基础篇
注:table指的是操作的表名称
(1)数据模型的三要素及基础概念
①数据模型的三要素:数据结构、数据操作、数据约束条件
②一定要记住,SQL 对大小写不敏感!
③SQL 指结构化查询语言
④RDBMS 指的是关系型数据库管理系统RDBMS 中的数据存储在被称为表(tables)的数据库对象中。表是相关的数据项的集合,它由列和行组成。
⑤有些数据库系统要求在每条 SQL 命令的末端使用分号,一般的程序里面写sql就不要加分号,如果在查询分析器里就要区分,mysql就需要,而SQL SERVER 则不需要
⑥可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)
(a)查询和更新指令构成了 SQL 的 DML 部分:
SELECT - 从数据库表中获取数据
UPDATE - 更新数据库表中的数据
DELETE - 从数据库表中删除数据
INSERT INTO - 向数据库表中插入数据
(b)SQL 中最重要的 DDL 语句:
CREATE DATABASE - 创建新数据库
ALTER DATABASE - 修改数据库
CREATE TABLE - 创建新表
ALTER TABLE - 变更(改变)数据库表
DROP TABLE - 删除表
CREATE INDEX - 创建索引(搜索键)
DROP INDEX - 删除索引
(2)基础查询select
select XX from table ,查询语句一般都要加where条件
(3)去重distinct
select distinct(xx) from table ,将XX重复的行去掉,只显示一行
(4)更新update
update table set XX where YY
update语句为跟新数据库内容的语句,所以update语句必须添加条件也就是where条件,不然就是整表跟新
(5)删除语句
①delete
delete from table where XXX=yyy,delete 常用于删除一行数据,后面需要跟where条件,如果不跟where条件将删除整个表,那么效果将跟truncate一样
②truncate
truncate table XXX,没有where条件,删除整张表的数据
③drop
drop table XX,drop将会删除掉整个表结构,不仅仅是数据
(6)插入语句
①常规使用insert into table …values
insert into table(A,B,C) values(1,‘set’,3)
②升级使用:insert into table …select…from…
insert into TABLE( A1,A2) select B1,B2.from table1,将table1中的B1,B2列的数据插入table 表中的A1与A2列
③跨数据库的插入
insert into 目标数据库名字…table(sysname,sysvalue,comment,tagNO,sysflag,Y_id)
select sysname,sysvalue,comment,tagNO,sysflag,Y_id from 数据来源数据库名字…table
④当提示不允许插入数据时的解决办法
允许将显式值插入表的标识列中 ON-允许 OFF-不允许
set identity_insert table ON--打开
set identity_insert table OFF--关闭
(7)where后面的关键字
Persons 表:
①and与or
select Id from Persons where lastname='bush' and firstname='George'
结果为:2
select Id from Persons where lastname='bush' or firstname='John'
结果为:1,2
②like与通配符%
like 操作符用于在 where子句中搜索列中的指定模式。
在搜索数据库中的数据时,SQL 通配符可以替代一个或多个字符。SQL 通配符必须与like 运算符一起使用。
SELECT * FROM Persons WHERE City LIKE '%lond%'

③in
in 操作符允许我们在 where子句中规定多个值。
select Id from Persons where LastName IN ('Adams','Carter')
结果为:1,3
④between
操作符 between … and 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
⑤is null与is not null
select * from Persons where city is null --将city中为null的数据筛选出来
select * from Persons where city is not null --将city中不为null的数据筛选出来
(8)排序 order by
①升序ASC
SELECT id, name, gender, score
FROM students
WHERE class_id = 1
ORDER BY score ASC
根据score字段进行升序操作
②降序DESC
SELECT id, name, gender, score
FROM students
WHERE class_id = 1
ORDER BY score DESC
根据score字段进行降序操作
(9)分组group by
SELECT class_id, COUNT(*) FROM students GROUP BY class_id
存在聚合函数时,列只允许存在分组列,其它的列放进去会报错,group by必须得配合聚合函数来用
(10)多表查询
表A:数据A_ID(1,2,3)表B:数据B_ID(1,2,4)
①inner join
select * from A
inner join B
on A_ID=B_ID
结果为1,2,由此可见inner join 就相当于两张表的交集,而交集的项为on后面的条件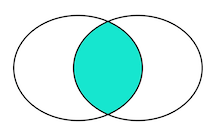
②left outer
select * from A
left outer join B
on A_ID=B_ID
结果为1,2,3由此可见left outer join 就相当于以左边表为准也就是主表为准(也就是A表),如果3在B表找不到,那么查询的最后结果以NULL填充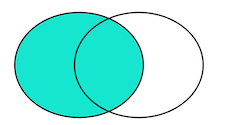
③right outer
select * from A
right outer join B
on A_ID=B_ID
结果为1,2,4由此可见left outer join 就相当于以右边表为准也就是主表为准(也就是B表),如果4在A表找不到,那么查询的最后结果以NULL填充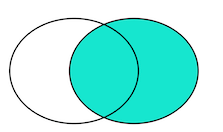
④full outer
select * from A
full outer join B
on A_ID=B_ID
结果为1,2,3,4由此可见full outer join 就相当于两张表的并集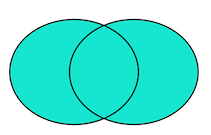
on相当于where一般,2张表关联,on后面肯定存在多个匹配条件他们是用and连接在一起的
