系统准备
Centos6.5
Windows10
相关软件包下载:
链接:https://pan.baidu.com/s/1EOLUphwZgzwSX01HsDJM0g
提取码:1tsf
说明
特别说明: 教程用的主机名分别为master,slave1,slave2 所以发现有出现主机名为 ” spark1”的主机名
等同于 “master”如果如果看见配置文件为spark1,一定要修改成master ;有些图片是后面添加的才出现主机名不一致但并不影响理解.
没有特别说明操作都是在 master 机器操作
关闭防火墙
关闭Linux和Windows的防火墙(防止机器之间应为防火墙拦截而不能连通)
Windows:
window系统: 控制面板 -> 系统和安全 ->Windows Defender 防火墙 -> 启用或关闭Windows Defender 防火墙 -> 关闭Windows Defender 防火墙 //一般只关闭”专用网络设置”的防火墙就行
Linux:
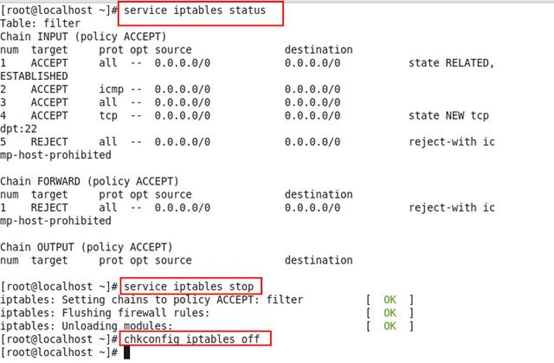
停止防火墙: service iptables stop
启动防火墙: service iptables start
重启防火墙: service iptables restart
永久关闭防火墙: chkconfig iptables off
永久开启防火墙: chkconfig iptables no
查看防火墙状态: service iptables status
查看SELinux状态
getenforce
修改配置文件/etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled

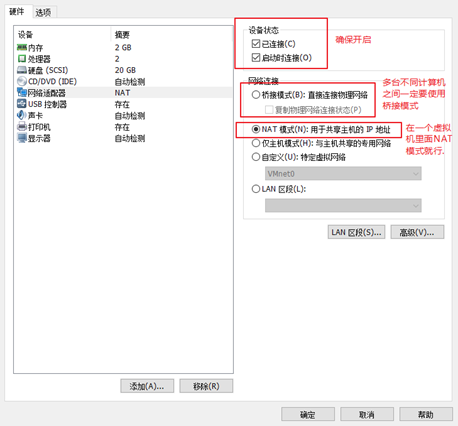
配置网络和静态IP
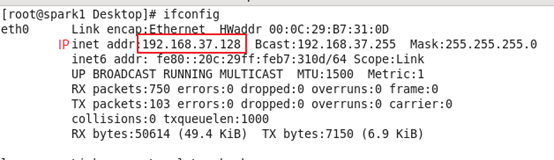
查看自动生成的IP
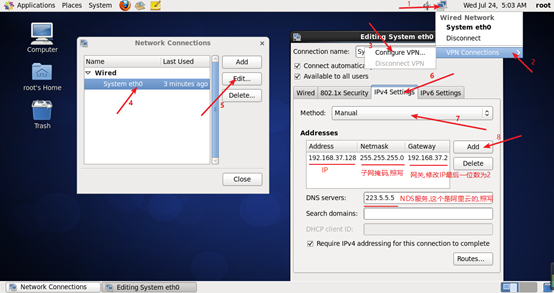
设置静态IP
重启网络服务,并检测dns是否生效

配置IP映射和主机名
更改主机名,便于集群管理(重启才能生效)
vim /etc/sysconfig/network
HOSTNAME=master
修改其他两台主机名分别为 slave1 和 slave2
配置master主机的IP主机映射, 可以将名称映射为对应的IP地址
vim /etc/hosts
192.168.153.101 master
192.168.153.102 slave1
192.168.153.103 slave2
配置SSH免秘钥登录
cd ~/.ssh/
ssh-keygen -t rsa (四次连续回车)
生成 id_rsa(私钥) id_rsa.pub(公钥)
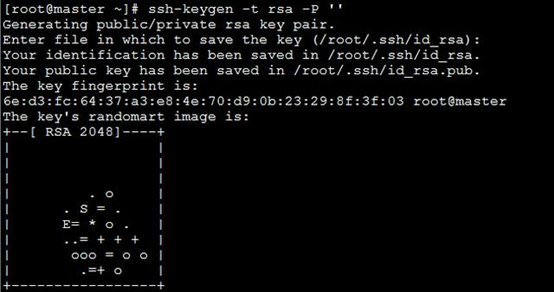
ssh-copy-id master(主机名,需要配好了主机映射)
authorized_keys known_hosts
将另外两台slave1和slave2重复上述操作
复制 另外两台authorized_keys的内容追加到master的authorized_keys里面
最终authorized_keys文件的内容
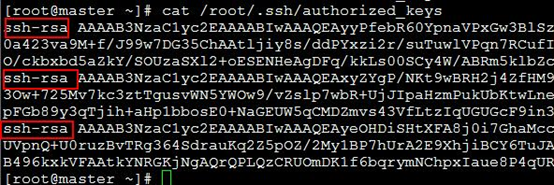
将这个最终的authorized_keys文件copy到其他机器的 /root/.ssh 目录下
scp -r /root/.ssh/authorized_keys root@slave1:/root/.ssh
scp -r /root/.ssh/authorized_keys root@slave2:/root/.ssh
说明:
scp -r(复制文件夹) 本地文件路径 目标用户名@目标主机IP/IP映射的主机名:目标主机的路径
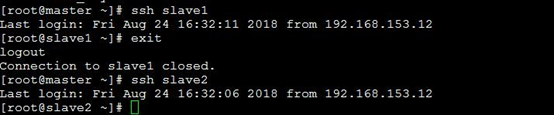
测试免密码登录
ssh slave1
ssh slave2
输入 exit 退出
配置JDK1.8
解压缩jdk安装包
tar -zxvf jdk-8u144-linux-x64.tar.gz
创建目录/opt/java
mkdir /opt/java
移动文件夹jdk1.8.0_144到/opt/java下面,并改名为jdk1.8
mv jdk1.8.0_144/ /opt/java/jdk1.8
配置需要用到的所有环境变量
vim /etc/profile
#Java Config
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
# Scala Config
export SCALA_HOME=/opt/scala/scala2.12.2
# Spark Config
export SPARK_HOME=/opt/spark/spark2.2
# Zookeeper Config
export ZK_HOME=/opt/zookeeper/zookeeper3.4
# HBase Config
export HBASE_HOME=/opt/hbase/hbase1.2
# Hadoop Config
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
# Hive Config
export HIVE_HOME=/opt/hive/hive2.1
export HIVE_CONF_DIR=${HIVE_HOME}/conf
#kafka config
export KAFKA_HOME=/opt/kafka/kafka1.0.0
