基础
Redis是什么?
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件
Redis为什么是CP?
https://stackoverflow.com/questions/59511275/redis-availability-and-cap-theorem
缓存雪崩、缓存穿透、缓存击穿
外文的解释:What is cache penetration, cache breakdown and cache avalanche?
引自:https://blog.csdn.net/zeb_perfect/article/details/54135506
缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决方案:假如原来设置的过期时间为expireTime,就在这个基础上加个随机时间,不让所有key同时失效。
缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞.
解决方案:布隆过滤器
缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
解决方案:设置热点数据永不过期,或者加上互斥锁就行了。
总结下,
缓存穿透,穿了Redis缓存层以及DB层。
缓存击穿,*某些热key*过期的瞬间大量并发请求过来,缓存层没起到作用,打到DB层,压垮DB。
缓存雪崩,一大片key同时失效。
在看的时候猛然搜到一篇比较强的文章,大部分知识都很详细,不在本文多叙述了。https://juejin.cn/post/6844904017387077640#heading-10
基础知识
以下内容基于Redis 2.9版本,截止2020-04-13已经是Redis6版本了。尽管版本有所差异,但其中蕴含的一些设计思想可能还是可以借鉴下。如果想看下稍微新点的,可以参考《Redis5 设计与源码分析》。
另外,学习的时候可以在虚拟机上用docker启个redis,用RedisDesktopManger来连下,学习下命令什么的。
果然国内的技术书籍相比于最新的潮流是要落后一些,所以有能力的话还是尽量多学学英语吧,争取看英文文档跟中文一样顺畅。
Redis中最基本的数据结构
SDS, 链表,字典,跳跃表,整数集合,压缩列表
SDS(Simple Dynamic String)简单动态字符串
相比C字符串,SDS具有以下优点:
- 常数复杂度获取字符串长度
- 杜绝缓冲区溢出
- 减少修改字符串长度时所需的内存重分配次数
- 二进制安全
- 兼容部分C字符串函数
链表
链表提供了高效的节点重排能力,以及顺序性的节点访问方式,并且可以通过增删节点来灵活的调整链表的长度。
除了list之外,发布与订阅、慢查询、监视器等功能也用到了链表,Redis服务器本身还使用链表来保存多个客户端的状态信息,以及使用链表来构建客户端输出缓冲区(output buffer)
Redis的链表是一个双端无环链表,带表头指针、表尾指针、长度计数器。
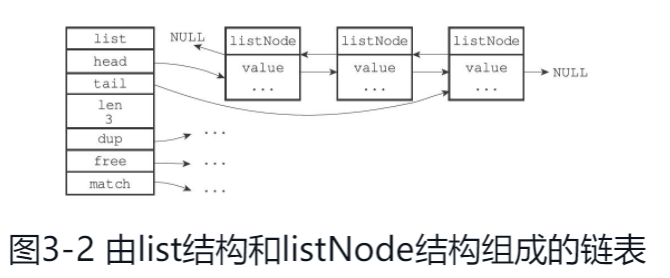
字典
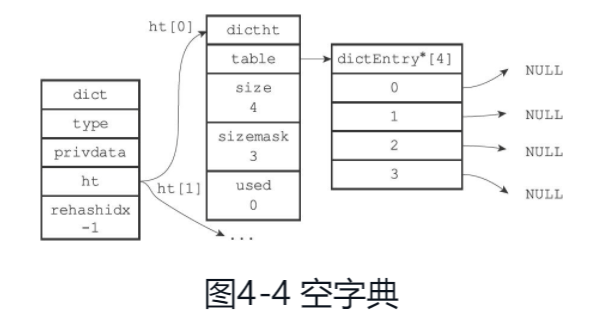
定义如下:
typedef struct dict {
// 类型特定函数
dictType *type;
// 哈希表,dictht中包含了一个size,可以在O(1)时间复杂度内获取大小,还有个dictEntry数组(跟HashMap有点像)
// dictEntry上有key 存键,有*next指针,指向下个哈希表节点,形成链表
dictht ht[2];
// rehash索引
int rehashidx;
//...