(11)嵌套查询
简单的来说就是将一个查询的语句的结果作为外层查询条件的筛选条件,这种方式查询数据非常好用,也是最常用的查询方式,如:
select smb_id from salemanagebill where bill_id in
(
select billid from billidx where
billdate >='2020-05-10 00:00:00.000' and billtype in (10,11)
)
如果复杂一点可以都嵌套几层,如:
update salemanagebill set retailprice =8.5 where smb_id in
(
select smb_id from salemanagebill where bill_id in
(
select billid from billidx where
billdate >='2020-05-10 00:00:00.000' and billtype in (10,11)
)
and p_id in (select product_id from products where serial_number ='Z01QT00454')
)
(12)聚合函数
最常见的聚合函数:MAX(最大)、MIN(最小)、SUM(求和)、AVG(平均)、COUNT(统计次数),聚合函数一般使用大写。
select SUM(money) AS 求和 from VIPCard
select MIN (money) AS 最小值 from VIPCard
select MAX(money) AS 最大值 from VIPCard
select AVG (money) AS 平均值 from VIPCard
select COUNT(*) AS 条数汇总 from VIPCard
(13)HAVING过滤条件
下面代码的意思为,先通过where条件筛选出t_student表中sex不等于1的数据,通过group by和聚合函数将对应数据计算出来,然后用 having对聚合函数计算结果进行筛选以后,最后显示出来
SELECT student_class,AVG(student_age) AS 平均年龄 FROM t_student where sex<>1
GROUP BY (student_class) HAVING AVG(student_age)>20
where和having的使用区别,聚合函数是在where条件后执行的,所以我们将聚合函数放到where条件中是起不了筛选作用的,而且还会报错,所以我们使用having来对聚合函数进行筛选,而不能用where,having要放在GROUP BY之后,还有就是where条件和having条件并不冲突是可以一起使用的
Transact-SQL 编程
(1)GO
标志这程序段的开始,在下一个GO出现之前,本GO之下的代码都为一段代码,在里面定义的局部变量可以正常使用,但在下一个GO之后的代码就不能再使用第一个GO里面定义的变量
(2)begin…end
表示代码块,如if语句下面,就用begin…end ,有点像java中的{}
(3)as
表示程序即将开始,在库或是表定义之下,程序开始之间
(4)局部变量
①定义关键字:declare
②变量的赋值
set @变量名 = 变量值
select @变量名 = 变量值
③变量声明与定义
declare @id char(10)–声明一个长度的变量id
declare @age int --声明一个int类型变量age
select @id = 22 --赋值操作
set @age = 55 --赋值操作
print convert(char(10), @age) + ‘#’ + @id
select @age, @id
(5)全局变量
select @@identity;–最后一次自增的值
select identity(int, 1, 1) as id into tab from student;–将studeng表的烈属,以/1自增形式创建一个tab
select * from tab;
select @@rowcount;–影响行数
select @@cursor_rows;–返回连接上打开的游标的当前限定行的数目
select @@error;–T-SQL的错误号
select @@procid;
–配置函数
set datefirst 7;–设置每周的第一天,表示周日
select @@datefirst as ‘星期的第一天’, datepart(dw, getDate()) AS ‘今天是星期’;
select @@dbts;–返回当前数据库唯一时间戳
set language ‘Italian’;
select @@langId as ‘Language ID’;–返回语言id
select @@language as ‘Language Name’;–返回当前语言名称
select @@lock_timeout;–返回当前会话的当前锁定超时设置(毫秒)
select @@max_connections;–返回SQL Server 实例允许同时进行的最大用户连接数
select @@MAX_PRECISION AS ‘Max Precision’;–返回decimal 和numeric 数据类型所用的精度级别
select @@SERVERNAME;–SQL Server 的本地服务器的名称
select @@SERVICENAME;–服务名
select @@SPID;–当前会话进程id
select @@textSize;
select @@version;–当前数据库版本信息
–系统统计函数
select @@CONNECTIONS;–连接数
select @@PACK_RECEIVED;
select @@CPU_BUSY;
select @@PACK_SENT;
select @@TIMETICKS;
select @@IDLE;
select @@TOTAL_ERRORS;
select @@IO_BUSY;
select @@TOTAL_READ;–读取磁盘次数
select @@PACKET_ERRORS;–发生的网络数据包错误数
select @@TOTAL_WRITE;–sqlserver执行的磁盘写入次数
(6)输出
关键字:select、print
print 变量或表达式
select 变量或表达式
(7)选择语句: if-else判断语句
if <表达式>
<命令行或程序块>
else if <表达式>
<命令行或程序块>
else
<命令行或程序块>
示例
if 2 > 3
print '2 > 3'
else if (3 > 2)
print '3 > 2'
else
print 'other'
(7)case语句
case XX
when <条件表达式> then <运算式>
when <条件表达式> then <运算式>
when <条件表达式> then <运算式>
else <运算式>
end
示例
select *,case sex
when 1 then '男'
when 0 then '女'
else '火星人'
end as '性别'
from student;
(8)while循环、continue、break
while <表达式>
begin
<命令行或程序块>
[break]
[continue]
<命令行或程序块>
end