com
Origin:http://tuanbeta3.XXX.com
Referer:http://tuanbeta3.XXX.com/qimage/customerlist.htm?menu=19
User-Agent:Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.114 Safari/537.36
X-Requested-With:XMLHttpRequest
Request Payload
[{widthEncode:NNNcaXN, heightEncode:NNNN5NN, displayUrl:201409/03/66I5P266rtT86oKq6,…}]
Response Headers
Connection:keep-alive
Content-Encoding:gzip
Content-Type:application/json;charset=UTF-8
Date:Thu, 04 Sep 2014 06:49:44 GMT
Server:nginx/1.4.7
Transfer-Encoding:chunked
Vary:Accept-Encoding
注意请求的Content-Type是application/json;charset=UTF-8,而请求表单的参数在Request Payload中。
后端代码:获取数据(这里使用org.apache.commons.io.):
/**
* 从 request 获取 payload 数据
*
* @param request
* @return
* @throws IOException
*/
private String getRequestPayload(HttpServletRequest request) throws IOException {
return IOUtils.toString(request.getReader());
}
1.1.3. 二者区别
如果一个请求的Content-Type设置为application/x-www-form-urlencoded,那么这个Post请求会被认为是Http Post表单请求,那么请求主体将以一个标准的键值对和&的querystring形式出现。这种方式是HTML表单的默认设置,所以在过去这种方式更加常见。
其他形式的POST请求,是放到 Request payload 中(现在是为了方便阅读,使用了Json这样的数据格式),请求的Content-Type设置为application/json;charset=UTF-8或者不指定。
2. 环境
python 3.6.1
系统:win7
IDE:pycharm
requests 2.14.2
scrapy 1.4.0
3. 使用requests模块post payload请求
import json
import requests
import datetime
postUrl = 'https://sellercentral.amazon.com/fba/profitabilitycalculator/getafnfee?profitcalcToken=en2kXFaY81m513NydhTZ9sdb6hoj3D'
# payloadData数据
payloadData = {
'afnPriceStr': 10,
'currency':'USD',
'productInfoMapping': {
'asin': 'B072JW3Z6L',
'dimensionUnit': 'inches',
}
}
# 请求头设置
payloadHeader = {
'Host': 'sellercentral.amazon.com',
'Content-Type': 'application/json',
}
# 下载超时
timeOut = 25
# 代理
proxy = "183.12.50.118:8080"
proxies = {
"http": proxy,
"https": proxy,
}
r = requests.post(postUrl, data=json.dumps(payloadData), headers=payloadHeader)
dumpJsonData = json.dumps(payloadData)
print(f"dumpJsonData = {dumpJsonData}")
res = requests.post(postUrl, data=dumpJsonData, headers=payloadHeader, timeout=timeOut, proxies=proxies, allow_redirects=True)