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:${KAFKA_HOME}/bin:$PATH
刷新环境变量文件,使其立即生效
source /etc/profile
配置Scala2.12.2
tar -zxvf scala-2.12.2.tgz
创建目录/opt/scala
mkdir /opt/scala
移动文件夹scala-2.12.2到/opt/ scala下面,并改名为scala2.12.2
mv scala-2.12.2 /opt/scala/scala2.12.2
配置环境变量(略,前面配过)
source /etc/profile
配置Zookeeper
解压文件
tar -zxvf zookeeper-3.4.10.tar.gz
mkdir /opt/zookeeper
mv zookeeper-3.4.10 /opt/zookeeper/zookeeper3.4
环境变量配置(略,前面配过)
source /etc/profile
创建存放数据的文件夹和文件
mkdir /opt/zookeeper/data
mkdir /opt/zookeeper/dataLog
/opt/zookeeper/data目录下创建myid文件
touch /opt/zookeeper/data/myid
更改myid文件。 我这边为了方便,将master、slave1、slave2的myid文件内容改为1,2,3 这些数字代表的是每一台zookeeper自己的ID
echo 1 >> myid
配置修改zoo.cfg
cd /opt/zookeeper/zookeeper3.4/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeper/dataLog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
配置说明:
client port,顾名思义,就是客户端连接zookeeper服务的端口。这是一个TCP port。
dataLogDir里是放到的顺序日志(WAL)。而dataDir里放的是内存数据结构的snapshot,便于快速恢复。为了达到性能最大化,一般建议把dataDir和dataLogDir分到不同的磁盘上,这样就可以充分利用磁盘顺序写的特性。dataDir和dataLogDir需要自己创建,目录可以自己制定,对应即可。
server.1中的这个1需要和master这个机器上的dataDir目录中的myid文件中的数值对应。server.2中的这个2需要和slave1这个机器上的dataDir目录中的myid文件中的数值对应。server.3中的这个3需要和slave2这个机器上的dataDir目录中的myid文件中的数值对应。当然,数值你可以随便用,只要对应即可。2888和3888的端口号也可以随便用,因为在不同机器上,用成一样也无所谓。
1.tickTime:CS通信心跳数 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。 tickTime=2000 2.initLimit:LF初始通信时限 集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。 initLimit=10 3.syncLimit:LF同步通信时限 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。 syncLimit=5
依旧将zookeeper传输到其他的机器上,记得更改 /opt/zookeeper/data 下的myid,这个不能一致。
将文件复制到其他机器
scp -r /opt/zookeeper root@slave1:/opt
scp -r /opt/zookeeper root@slave2:/opt
需要更改myid文件
启动所有机器的Zookeeper
cd /opt/zookeeper/zookeeper3.4/bin
启动服务
./ zkServer.sh start
查看启动状态,各个机器上zookeeper的leader(主)和follower(从) ,只能一个是主,随机选择
./zkServer.sh status

配置Hadoop HA
Hadoop HA:在Hadoop分布式只有一个master管理的基础上,实现在主master宕机时,设置一个Node在Zookeeper的调度下可以立即顶替master的所有任务。不会应为master宕机导致整个集群瘫痪。
| 主机 | 安装的软件 | 开启的进程 |
|---|---|---|
| spark1 | jdk,hadoop,zookeeper | 7669 DFSZKFailoverController 4261 QuorumPeerMain 7367 NameNode 8362 Jps 8269 ResourceManager |
| slave1 | jdk,hadoop,zookeeper | 8993 NameNode 9585 NodeManager 3765 QuorumPeerMain 9061 DataNode 9143 JournalNode 9726 Jps 9247 DFSZKFailoverController 8339 ResourceManager |
| slave2 | jdk,hadoop,zookeeper | 4996 NodeManager 5141 Jps 3034 QuorumPeerMain 4763 JournalNode 4668 DataNode |