}
空字典结构如下:
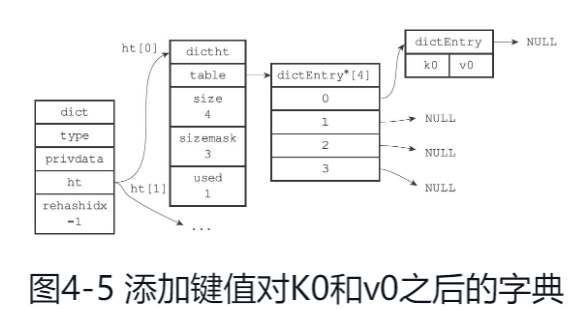
Redis的哈希表使用链地址法(separate chaining)来解决键冲突。每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来,这就解决了键冲突的问题。
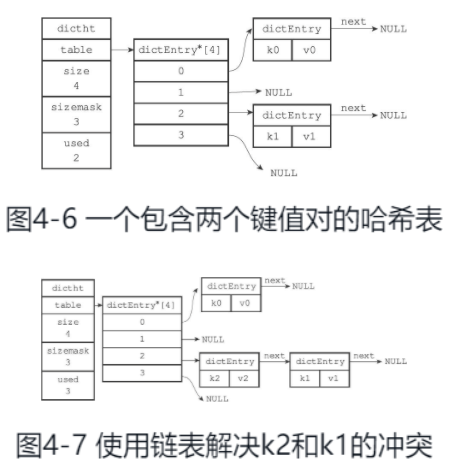
随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(loadfactor)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩(通过rehash来完成)。
rehash步骤如下:
1)为字典的ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及ht[0]当前包含的键值对数量(也即是ht[0].used属性的值):
❑如果执行的是扩展操作,那么ht[1]的大小为第一个大于等于ht[0].used*2的2 n(2的n次方幂);
❑如果执行的是收缩操作,那么ht[1]的大小为第一个大于等于ht[0].used的2 n。
2)将保存在ht[0]中的所有键值对rehash到ht[1]上面:rehash指的是重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
3)当ht[0]包含的所有键值对都迁移到了ht[1]之后(ht[0]变为空表),释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备
何时进行扩展收缩?
当以下条件中的任意一个被满足时,程序会自动开始对哈希表执行扩展操作:
1)服务器目前没有在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于1。
2)服务器目前正在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于5。
当哈希表的负载因子小于0.1时,程序自动开始对哈希表执行收缩操作
为什么这两个负载因子不同?
根据BGSAVE命令或BGREWRITEAOF命令是否正在执行,服务器执行扩展操作所需的负载因子并不相同,这是因为在执行BGSAVE命令或BGREWRITEAOF命令的过程中,Redis需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,从而尽可能地避免在子进程存在期间进行哈希表扩展操作,这可以避免不必要的内存写入操作,最大限度地节约内存。
扩展或收缩哈希表是一次性完成的吗?
扩展或收缩哈希表需要将ht[0]里面的所有键值对rehash到ht[1]里面,但是,这个rehash动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。
渐进式rehash的步骤:
1)为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表。
2)在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash工作正式开始。
3)在rehash进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成之后,程序将rehashidx属性的值增一。
4)随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设为-1,表示rehash操作已完成。
注意:
因为在进行渐进式rehash的过程中,字典会同时使用ht[0]和ht[1]两个哈希表,所以在渐进式rehash进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行.
另外,在渐进式rehash执行期间,新添加到字典的键值对一律会被保存到ht[1]里面,而ht[0]则不再进行任何添加操作,这一措施保证了ht[0]包含的键值对数量会只减不增,并随着rehash操作的执行而最终变成空表
跳跃表(skiplist)
跳跃表支持平均O(logN)、最坏O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
只有两个地方用到了skiplist,一是有序集合键,一是在集群节点中用作内部数据结构。
整数集合(intset)
整数集合(intset)是set的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现。
压缩列表(ziplist)
压缩列表(ziplist)是列表键(list)和哈希键(hash)的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。
存在连锁更新的可能。
要注意的是,尽管连锁更新的复杂度较高,但它真正造成性能问题的几率是很低的:
❑首先,压缩列表里要恰好有多个连续的、长度介于250字节至253字节之间的节点,连锁更新才有可能被引发,在实际中,这种情况并不多见;
❑其次,即使出现连锁更新,但只要被更新的节点数量不多,就不会对性能造成任何影响:比如说,对三五个节点进行连锁更新是绝对不会影响性能的;
Redis 对象
Redis的对象系统还实现了基于引用计数技术的内存回收机制,当程序不再使用某个对象的时候,这个对象所占用的内存就会被自动释放;
另外,Redis还通过引用计数技术实现了对象共享机制,这一机制可以在适当的条件下,通过让多个数据库键共享同一个对象来节约内存;
最后,Redis的对象带有访问时间记录信息,该信息可以用于计算数据库键的空转时长,在服务器启用了maxmemory功能的情况下,空转时长较大的那些键可能会优先被服务器删除.