# 下面这种直接填充json参数的方式也OK
# res = requests.post(postUrl, json=payloadData, headers=header)
print(f"responseTime = {datetime.datetime.now()}, statusCode = {res.status_code}, res text = {res.text}")
4. 在scrapy中post payload请求
这儿有个坏消息,那就是scrapy目前还不支持payload这种request请求。而且scrapy对formdata的请求也有很严格的要求,具体可以参考这篇文章:https://blog.csdn.net/zwq912318834/article/details/78292536
4.1. 分析scrapy源码
参考注解
# 文件:E:MinicondaLibsite-packagesscrapyhttp
equestform.py
class FormRequest(Request):
def __init__(self, *args, **kwargs):
formdata = kwargs.pop('formdata', None)
if formdata and kwargs.get('method') is None:
kwargs['method'] = 'POST'
super(FormRequest, self).__init__(*args, **kwargs)
if formdata:
items = formdata.items() if isinstance(formdata, dict) else formdata
querystr = _urlencode(items, self.encoding)
# 这儿写死了,当提交数据时,设置好Content-Type,也就是form data类型
# 就算改写这儿,后面也没有对 json数据解析的处理
if self.method == 'POST':
self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded')
self._set_body(querystr)
else:
self._set_url(self.url + ('&' if '?' in self.url else '?') + querystr)
4.2. 思路:在scrapy中嵌入requests模块
分析请求


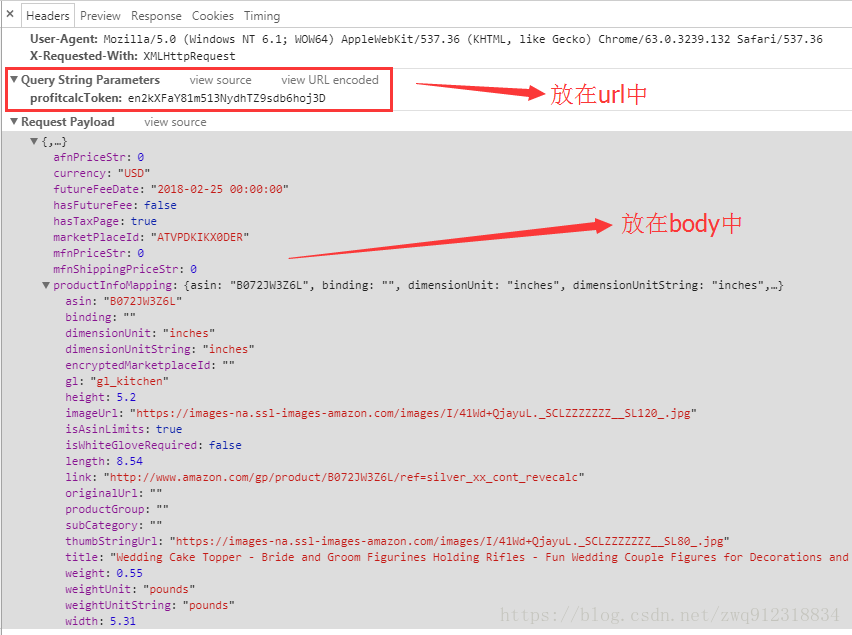
返回的查询结果
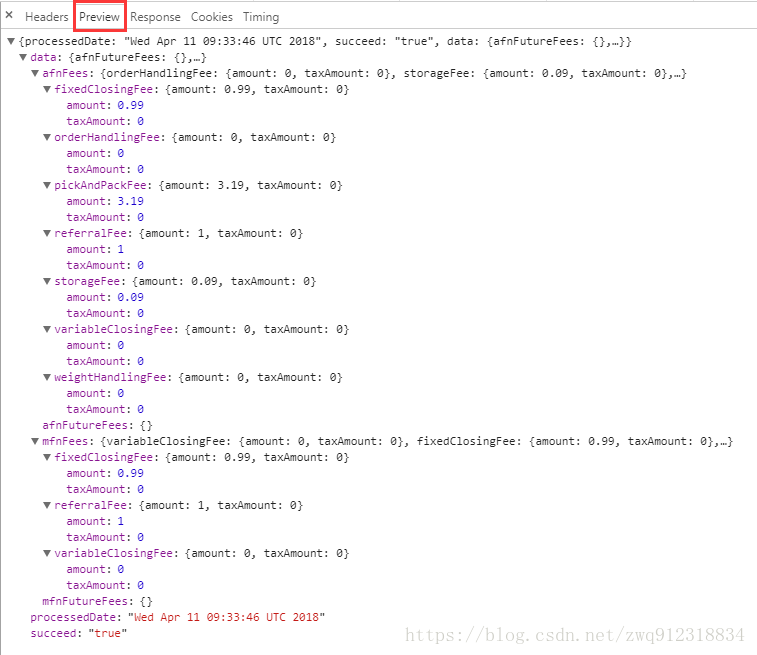
第一步:在爬虫中构造请求,把所有的参数以及必要信息带进去。
# 文件 mySpider.py中
payloadData = {}
payloadData['afnPriceStr'] = 0
payloadData['currency'] = asinInfo['currencyCodeHidden']
payloadData['futureFeeDate'] = asinInfo['futureFeeDateHidden']
payloadData['hasFutureFee'] = False
payloadData['hasTaxPage'] = True
payloadData['marketPlaceId'] = asinInfo['marketplaceIdHidden']
payloadData['mfnPriceStr'] = 0
payloadData['mfnShippingPriceStr'] = 0
payloadData['productInfoMapping'] = {}
payloadData['productInfoMapping']['asin'] = dataFieldJson['asin']
payloadData['productInfoMapping']['binding'] = dataFieldJson['binding']
payloadData['productInfoMapping']['dimensionUnit'] = dataFieldJson['dimensionUnit']
payloadData['productInfoMapping']['dimensionUnitString'] = dataFieldJson['dimensionUnitString']
payloadData['productInfoMapping']['encryptedMarketplaceId'] = dataFieldJson['encryptedMarketplaceId']