tar -zxvf hadoop-2.8.2.tar.gz
mkdir /opt/hadoop
mv hadoop-2.8.2 /opt/hadoop hadoop2.8
配置环境变量(前面配好了 # Hadoop Config)
source /etc/profile
cd /opt/hadoop/hadoop2.8/etc/hadoop
修改 core-site.xml
vim core-site.xml
在<configuration>节点内加入配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop2.8/data/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>spark1:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>
修改 hadoop-env.sh
export JAVA_HOME=/opt/java/jdk1.8
export HADOOP_CONF_DIR=/opt/hadoop/hadoop2.8/etc/hadoop
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
配置log4j.properties文件
cd /opt/hadoop/hadoop2.8/etc/hadoop
vim log4j.properties
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR

修改 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址,nn1所在地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>spark1:8020</value>
</property>
<!-- nn1的http通信地址,外部访问地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>spark1:50070</value>
</property>
<!-- nn2的RPC通信地址,nn2所在地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>slave1:8020</value>
</property>
<!-- nn2的http通信地址,外部访问地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>slave1:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode日志上的存放位置(一般和zookeeper部署在一起) -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/hadoop2.8/data/journal</value>
</property>
<!--客户端通过代理访问namenode,访问文件系统,HDFS 客户端与Active 节点通信的Java 类,使用其确定Active 节点是否活跃 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--这是配置自动切换的方法,有多种使用方法,具体可以看官网,在文末会给地址,这里是远程登录杀死的方法 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 这个是使用sshfence隔离机制时才需要配置ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间,这个属性同上,如果你是用脚本的方法切换,这个应该是可以不配置的 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- 这个是开启自动故障转移,如果你没有自动故障转移,这个可以先不配 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
修改mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
在<configuration>节点内加入配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>spark1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>spark1:19888</value>
</property>
修改yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name> yarn.resourcemanager.hostname</name>
<value>spark1</value>
</property>
<!--启用resourcemanager ha-->
<!--是否开启RM ha,默认是开启的-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://spark1:19888/jobhistory/logs/</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmcluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>spark1,slave1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.spark1</name>