Redis创建一个KV对的时候,至少会创建两个对象,一个是键对象(总是字符串对象),一个是值对象。
对象的类型与编码
Redis中的每个对象由一个redisObject结构表示
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
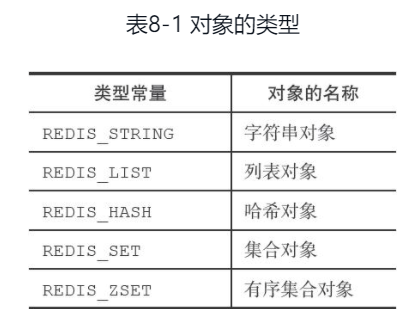
使用type numbers(这里是key)可以找到对应的值类型
对象的编码有如下一些:
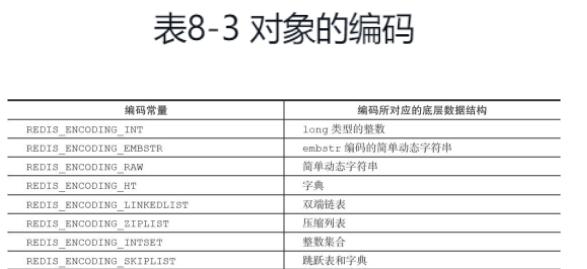
每种类型的对象都至少使用了两种不同的编码
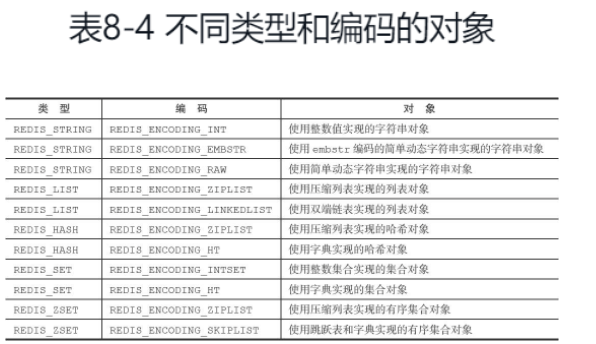
使用object encoding key可以查看对应的编码。

举个例子,在列表对象包含的元素比较少时,Redis使用压缩列表作为列表对象的底层实现:
❑因为压缩列表比双端链表更节约内存,并且在元素数量较少时,在内存中以连续块方式保存的压缩列表比起双端链表可以更快被载入到缓存中;
❑随着列表对象包含的元素越来越多,使用压缩列表来保存元素的优势逐渐消失时,对象就会将底层实现从压缩列表转向功能更强、也更适合保存大量元素的双端链表上面;
STRING 字符串
内部使用SDS(简单动态字符串)结构,可以在O(1)时间内获取字符串的长度。
如果一个字符串对象保存的是整数值,并且这个整数值可以用long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成long),并将字符串对象的编码设置为int.
如果字符串对象保存的是一个字符串值,并且这个字符串值的长度大于32 44字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为raw。而字符串长度小于32 44字节的时候,那么字符串对象将使用embstr编码(是专门用于保存短字符串的一种优化编码方式)的方式来保存字符串值。
另外,可以用long double类型表示的浮点数在Redis中也是作为字符串值来保存的。如果我们要保存一个浮点数到字符串对象里面,那么程序会先将这个浮点数转换成字符串值,然后再保存转换所得的字符串值。在有需要的时候,程序会将保存在字符串对象里面的字符串值转换回浮点数值,执行某些操作,然后再将执行操作所得的浮点数值转换回字符串值,并继续保存在字符串对象里面。

注意:纠正一点,在redis-server版本为6.0.1时,发现字符串长度为44的时候编码还是embstr,45的时候才是raw


常用命令
SET,GET,APPEND,INCREBY,INCREBYFLOAT,DECRYBY, STRLEN
LIST 列表
list对象的编码可以是ziplist或者linkedlist,还有quicklist。
因为是双端链表,所以有什么left,right之分
LPUSH,RPUSH,LPOP,RPOP,LLEN,LREM
SET 集合
集合对象的编码可以是intset或者hashtable
常用命令
SADD, SISMEMBER, SMEMBERS, SPOP, SREM
HASH 散列
哈希对象的编码可以是ziplist或者hashtable
常用命令
HSET, HGET, HEXISTS, HDEL, HLEN, HGETALL
Sorted sets 有序集合
有序集合的编码可以是ziplist或者skiplist.
ziplist编码的压缩列表对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(member),而第二个元素则保存元素的分值(score)。
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表:
typedef struct zset {
zskiplist *zsl;
dict *dict;
}
zset结构中的zsl跳跃表按分值从小到大保存了所有集合元素,每个跳跃表节点都保存了一个集合元素:跳跃表节点的object属性保存了元素的成员,而跳跃表节点的score属性则保存了元素的分值。通过这个跳跃表,程序可以对有序集合进行范围型操作,比如ZRANK、ZRANGE等命令就是基于跳跃表API来实现的。

除此之外,zset结构中的dict字典为有序集合创建了一个从成员到分值的映射,字典中的每个键值对都保存了一个集合元素:字典的键保存了元素的成员,而字典的值则保存了元素的分值。通过这个字典,程序可以用O(1)复杂度查找给定成员的分值,ZSCORE命令就是根据这一特性实现的,而很多其他有序集合命令都在实现的内部用到了这一特性
常用的命令:ZADD, ZCARD(获取跳跃表数据结构的length属性), ZCOUNT, ZRANGE, ZRANK, ZREM, ZSCORE
内存回收
因为C语言并不具备自动内存回收功能,所以Redis在自己的对象系统中构建了一个引用计数(reference counting)技术实现的内存回收机制,通过这一机制,程序可以通过跟踪对象的引用计数信息,在适当的时候自动释放对象并进行内存回收。
object refcount key可以查看对象的引用计数
对象共享
目前来说,Redis会在初始化服务器时,创建一万个字符串对象,这些对象包含了从0到9999的所有整数值,当服务器需要用到值为0到9999的字符串对象时,服务器就会使用这些共享对象,而不是新创建对象
空转时长
object idletime key可以打印key的空转时长,该属性记录了对象最后一次被命令程序访问的时间。
Redis持久化
因为Redis是内存数据库,它将自己的数据库状态储存在内存里面,所以如果不想办法将储存在内存中的数据库状态保存到磁盘里面,那么一旦服务器进程退出,服务器中的数据库状态也会消失不见。
RDB(redis database)
RDB持久化功能,可以将Redis在内存中的数据库状态保存到磁盘里面,避免数据意外丢失。
RDB持久化可以手动执行(一个是save,一个是bgsave命令。save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求;bgsave命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求),也可以根据服务器配置选项定期执行,比如像如下配置:
// 配置代表的意思是,在xx秒内对数据库至少进行了xx次修改
save 900 1
save 300 10
save 60 10000
配置了这个之后,只要满足了任意一个,bgsave命令就会被执行。
相关原理:
服务器状态维持着一个dirty计数器,以及一个lastsave属性:
❑dirty计数器记录距离上一次成功执行SAVE命令或者BGSAVE命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作)。
❑lastsave属性是一个UNIX时间戳,记录了服务器上一次成功执行SAVE命令或者BGSAVE命令的时间
如何检查是否满足的?
