在引出协程概念之前先说说python的进程和线程。
进程:
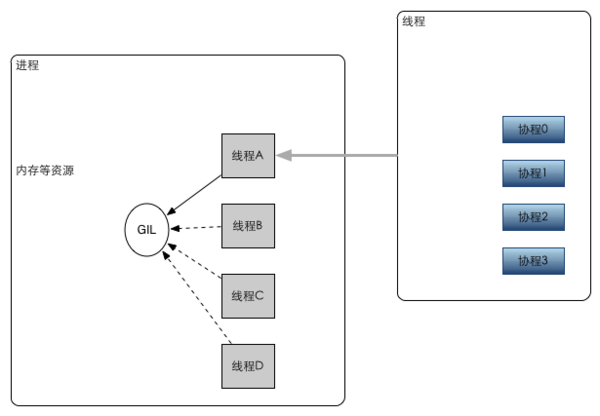
进程是正在执行程序实例。执行程序的过程中,内核会讲程序代码载入虚拟内存,为程序变量分配空间,建立 bookkeeping 数据结构,来记录与进程有关的信息,
比如进程 ID,用户 ID 等。在创建进程的时候,内核会为进程分配一定的资源,并在进程存活的时候不断进行调整,比如内存,进程创建的时候会占有一部分内存。
进程结束的时候资源会释放出来,来让其他资源使用。我们可以把进程理解为一种容器,容器内的资源可多可少,但是在容器内的程序只能使用容器内的东西。因此启动进程的时候会比较慢,尤其是windows,尤其是多进程的时候(最好是在密集性运算的时候启动多进程)
线程:
一个进程中可以执行多个线程。多个线程共享进程内的资源。所以可以将线程可以看成是共享同一虚拟内存以及其他属性的进程。
线程相对于进程的优势在于同一进程下的不同线程之间的数据共享更加容易。
在说到线程的时候说说GIL(全局解释性锁 GLOBAL INTERPRETER LOCK),GIL 的存在是为了实现 Python 中对于共享资源访问的互斥。而且是非常霸道的解释器级别的互斥。在 GIL 的机制下,一个线程访问解释器之后,其他的线程就需要等待这个线程释放之后才可以访问。这种处理方法在单处理器下面并没有什么问题,单处理器的本质是串行执行的。但是再多处理器下面,这种方法会导致无法利用多核的优势。Python 的线程调度跟操作系统的进程调度类似,都属于抢占式的调度。一个进程执行了一定时间之后,发出一个信号,操作系统响应这个时钟中断(信号),开始进程调度。而在 Python 中,则通过软件模拟这种中断,来实现线程调度。比如:对全局的num做加到100的操作,可能在你加到11的时候,还没加完,则CPU就交给另一个线程处理,所以最后的结果可能比100会小或者比100会大。
简单的说说进程和线程的几点关系
1、启动一个进程至少会有一个线程
2、修改主线程的数据会影响到子线程的数据,因为他们之间内存是共享的,修改主进程不会影响到子进程的数据,两个子进程之间是相互独立的,如果要实现子进程间的通信,可以利用中间件,比如multiprocessing的Queue。
如:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#进程之间的通信
from multiprocessing import Process,Queue
def f(qq):
#在子进程设置值,本质上是子进程pickle数据序列化到公共的地方
qq.put(['hello',None,123])
if __name__ == '__main__':
q = Queue()
t = Process(target=f,args=(q,))
t.start()
#从父进程中取出来,本质上是父进程pickle从公共的地方把数据反序列化出来
print q.get()
t.join()
3、新的线程很容易被创建,但是新的进程需要对其父进程进行一次克隆
4、一个线程可以操作和控制同一个进程里的其他线程,但进程只能操作其子进程。
明白了进程和线程的概念之后,说说协程。
协程:
协程,又称微线程。英文名Coroutine。
协程最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
用yield来实现传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('Consume running %s...' % n)
time.sleep(1) #遇到阻塞到produce执行
r = '200 OK'
def produce(c):
c.next() #启动迭代器
n = 0
while n < 5:
n = n + 1
print('[Produce] running %s...' % n)
r = c.send(n) #到consumer中执行
print('[Consumer] return: %s' % r)
c.close()
if __name__=='__main__':
c = consumer() #迭代器
produce(c)
执行结果:
[Produce] running 1...
Consume running 1...
[Consumer] return: 200 OK
[Produce] running 2...
Consume running 2...
[Consumer] return: 200 OK
[Produce] running 3...
Consume running 3...
[Consumer] return: 200 OK
[Produce] running 4...
Consume running 4...
[Consumer] return: 200 OK
[Produce] running 5...
Consume running 5...
[Consumer] return: 200 OK
其实python有个模块封装了协程功能,greenlet.来看代码。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#封装好的协成
from greenlet import greenlet
def test1():
print "test1:",11
gr2.switch()
print "test1:",12
gr2.switch()
def test2():
print "test2:",13
gr1.switch()
print "test2:",14
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()
执行结果:
test1: 11
test2: 13
test1: 12
test2: 14
这个还的人工切换,是不是觉得太麻烦了,不要捉急,python还有一个自动切换比greenlet更强大的gevent。
其原理是当一个greenlet遇到IO操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO。直接上代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#协成的自动切换
import gevent
import time
def func1():
print('�33[31;1m 正在执行 111...�33[0m')
gevent.sleep(2)
print('�33[31;1m 正在执行 444...�33[0m')
def func2():
print('�33[32;1m 正在执行 222...�33[0m')
gevent.sleep(3) #阻塞3秒,所以自动切换到func1,执行完func1后 再切换回来
print('�33[32;1m 正在执行 333...�33[0m')
start_time = time.time()
gevent.joinall([
gevent.spawn(func1),
gevent.spawn(func2),
# gevent.spawn(func3),
])
end_time = time.time()
#程序总共花费3秒执行
print "spend",(end_time-start_time),"second"
执行结果:
正在执行 111...
正在执行 222...
正在执行 444...
正在执行 333...
总耗时:
spend 3.00936698914 second
下面我们用greenlet来实现一个socket多线程处理数据的功能。不过需要安装一个monkey补丁,请自行安装吧。
注意 :from gevent import monkey;monkey.patch_all()一定要放到导入socket模块之前,否则gevent无法识别socket的阻塞


#!/usr/bin/env python # -*- coding:utf-8 -*- from socket import * ADDR, PORT = 'localhost', 8001 client = socket(AF_INET,SOCK_STREAM) client.connect((ADDR, PORT)) while 1: cmd = raw_input('>>:').strip() if len(cmd) == 0: continue client.send(cmd) data = client.recv(1024) print data #print('Received', repr(data)) client.close()
#!/usr/bin/env python # -*- coding:utf-8 -*- import sys import socket import gevent from gevent import monkey monkey.patch_all() def server(port): sock = socket.socket() sock.bind(('127.0.0.1', port)) sock.listen(500) while 1: conn, addr = sock.accept() #handle_request(conn) gevent.spawn(handle_request, conn) def handle_request(conn): try: while 1: data = conn.recv(1024) if not data: break print("recv:",data) conn.send(data) except Exception as ex: print(ex) finally: conn.close() if __name__ == '__main__': server(8001)
以上代码可以自行多开几个客户端,然后执行看看,是不是很酷,无论客户端输入什么,服务端都能实时接收到。
摘取于:http://python.jobbole.com/87156/
更详细内容请参考以下博客:
http://python.jobbole.com/86481/
http://www.cnblogs.com/Eva-J/articles/8324673.html