<value>spark1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.slave1</name>
<value>slave1</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>spark1:2181,slave1:2181,slave2:2181</value>
</property>
<!--启用自动恢复,当任务进行一半,rm坏掉,就要启动自动恢复,默认是false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面。-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<configuration>
说明: yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉
修改slaves
vim /opt/hadoop/hadoop2.8/etc/hadoop/slaves
slave1
slave2
将配置好的文件发送到其他机器
scp -r /opt/hadoop root@slave1:/opt
scp -r /opt/hadoop root@slave2:/opt
启动并测试HA
启动所有机器的zookeeper
初始化Hadoop
/opt/hadoop/hadoop2.8/bin/hdfs namenode -format
注意: 这个操作不能多次使用不然容易造成namdenode 的 namespaceID 与 datanode的namespaceID 不一致,从而导致namenode和 datanode的断连。
解决办法: https://blog.csdn.net/lukabruce/article/details/80277846
启动 hdfs 和 yarn
cd /opt/hadoop/hadoop2.8/sbin
启动hdfs
./start-dfs.sh
启动yarn
./start-yarn.sh
[ 启动所有服务可以使用:./start-all.sh ]
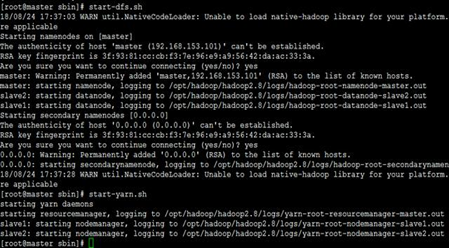
第一次登录会询问是否连接,输入yes ,然后输入密码就可以了 启动成功之后,可以使用jps命令在各个机器上查看是否成功 可以在浏览器输入: ip+50070 和8088端口查看
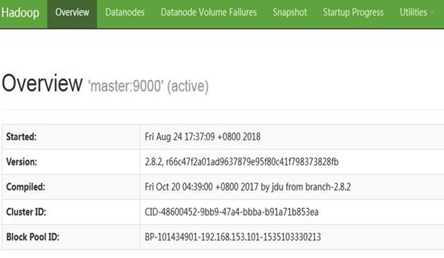
查看hdfs Web管理页面: http://master:50070
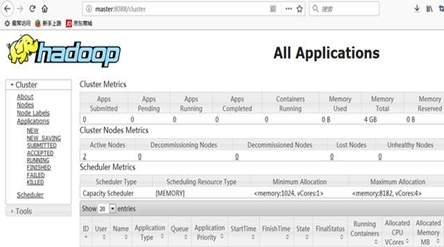
查看Hadoop 的 Application Web管理页面:http://master:8088
注意:
开启服务时: start-all.sh 默认只启动一个ResourceManager另一个需要手动到那台机器的 /opt/hadoop/hadoop2.8/sbin
目录下输入: ./yarn-daemon.sh start resourcemanager
关闭服务时: stop-all.sh 默认只关一个ResourceManager所有也需要手动关闭ResourceManager进程
kill -9 进程ID

配置Spark2.2
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
mkdir /opt/spark
mv spark-2.2.0-bin-hadoop2.7 /opt/spark/spark2.2
环境变量配置(略,前面配过了)
source /etc/profile
修改spark-env.sh
cd /opt/spark/spark2.2/conf/
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export SCALA_HOME=/opt/scala/scala2.12.2
export JAVA_HOME=/opt/java/jdk1.8
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark/spark2.2
export SPARK_MASTER_IP=master
export SPARK_EXECUTOR_MEMORY=4G
修改slaves
mv slaves.template slaves
vim slaves
slave1
slave2
复制文件到其他机器
scp -r /opt/spark root@slave1:/opt
scp -r /opt/spark root@slave2:/opt
启动Spark
cd /opt/spark/spark2.2/sbin
./start-all.sh
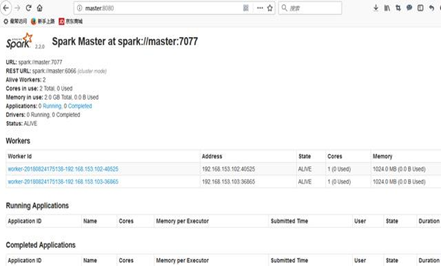
查看Spark Web页面:http://master:8080
配置MySQL5.1.73
卸载已经安装的MySQL
rpm -qa | grep -i mysql

rpm -e mysql-libs-5.1.73-8.el6_8.x86_64;//一般删除,如果提示依赖的其他文件,则不能删除
rpm -e --nodeps mysql-libs-5.1.73-8.el6_8.x86_64;//强力删除,如果有其他依赖文件,则可以对其进行强力删除
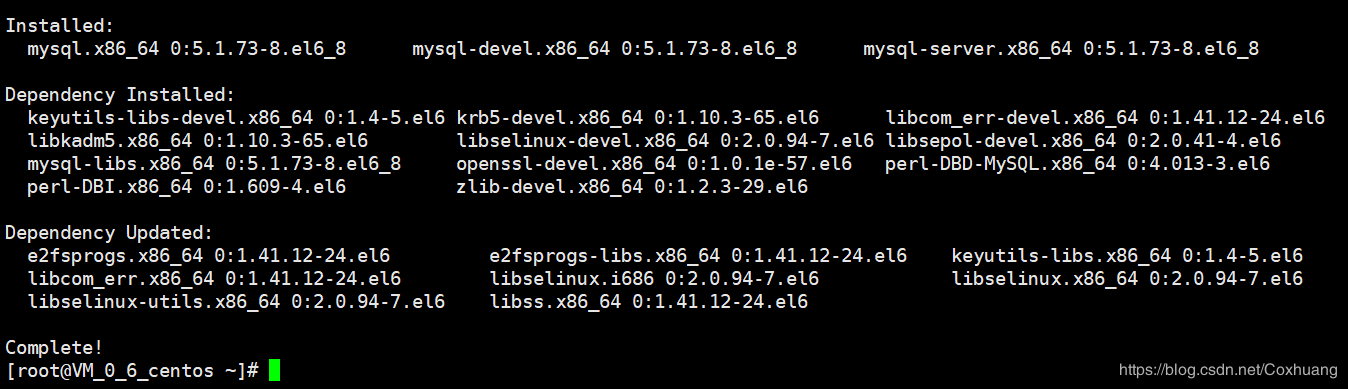