payloadData['productInfoMapping']['gl'] = dataFieldJson['gl']
payloadData['productInfoMapping']['height'] = dataFieldJson['height']
payloadData['productInfoMapping']['imageUrl'] = dataFieldJson['imageUrl']
payloadData['productInfoMapping']['isAsinLimits'] = dataFieldJson['isAsinLimits']
payloadData['productInfoMapping']['isWhiteGloveRequired'] = dataFieldJson['isWhiteGloveRequired']
payloadData['productInfoMapping']['length'] = dataFieldJson['length']
payloadData['productInfoMapping']['link'] = dataFieldJson['link']
payloadData['productInfoMapping']['originalUrl'] = dataFieldJson['originalUrl']
payloadData['productInfoMapping']['productGroup'] = dataFieldJson['productGroup']
payloadData['productInfoMapping']['subCategory'] = dataFieldJson['subCategory']
payloadData['productInfoMapping']['thumbStringUrl'] = dataFieldJson['thumbStringUrl']
payloadData['productInfoMapping']['title'] = dataFieldJson['title']
payloadData['productInfoMapping']['weight'] = dataFieldJson['weight']
payloadData['productInfoMapping']['weightUnit'] = dataFieldJson['weightUnit']
payloadData['productInfoMapping']['weightUnitString'] = dataFieldJson['weightUnitString']
payloadData['productInfoMapping']['width'] = dataFieldJson['width']
# https://sellercentral.amazon.com/fba/profitabilitycalculator/getafnfee?profitcalcToken=en2kXFaY81m513NydhTZ9sdb6hoj3D
postUrl = f"https://sellercentral.amazon.com/fba/profitabilitycalculator/getafnfee?profitcalcToken={asinInfo['tokenValue']}"
payloadHeader = {
'Host': 'sellercentral.amazon.com',
'Content-Type': 'application/json',
}
# scrapy源码:self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded')
print(f"payloadData = {payloadData}")
# 这个request并不真正用来调度,去发出请求,因为这种方式构造方式,是无法提交成功的,会返回404错误
# 这样构造主要是把查询参数提交出去,在下载中间件部分用request模块下载,用 “payloadFlag” 标记这种request
yield Request(url = postUrl,
headers = payloadHeader,
meta = {'payloadFlag': True, 'payloadData': payloadData, 'headers': payloadHeader, 'asinInfo': asinInfo},
callback = self.parseAsinSearchFinallyRes,
errback = self.error,
dont_filter = True
)