有个serverCron函数每隔100ms检查是否满足save选项所设置的保存条件。
RDB文件是什么?
RDB文件是一个经过压缩的二进制文件。
另外值得一提的是,因为AOF文件的更新频率通常比RDB文件的更新频率高,所以:
❑如果服务器开启了AOF持久化功能,那么服务器会优先使用AOF文件来还原数据库状态。
❑只有在AOF持久化功能处于关闭状态时,服务器才会使用RDB文件来还原数据库状态
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
AOF(append only file)
启用AOF的配置:appendonly yes
与RDB持久化通过保存数据库中的键值对来记录数据库状态不同,AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态的
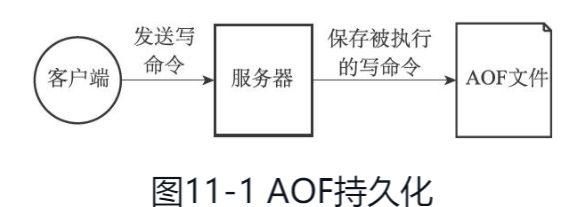
AOF持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤。
当AOF持久化功能处于打开状态时,服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾。
appendfsync选项的值包含如下:默认是everysec

下面这个是个很重要的思想:
为了提高文件的写入效率,在现代操作系统中,当用户调用write函数,将一些数据写入到文件的时候,操作系统通常会将写入数据暂时保存在一个内存缓冲区里面,等到缓冲区的空间被填满、或者超过了指定的时限之后,才真正地将缓冲区中的数据写入到磁盘里面
当然,如果计算机停机的话,那么保存在内存缓冲区里面的写入数据将会丢失。
如何解决?
系统提供了fsync和fdatasync两个同步函数,可以强制让操作系统立即将缓冲区中的数据写入到硬盘里面,从而确保写入数据的安全性。
书中讲述的略微有点不够清晰,一会儿是写入aof文件,一会儿是同步aof文件。看到下面这句才稍微清晰些:
文件写入就是写入到页中,同步则是从页到磁盘。
AOF重写
虽然Redis将生成新AOF文件替换旧AOF文件的功能命名为“AOF文件重写”,但实际上,AOF文件重写并不需要对现有的AOF文件进行任何读取、分析或者写入操作,这个功能是通过读取服务器当前的数据库状态来实现的
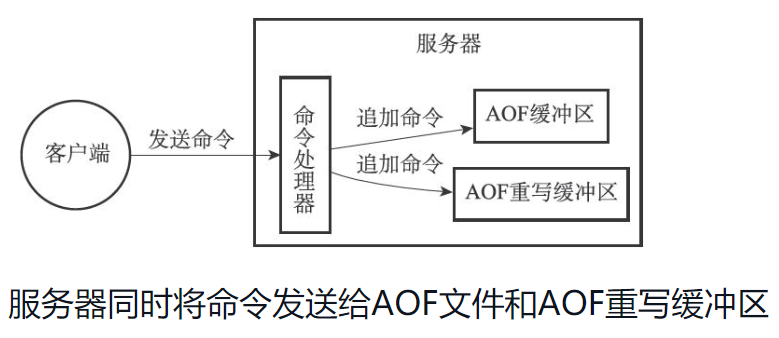
在子进程执行AOF重写期间,服务器进程需要执行以下三个工作:
1)执行客户端发来的命令。
2)将执行后的写命令追加到AOF缓冲区。
3)将执行后的写命令追加到AOF重写缓冲区。
这样一来可以保证:
❑AOF缓冲区的内容会定期被写入和同步到AOF文件,对现有AOF文件的处理工作会如常进行。❑从创建子进程开始,服务器执行的所有写命令都会被记录到AOF重写缓冲区里面。
当子进程完成AOF重写工作之后,它会向父进程发送一个信号,父进程在接到该信号之后,会调用一个信号处理函数,并执行以下工作:
1)将AOF重写缓冲区中的所有内容写入到新AOF文件中,这时新AOF文件所保存的数据库状态将和服务器当前的数据库状态一致。
2)对新的AOF文件进行改名,原子地(atomic)覆盖现有的AOF文件,完成新旧两个AOF文件的替换。
这个信号处理函数执行完毕之后,父进程就可以继续像往常一样接受命令请求了。
官方文档地址: Redis Persistence
Redis provides a different range of persistence options:
- RDB (Redis Database): The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
- AOF (Append Only File): The AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself, in an append-only fashion. Redis is able to rewrite the log in the background when it gets too big.