使用yum安装MySQL
yum install -y mysql-server mysql mysql-devel //将mysql,mysql-server,mysql-devel
启动mysql服务
service mysqld start
开机自动启动
chkconfig --list | grep mysqld // 查看是否开机自动启动mysql

mysql -u root -p
解决初始密码问题
ERROR 1045 (28000): Access denied for user 'mysql'@'localhost' (using password: NO)
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
关闭服务
service mysqld stop
启动临时服务
/usr/bin/mysqld_safe --skip-grant-tables
不要关闭这个服务终端
另开一个终端输入
mysql
修改MySQL的root密码为 123456
mysql> use mysql
mysql> update user set password=password("123456") where user="root";
mysql> flush privileges;
mysql> exit
ps -A | grep mysql
4532 pts/0 00:00:00 mysqld_safe
5542 pts/0 00:00:00 mysqld
关闭mysqld服务
kill -9 5542
开启mysqld服务
service mysqld start
登录MySQL
mysql -uroot -p
解决利用sqoop导入MySQL中文乱码的问题(可以插入中文,但不能用sqoop导入中文)
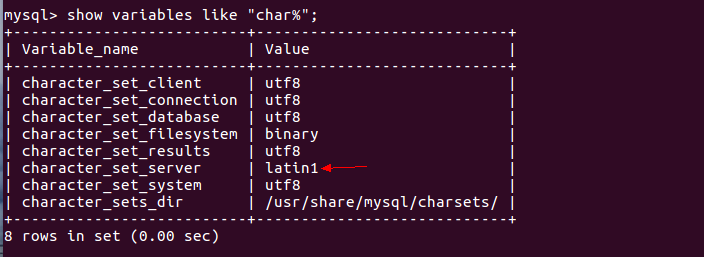
导致导入时中文乱码的原因是character_set_server默认设置是latin1
mysql> show variables like "char%";
临时修改命令
mysql> set character_set_server=utf8;
mysql> quit;
永久修改
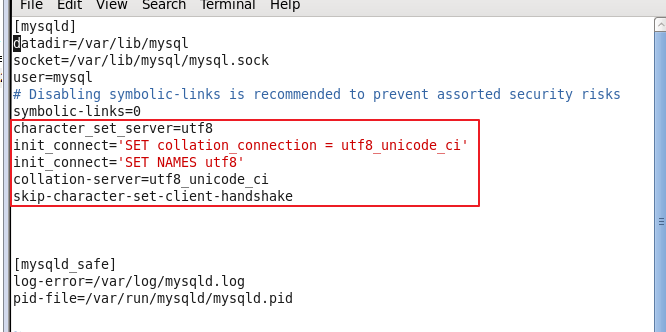
gedit /etc/my.cnf
character_set_server=utf8
init_connect='SET collation_connection = utf8_unicode_ci'
init_connect='SET NAMES utf8'
collation-server=utf8_unicode_ci
skip-character-set-client-handshake
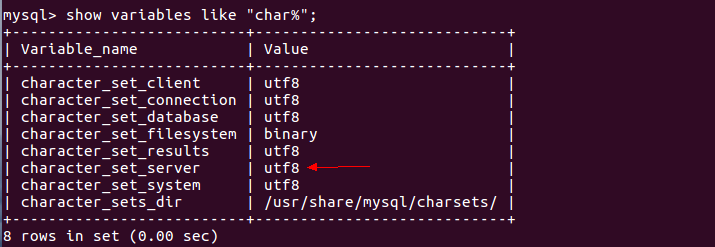
查看编码方式
mysql> show variables like "char%";
配置Hbase
tar -zxvf hbase-1.2.6-bin.tar.gz
mkdir /opt/hbase
mv hbase-1.2.6 /opt/hbase/hbase1.2
配置环境变量(略,前面配过)
source /etc/profile
修改hbase-env.sh
cd /opt/hbase/hbase1.2/conf
vim hbase-env.sh
export JAVA_HOME=/opt/java/jdk1.8
export HADOOP_HOME=/opt/hadoop/hadoop2.8
export HBASE_HOME=/opt/hbase/hbase1.2
export HBASE_CLASSPATH=/opt/hadoop/hadoop2.8/etc/hadoop
export HBASE_PID_DIR=/root/hbase/pids
export HBASE_MANAGES_ZK=false
说明:配置的路径以自己的为准。HBASE_MANAGES_ZK=false 是不启用HBase自带的Zookeeper集群。
修改hbase-site.xml
vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
<description>The directory shared byregion servers.</description>
</property>
<!-- hbase端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!-- 超时时间 -->
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<!--防止服务器时间不同步出错 -->
<property>
<name>hbase.master.maxclockskew</name>
<value>150000</value>
</property>
<!-- 集群主机配置 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<!-- 路径存放 -->
<property>
<name>hbase.tmp.dir</name>
<value>/root/hbase/tmp</value>
</property>
<!-- true表示分布式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定master -->
<property>
<name>hbase.master</name>