第二步:在中间件中,用requests模块处理这个请求
# 文件:middlewares.py
class PayLoadRequestMiddleware:
def process_request(self, request, spider):
# 如果有的请求是带有payload请求的,在这个里面处理掉
if request.meta.get('payloadFlag', False):
print(f"PayLoadRequestMiddleware enter")
postUrl = request.url
headers = request.meta.get('headers', {})
payloadData = request.meta.get('payloadData', {})
proxy = request.meta['proxy']
proxies = {
"http": proxy,
"https": proxy,
}
timeOut = request.meta.get('download_timeout', 25)
allow_redirects = request.meta.get('dont_redirect', False)
dumpJsonData = json.dumps(payloadData)
print(f"dumpJsonData = {dumpJsonData}")
# 发现这个居然是个同步 阻塞的过程,太过影响速度了
res = requests.post(postUrl, data=dumpJsonData, headers=headers, timeout=timeOut, proxies=proxies, allow_redirects=allow_redirects)
# res = requests.post(postUrl, json=payloadData, headers=header)
print(f"responseTime = {datetime.datetime.now()}, res text = {res.text}, statusCode = {res.status_code}")
if res.status_code > 199 and res.status_code < 300:
# 返回Response,就进入callback函数处理,不会再去下载这个请求
return HtmlResponse(url=request.url,
body=res.content,
request=request,
# 最好根据网页的具体编码而定
encoding='utf-8',
status=200)
else:
print(f"request mode getting page error, Exception = {e}")
return HtmlResponse(url=request.url, status=500, request=request)
4.3. 遗留下的问题
scrapy之所以强大,就是因为并发度高。大家都知道,由于Python GIL的原因,导致python无法通过多线程来提高性能。但是至少可以做到下载与解析同步的过程,在下载空档的时候,进行数据的解析,调度等等,这都归功于scrapy采用的异步结构。
但是,我们在中间件中使用requests模块进行网页下载,因为这是个同步过程,所以会阻塞在这个地方,拉低了整个爬虫的效率。
所以,需要根据项目具体的情况,来决定合适的方案。当然这里又涉及到一个新的话题,就是scrapy提供的两种爬取模式:深度优先模式和广度优先模式。如何尽可能最大限度的利用scrapy的并发?在环境不稳定的情形下如何保证尽可能稳定的拿到数据?
深度优先模式和广度优先模式是在settings中设置的。
# 文件: settings.py
# DEPTH_PRIORITY(默认值为0)设置为一个正值后,Scrapy的调度器的队列就会从LIFO变成FIFO,因此抓取规则就由DFO(深度优先)变成了BFO(广度优先)
DEPTH_PRIORITY = 1, # 广度优先(肯呢个会累积大量的request,累计占有大量的内存,最终数据也在最后一批爬取)
深度优先:DEPTH_PRIORITY = 0
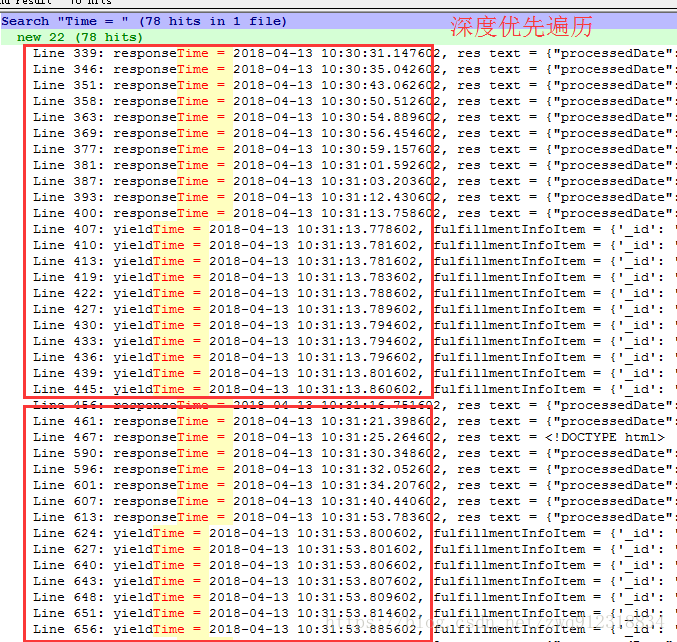
广度优先:DEPTH_PRIORITY = 1
想将这个过程做成异步的,一直没有思路,欢迎大神提出好的想法
---------------------
作者:Kosmoo
来源:CSDN
原文:https://blog.csdn.net/zwq912318834/article/details/79930423
版权声明:本文为博主原创文章,转载请附上博文链接!