- No persistence: If you wish, you can disable persistence completely, if you want your data to just exist as long as the server is running.
- RDB + AOF: It is possible to combine both AOF and RDB in the same instance. Notice that, in this case, when Redis restarts the AOF file will be used to reconstruct the original dataset since it is guaranteed to be the most complete.
Redis过期设置
EXPIRE <KEY> <TTL> : 将键的生存时间设为 ttl 秒
PEXPIRE <KEY> <TTL> :将键的生存时间设为 ttl 毫秒
EXPIREAT <KEY> <timestamp> :将键的过期时间设为 timestamp 所指定的秒数时间戳
PEXPIREAT <KEY> <timestamp>: 将键的过期时间设为 timestamp 所指定的毫秒数时间戳.
persist key 移除过期时间
ttl key 查看key还有多长时间过期(ttl: time to live)
缓存驱逐策略(Eviction policies)
参考:Using Redis as an LRU cache
额,看官方文档还是爽。有些文章讲驱逐策略,就列下有哪些就完了,看官方文档给的解释:
Setting
maxmemoryto zero results into no memory limits. This is the default behavior for 64 bit systems, while 32 bit systems use an implicit memory limit of 3GB.When the specified amount of memory is reached, it is possible to select among different behaviors, called policies. Redis can just return errors for commands that could result in more memory being used, or it can evict some old data in order to return back to the specified limit every time new data is added.
有个maxmemory的配置,64位操作系统默认是0,代表没有内存大小限制,32位操作系统是3GB。
当内存到达设置的值的时候,选择的不同的行为,称为“policies”
The exact behavior Redis follows when the
maxmemorylimit is reached is configured using themaxmemory-policyconfiguration directive.具体选择哪种Policy 是看
maxmemory-policy配置的哪种
有如下六种策略(不做翻译了,比较简单)
- noeviction: return errors when the memory limit was reached and the client is trying to execute commands that could result in more memory to be used (most write commands, but DEL and a few more exceptions).
- allkeys-lru: evict keys by trying to remove the less recently used (LRU) keys first, in order to make space for the new data added.
- volatile-lru: evict keys by trying to remove the less recently used (LRU) keys first, but only among keys that have an expire set, in order to make space for the new data added.
- allkeys-random: evict keys randomly in order to make space for the new data added.
- volatile-random: evict keys randomly in order to make space for the new data added, but only evict keys with an expire set.
- volatile-ttl: evict keys with an expire set, and try to evict keys with a shorter time to live (TTL) first, in order to make space for the new data added.
Redis事务
MULTI, EXEC, DISCARD and WATCH are the foundation of transactions in Redis.
这些命令允许一组命令原子的执行,基于如下两个保证:
- All the commands in a transaction are serialized and executed sequentially. It can never happen that a request issued by another client is served in the middle of the execution of a Redis transaction. This guarantees that the commands are executed as a single isolated operation.
就是说所有命令都会被序列化并顺序执行。在事务执行的过程中,不会去响应另一个客户端发起的请求。这确保了这一组命令作为单个隔离的操作。
- Either all of the commands or none are processed, so a Redis transaction is also atomic.所有命令要么全部执行要么都不执行,因此Redis事务是原子的。
如何使用事务呢?
A Redis transaction is entered using the MULTI command. The command always replies with
OK. At this point the user can issue multiple commands. Instead of executing these commands, Redis will queue them. All the commands are executed once EXEC is called.Calling DISCARD instead will flush the transaction queue and will exit the transaction.
拜托,这写的也太清楚了吧!MULTI进入事务,接下来的所有命令都会入队,遇到EXEC命令的时候执行队列里面的所有命令。DISCARD会清空队列并退出事务。
Redis事务为什么不支持回滚(roll backs)?