<value>master:60000</value>
</property>
</configuration>
修改regionservers
vim regionservers
slave1
slave2
复制到其他机器
scp -r /opt/hbase root@slave1:/opt
scp -r /opt/hbase root@slave2:/opt
启动Hbase
启动Hadoop
启动所有机器的zookeeper
cd /opt/hbase/hbase1.2/bin
./start-hbase.sh
查看Hbase Web页面:http://master:16010/master-status
配置Hive
需要之前安装了MySQL
cd 安装包文件夹目录
tar -zxvf apache-hive-2.1.1-bin.tar.gz
mkdir /opt/hive
mv apache-hive-2.1.1-bin /opt/hive/hive2.1
配置环境变量
vim /etc/profile
# Hive Config
export HIVE_HOME=/opt/hive/hive2.1
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:${KAFKA_HOME}/bin:${SQOOP_HOME}/bin:${FLUME_HOME}/bin:${STORM_HOME}/bin:$PATH
配置hive-site.xml
cd /opt/hive/hive2.1/conf
mv hive-default.xml.template hive-default.xml
vim hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
添加MySQL的jdbc jar包到hive
cd jar包目录
cp mysql-connector-java-5.1.41.jar /opt/hive/hive2.1/lib/
在MySQL里面配置hive的元数据库
service mysql start #启动mysql服务
mysql -u root -p #登陆shell界面
#这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据
mysql> create database hive;
#将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
mysql> grant all on *.* to hive@localhost identified by 'hive';
#刷新mysql系统权限关系表
mysql> flush privileges;
mysql> quit;
start-all.sh #启动hadoop
需要hive元数据库初始化
schematool -dbType mysql -initSchema
#启动hive
hive
配置Kafka
tar -zxvf kafka_2.11-1.0.0.tgz
mkdir /opt/kafka
mv kafka_2.12-1.0.0 /opt/kafka/kafka1.0.0
配置环境变量(略,之前配过)
source /etc/profile
修改server.properties
cd /opt/kafka/kafka1.0.0/config
vim server.properties
broker.id=0 标示符(多台服务器标示符0,1,2,3,...依次增长)
host.name=master 绑定的主机
log.dirs= /opt/kafka/kafka1.0.0/kafka-logs 数据保存的位置
log.retention.hours=168 数据的保留时间
zookeeper.connect=master:2181,slave1:2181,slave2:2181
配置说明:
标示符(多台服务器标示符0,1,2,3,...依次增长)
broker.id=0
绑定的主机
host.name=master
数据保存的位置
log.dirs= /opt/kafka/kafka1.0.0/kafka-logs
数据的保留时间(小时)
log.retention.hours=168
Zookeeper的地址
zookeeper.connect=master:2181,slave1:2181,slave2:2181
复制到其他机器并修改相应文件
scp -r /opt/kafka/ root@slave1:/opt/
修改slave1机器的server.properties文件
broker.id=1
host.name=slave1
修改slave2机器的server.properties文件
broker.id=2
host.name=slave2
启动Kafka
启动Hadoop
启动所有机器的zookeeper
启动所有机器的Kafka服务(服务窗口不用关闭)
nohup /opt/kafka/kafka1.0.0/bin/kafka-server-start.sh /opt/kafka/kafka1.0.0/config/server.properties

创建主题(新开一个终端窗口)
/opt/kafka/kafka1.0.0/bin/kafka-topics.sh --create --zookeeper master:2181,slave1:2181 --replication-factor 1 --partitions 1 --topic chenjian
查看存在的主题
/opt/kafka/kafka1.0.0/bin/kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181
模拟发送数据 master -> slava1
/opt/kafka/kafka1.0.0/bin/kafka-console-producer.sh --broker-list master:9092,slave2:9092 --topic chenjian

消费数据(接收)
kafka-console-consumer.sh --zookeeper master:2181,slave1:2181,slave2:2181 --from-beginning --topic chenjian

配置Sqoop
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
mkdir /opt/sqoop
mv sqoop-1.4.7.bin__hadoop-2.6.0 /opt/sqoop/sqoop1.4.7
配置环境变量
vim /etc/profile
#sqoop config
export SQOOP_HOME=/opt/sqoop/sqoop1.4.7
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:${KAFKA_HOME}/bin:${SQOOP_HOME}/bin:$PATH

source /etc/profi
添加MySQL的Jdbc jar包
cp mysql-connector-java-5.1.41.jar /opt/sqoop/sqoop1.4.7/lib
修改sqoop-env.sh
cd /opt/sqoop/sqoop1.4.7/conf
mv sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/hadoop/hadoop2.8
export HADOOP_MAPRED_HOME=/opt/hadoop/hadoop2.8
export HBASE_HOME=/opt/hbase/hbase1.2
export HIVE_HOME=/opt/hive/hive2.1
测试Sqoop
启动MySQL
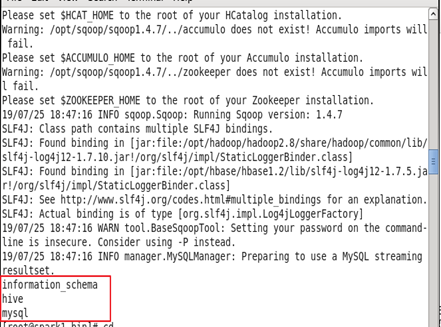
使用Sqoop测试连接MySQL
sqoop list-databases --connect jdbc:mysql://192.168.37.128:3306 --username root --password 123456
配置Flume
tar -zxvf apache-flume-1.8.0-bin.tar.gz
mkdir /opt/flume/
mv apache-flume-1.8.0-bin.tar.gz /opt/flume/flume1.8.0/
配置环境变量
vim /etc/profile
export FLUME_HOME=/opt/flume/flume1.8.0
export FLUME_CONF_DIR=${FLUME_HOME}/conf
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:${KAFKA_HOME}/bin:${SQOOP_HOME}/bin:${FLUME_HOME}/bin:$PATH
source /etc/profile
修改flume-env.sh
cd /opt/flume/flume1.8.0/conf/
mv flume-env.sh.template flume-env.sh
vim flume-env.sh
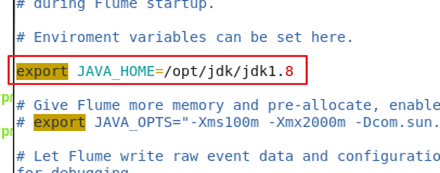
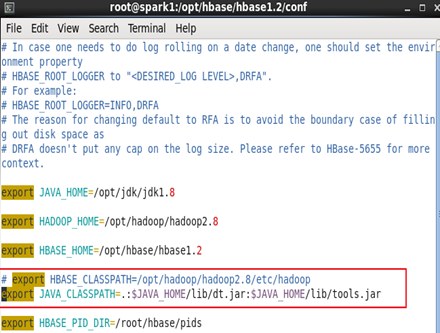
修改Hbase的hbase-env.sh(未出现异常可以忽略)
防止测试会报找不到主类的异常需要配置hbase的hbase-env.sh文件
cd /opt/hbase/hbase1.2/conf
vim hbase-env.sh
注释掉 HBASE_CLASSPATH
export JAVA_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
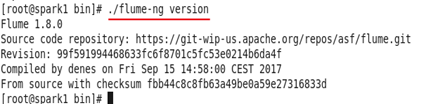
查看Flume配置版本
cd /opt/flume/flume1.8.0/bin
./flume-ng version
测试Flume(avro source)
修改avro.conf
vim /opt/flume/flume1.8.0/conf/avro.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
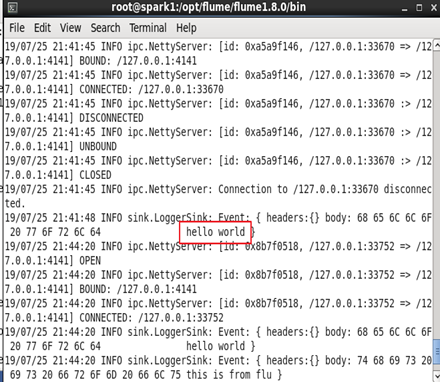
启动flume agent a1
cd /opt/flume/flume1.8.0/bin
#启动日志控制台
flume-ng agent -c . -f /opt/flume/flume1.8.0/conf/avro.conf -n a1 -Dflume.root.logger=INFO,console
向指定文件写入日志
echo "hello world" > /root/log.00
启动avro-client
cd /opt/flume/flume1.8.0/bin
flume-ng avro-client --host localhost -p 4141 -F /root/log.00
在启动的服务控制台查看结果
配置Storm