如果执行某个命令的时候出错了,不会回滚,会继续执行其他的命令。理由如下:
- Redis除非是你程序写错了,比如语法不正确或者对key错误的使用相关的不匹配命令,这些问题应该在开发阶段就被发现,而不是生产阶段
- 牺牲了回滚能力来简化和加速Redis
Redis中的乐观锁,了解下?(Optimistic locking using check-and-set(CAS))
插个题外话,CAS真是叫法各异啊。当你搜索java CAS stands for的时候,得到的是Compare and Swap
WATCH命令用来提供Redis事务的CAS操作。
WATCHed keys are monitored in order to detect changes against them. If at least one watched key is modified before the EXEC command, the whole transaction aborts, and EXEC returns a Null reply to notify that the transaction failed.
wached keys会被监视。如果在执行EXEC命令之前,至少有一个监视的key被修改了,整个事务就会终止,EXEC返回一个Null回复表示事务失败。
Redis主从
通过sync和psync命令实现
比如用docker在某个机器上起了3个redis容器,端口分别为6379, 6380,6381
在6380/6381上分别输入命令slaveof 127.0.0.1 6379这个时候6380和6381都是slave,挂在6379这个master上。
通过info replication可以看到具体的Role等复制情况。
旧版复制功能实现
Redis的复制功能分为同步(sync)和命令传播(commandpropagate)两个操作:
❑同步操作用于将从服务器的数据库状态更新至主服务器当前所处的数据库状态。
❑命令传播操作则用于在主服务器的数据库状态被修改,导致主从服务器的数据库状态出现不一致时,让主从服务器的数据库重新回到一致状态。
从服务器对主服务器的同步操作需要通过向主服务器发送SYNC命令来完成,以下是SYNC命令的执行步骤:
1)从服务器向主服务器发送SYNC命令。
2)收到SYNC命令的主服务器执行BGSAVE命令,在后台生成一个RDB文件,并使用一个缓冲区记录从现在开始执行的所有写命令。
3)当主服务器的BGSAVE命令执行完毕时,主服务器会将BGSAVE命令生成的RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,将自己的数据库状态更新至主服务器执行BGSAVE命令时的数据库状态。
4)主服务器将记录在缓冲区里面的所有写命令发送给从服务器,从服务器执行这些写命令,将自己的数据库状态更新至主服务器数据库当前所处的状态。
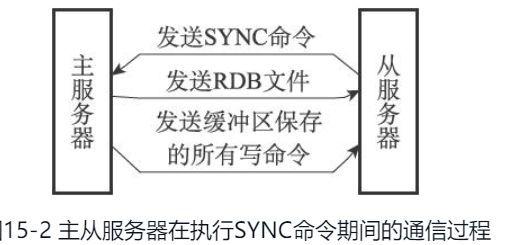
一主一从情况下,初次复制,从将主的RDB文件拷贝没问题;但如果,从断线再重新连接上去,那么此时再将全量RDB拷贝一份,会导致部分不必要数据的拷贝。
其实我们需要的仅仅是,断线期间主所写入的命令。
SYNC命令是一个非常耗费资源的操作每次执行SYNC命令,主从服务器需要执行以下动作:
1)主服务器需要执行BGSAVE命令来生成RDB文件,这个生成操作会耗费主服务器大量的CPU、内存和磁盘I/O资源。
2)主服务器需要将自己生成的RDB文件发送给从服务器,这个发送操作会耗费主从服务器大量的网络资源(带宽和流量),并对主服务器响应命令请求的时间产生影响。3)接收到RDB文件的从服务器需要载入主服务器发来的RDB文件,并且在载入期间,从服务器会因为阻塞而没办法处理命令请求。
新版复制(psync)
PSYNC命令具有完整重同步(full resynchronization)和部分重同步(partial resynchronization)两种模式:
❑其中完整重同步用于处理初次复制情况:完整重同步的执行步骤和SYNC命令的执行步骤基本一样,它们都是通过让主服务器创建并发送RDB文件,以及向从服务器发送保存在缓冲区里面的写命令来进行同步。
❑而部分重同步则用于处理断线后重复制情况:当从服务器在断线后重新连接主服务器时,如果条件允许,主服务器可以将主从服务器连接断开期间执行的写命令发送给从服务器,从服务器只要接收并执行这些写命令,就可以将数据库更新至主服务器当前所处的状态。

部分重同步依赖于三个东西:
❑主服务器的复制偏移量(replication offset)和从服务器的复制偏移量。
❑主服务器的复制积压缓冲区(replicationbacklog)。可以进行调整:2 * second * write_size_per_second例如,如果主服务器平均每秒产生1 MB的写数据,而从服务器断线之后平均要5秒才能重新连接上主服务器,那么复制积压缓冲区的大小就不能低于5MB,安全起见就是10M。
进行全量同步还是增量同步取决于backlog的offset最小是否是从服务器的offset + 1.
假如从的offset为1000,那么如果1001不在积压缓冲区中,比如最小的offset是1200,那说明1001-1200之间的数据丢失了,就需要进行全量同步
❑服务器的运行ID(run ID)。
Redis哨兵(sentinel)
Redis Sentinel(哨兵)主要功能包括主节点存活检测、主从运行情况检测、自动故障转移、主从切换
Redis哨兵提供了Redis的高可用性。
哨兵的能力包括以下方面:
- 监控:哨兵会不间断的监测master和副本实例是否正常工作
- 通知:哨兵可以通过API来通知系统管理员或者其他的电脑程序,有部分被监控的Redis实例出故障了。
- 自动故障转移(Automatic failover):当哨兵发现有个master没正常工作,哨兵可以启动一个故障转移程序,将一个副本提升为master,然后通知其他副本认这个副本为新的master,并通知其他使用redis的应用程序连接时使用这个新的master地址。
- 配置提供者(Configuration provider):大致意思是,客户端会连接上sentinel,问负责某个服务的redis master地址。故障转移发生的时候,哨兵会报告最新的地址。
哨兵的分布式性质
Sentinel本身被设计为在有多个Sentinel进程协同合作的配置中运行。优点如下:
- Failure detection is performed when multiple Sentinels agree about the fact a given master is no longer available. This lowers the probability of false positives.