tar -zxvf apache-storm-0.9.7.tar.gz
mkdir /opt/storm/
mv apache-storm-0.9.7 /opt/storm/storm0.9.7/
配置环境变量
vim /etc/profile
export STORM_HOME=/opt/storm/storm0.9.7
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:${KAFKA_HOME}/bin:${SQOOP_HOME}/bin:${FLUME_HOME}/bin:${STORM_HOME}/bin:$PATH
source /etc/profile
mkdir /opt/storm/storm0.9.7/data
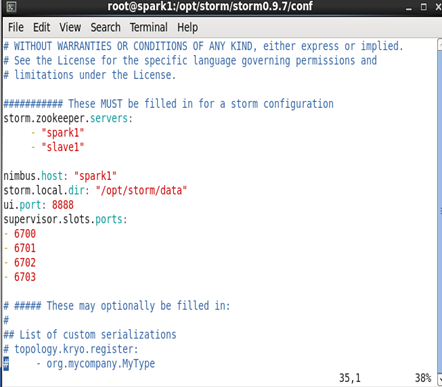
修改storm.yaml
cd /opt/storm/storm0.9.7/conf/
storm.zookeeper.servers:
- "master"
- "slave1"
- "slave2"
nimbus.host: " master "
storm.local.dir: "/opt/storm/data"
ui.port: 8888
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
将文件发送到其他机器
scp -r /opt/storm/ root@slave1:/opt/
scp -r /opt/storm/ root@slave2:/opt/
启动Storm
启动所有机器的Zookeeper
安装顺序执行启动命令
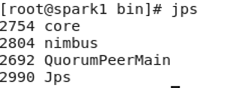
nohup /opt/storm/storm0.9.7/bin/storm ui > /dev/null 2>&1 &
nohup /opt/storm/storm0.9.7/bin/storm nimbus > /dev/null 2>&1 &
jps
在slave1节点执行
nohup /opt/storm/storm0.9.7/bin/storm supervisor > /dev/null 2>&1 &

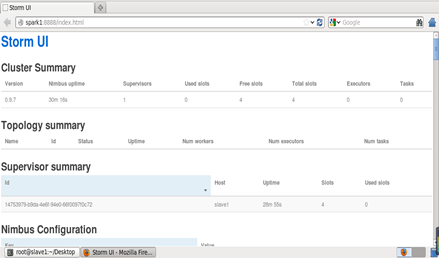
查看Storm Web页面: http://master:8888/index.html
配置Tomcat
- 配置jdk
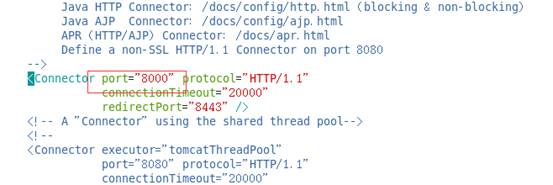
- 修改Tomcat服务端口默认端口8080 (可选操作)
修改将Tomcat服务器启动时使用的端口,例如改成8000
修改完/home/apache-tomcat-7.0.92/conf下的server.xml文件之后,保存退出。
- 启动Tomcat
进入tomcat服务器的/home/apache-tomcat-7.0.92/bin目录,然后执行"./startup.sh"命令启动Tomcat服务器,如下图所示

- 在web页面查看启动页面 http://localhost:8000/
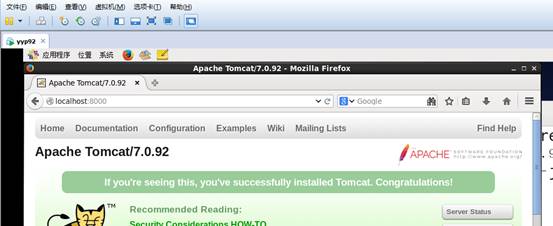
- 其他计算Windows访问Tomcat需要Linux防火墙开放Tomcat的端口
修改文件/etc/sysconfig/iptables,添加一行
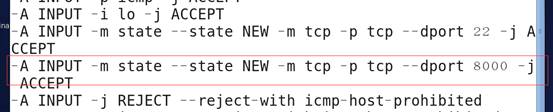
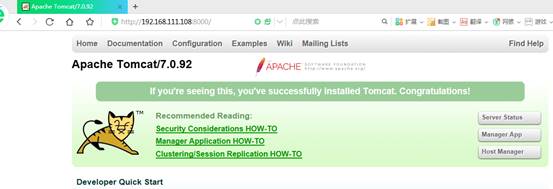
重启防火墙 service iptables restart
在Windows输入 http://192.168.37.130:8000/
- 将网页上传到Tomcat
编辑一个网页 gedit /webPage.html 输入如下内容
<html>
<head>web</head>
<body>
<b>this is my first web page!</b>
</body>
</html>
创建一个文件夹 mkdir /opt/tomcat/tomcat-8.5.43/webapps/testWeb
移动创建网页 mv /webPage.html /opt/tomcat/tomcat-8.5.43/webapps/testWeb
查看网页内容 http://localhost:8000/testWeb/webPage.html
- 设置默认开始网页 (可选操作) https://blog.csdn.net/russ44/article/details/52493531
附录Linux远程操作命令
ssh (执行指令)
ssh 用户名@主机名 “命令”
ssh root@slave2 "ls /; echo info >> /test.txt"
scp (复制文件)
scp 本机文件 用户名@主机名:文件路径
scp /file root@slave2:/home
scp 本机文件 主机名:文件路径
scp -r /directory slave2:/home
scp 主机名:文件路径 本地文件路径
scp -r slave2:/test /home
scp -P 端口号 主机名:文件路径 本地文件路径
scp -P 22 slave2:/test /home
rsync (同步文件信息一致)
rsync -av 本地目录 主机名:目录路径
rsync -av /opt/spark/ slave1:/opt/spark/
参考链接:http://www.360doc.com/content/18/0826/10/11881101_781287955.shtml