当某个master不可用的时候,多个sentinel会进行故障检测。这降低了误报的可能性。
- Sentinel works even if not all the Sentinel processes are working, making the system robust against failures. There is no fun in having a failover system which is itself a single point of failure, after all.(即使有部分sentinel挂了,哨兵还是可以正常运行来应对故障。不会出现单点故障的情况。)
最少配置3个哨兵实例,并且这3个实例放在不同的3台计算机或者虚拟机上(避免全部挂了)。监听的端口为26379。docker由于端口映射的关系,破坏了其他哨兵的自动发现和master的副本列表。
sentinel monitor mymaster 127.0.0.1 6379 2
语法是这样的:
sentinel monitor <master-group-name> <ip> <port> <quorum>
这个quorum仅仅是用来标记master是否真正下线的数量。比如上面的2,假如有5个sentinel,如果两个都认为某个master下线了,那么其中一个会尝试进行failover。但只有集群中的大多数(3)个都同意,才会真正开始故障转移。
parallel-syncs这个设置挺有趣的。因为failover会选举一个新的master,其他从服务器需要从新的master来同步数据。如果你设置了1,代表只能一个从服务器同步数据,假如有3台从服务器,那么就需要3次同步了。但是你又不能设置为3,因为虽然同步不会阻塞从服务器执行命令,但是还是可能存在同步新的master的RDB文件时导致的不可用,如果3个从服务器同时同步,那就存在所有从服务器在短时间内不可用的情况了。
主观下线(SDOWN,subjectively down)和客观下线(ODOWN,Objectively Down)
主观下线是一个sentinel发现连不上某个master;如果在is-master-down-after-milliseconds这个时间内没有收到PING的有效回复或者info replication的时候标榜自己为replica,会进入到SDOWN状态。
客观下线是quoram个sentinel认为master SDOWN了。在某个时间范围内当有足够多的sentinel认为master没工作,从SDOWN的状态转为ODWON状态。
Redis cluster
So in practical terms, what do you get with Redis Cluster?
- The ability to automatically split your dataset among multiple nodes.数据自动分片。
- The ability to continue operations when a subset of the nodes are experiencing failures or are unable to communicate with the rest of the cluster.当某些节点不可用时,仍然可以进行某些操作的能力。
使用端口16379
Redis cluster数据分片没有使用一致性hash(consistent hashing),而是使用hash slot。总共有16384个hash槽,给一个key,计算CRC16的值模16384即为keyslot位置。
Redis Cluster没办法保证强一致性,因为使用的是异步复制(这点跟RocketMQ的异步复制还有点像)。比如B有3个从服务器B1,B2,B3,数据写入B,B给客户端就返回了OK,然后才将数据同步给B1,B2,B3.如果B同步之前crash了,其中一个从服务器被提升为master,就会丢失这个写入。
Redis Lua脚本
EVAL script numkeys key [key ...] arg [arg ...]
Atomicity of scripts 脚本的原子性
Redis uses the same Lua interpreter to run all the commands. Also Redis guarantees that a script is executed in an atomic way: no other script or Redis command will be executed while a script is being executed. This semantic is similar to the one of MULTI / EXEC. From the point of view of all the other clients the effects of a script are either still not visible or already completed.
lua脚本保证了原子执行:一个lua脚本执行的时候不会有另外的脚本或者redis命令执行。语义上等同于MULTI/EXEC
However this also means that executing slow scripts is not a good idea. It is not hard to create fast scripts, as the script overhead is very low, but if you are going to use slow scripts you should be aware that while the script is running no other client can execute commands.
上面这段就是说不要执行那些slow script,会对性能有影响,因为慢脚本执行的时候,其他客户端无法执行命令了。
Redis分布式锁
Distributed locks are a very useful primitive in many environments where different processes must operate with shared resources in a mutually exclusive way.
已经有很多类库实现了DLM(Distributed Lock Manager)分布式锁管理器。不过太简单了,Redis分布式锁采用的比较经典的算法Redlock
这里不再详述Redlock。
顺便插一下:分布式锁的实现方式有以下几种
- 基于数据库的唯一索引
- 基于Redis
- 基于zookeeper的临时有序节点
相比之下,这篇更好些:分布式锁(数据库、ZK、Redis)
参考https://juejin.cn/post/6844903830442737671
分布式锁一般有如下的特点:
- 互斥性: 同一时刻只能有一个线程持有锁
- 可重入性: 同一节点上的同一个线程如果获取了锁之后能够再次获取锁
- 锁超时:和J.U.C中的锁一样支持锁超时,防止死锁
- 高性能和高可用: 加锁和解锁需要高效,同时也需要保证高可用,防止分布式锁失效
- 具备阻塞和非阻塞性:能够及时从阻塞状态中被唤醒
再插一句:redis的客户端有Jedis,是阻塞式IO,还有Redisson,底层使用Netty可以实现非阻塞IO。(RocketMQ也使用了Netty,看来什么时候要会会Netty才行啊)
Redisson的lock是通过Lua脚本实现的:
redisson具体的获取和释放锁相关原理可以参考:
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
Redis与其他缓存的区别
| Ehcache | Memacached | Redis | |
|---|---|---|---|
| 底层实现的语言 | Java | C | C |
| 持久化 | yes | no | yes |
| 主数据库模型 | k-v store | k-v store | k-v store(支持多种数据类型) |
| 特点 | 在Java项目广泛的使用。它是一个开源的、设计于提高在数据从RDBMS中取出来的高花费、高延迟采取的一种缓存方案. 够快,被设计于large high concurrency systems 袖珍,一般发布翻倍不会到2M 轻量:只依赖slf4j | memcache 是一种高性能、分布式对象缓存系统,最初设计于缓解动态网站数据库加载数据的延迟性 | 支持RDB、AOF持久化丰富的数据类型高性能replication |
Redis是单线程模型吗?
先来看下这两篇文章:[Improving Redis Performance Through Multi-Thread Processing](https://dzone.com/articles/improving-redis-performance-through-multi-thread-p#:~:text=Redis is generally known as a single-process%2C single-thread,cleansing the dirty data and closing file descriptors.) Redis多线程演进
To make Redis multi-threaded, the simplest way to think of is that every thread performs both I/O and command processing. However, as the data structure processed by Redis is complex, the multi-thread needs to use the locks to ensure the thread security. Improper handling of the lock granularity may deteriorate the performance.
Redis从单线程改为多线程模型,最简单的就是在I/O和命令处理上都采用多线程。但是,由于redis数据结构比较复杂,采用多线程处理命令,你需要加锁,加锁不当可能会降低性能。
We suggest that the number of I/O threads should be increased to enable an independent I/O thread to read/write data in the connections, parse commands, and reply data packets, and still let a single thread process the commands and execute the timer events. In this way, the throughput of a single Redis server can be increased.
因此,建议的是,在I/O那用多线程,但处理命令、返回数据包、执行时间事件还是用单线程。这样的话,Redis服务器的吞吐量就增加了。
单线程的缺点:
- 只有一个CPU核心被使用,多核的客观条件没法充分利用
- 由于10GB/25GB网络适配器的普及,带宽(network bandwitdh)不再是瓶颈。因此,需要考虑的是,如何充分利用多核的优势和网络适配器的性能。
线程模型有三种类型:
- 主线程(Main thread)
- I/O线程
- Worker thread
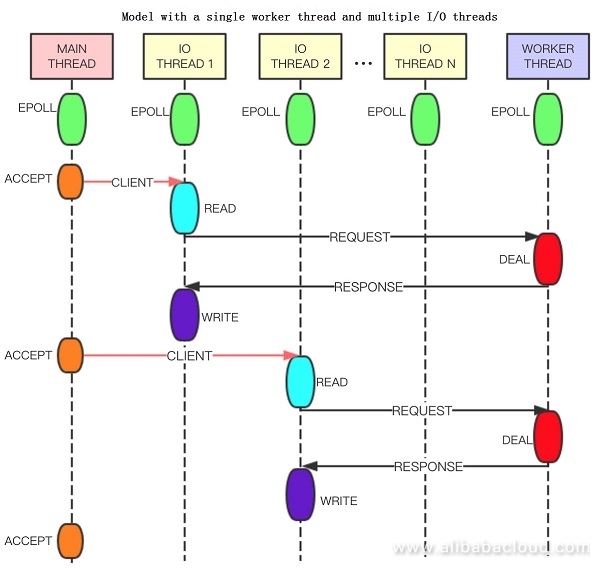
总结下:在处理命令上还是单线程的,在处理I/O那是多线程的。放一个IO多路复用的图。redis采用的是epoll来实现多路复用
缓存与数据库不一致
Redis使用
可以结合Jetcache使用,常见的比如在field上用的@CreateCache, 在方法上用的@Cached,@CachePenetrationProtect注解等。
什么情况下该使用Redis?
Redis为什么一定要用跳表(Skip list)实现有序集合?
跳表使用空间换时间的设计思路,通过构建多级索引来提高查询的效率,实现了基于链表的“二分查找”。
跳表是一种动态数据 结构,支持快速的插入、删除、查找操作,时间复杂度都是O(logn)。
跳表的空间复杂度是O(n)。
不过,跳表的实现非常灵活,可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
虽然跳表的代码实现并不简单,但是作为 一种动态数据结构,比起红黑树来说,实现要简单多了。所以很多时候,我们为了代码的简单、易读,比起红黑树,我们更倾向用跳表。
参考
- 《Redis 设计与实现》
- Redis官方文档:https://redis.io/documentation
- System Properties Comparison Ehcache vs. Memcached vs. Redis