1.爬虫三种分类:
通用爬虫:爬取整个页面的数据
聚焦爬虫:爬取经过筛选过滤后的数据,基于一张页面的局部内容.
增量式爬虫:爬虫监测网站更新后的数据,
2.什么是UA检测,如何破解?
UA检测:服务器会用来通过获取请求,通过请求获取请求头中的UA,通过判定UA的值,知道请求的载体身份标识.
将爬虫程序发起请求的信息,伪装成浏览器的请求
UA检测是一种反爬机制,反爬对应的是门户网站,
反反爬策略对应的是爬取程序,破解反爬机制的是反反爬策略
3.简述https的加密流程?
证书秘钥加密:服务器生成公私钥,服务器发送公钥给第三方证书认证机构,认证机构将公钥经过数字签名,作为防伪标识,证书和公钥都会返回给服务器,服务端再发送给客户端,,客户端通过公钥和数字签名验证加密之后,将加密之后的密文传给服务器.
4.什么是动态加载的数据?如何爬取动态加载的数据?
ajax可以动态加载数据,有时候某些东西不是所见即所得,可能是ajax发送的请求数据.
通过抓包工具捕获ajax请求的数据包,将数据包中的url包括参数获取之后,发送请求,返回json串
ajax一般返回的是json串,也可能是其他形式的请求.
5.requests模块中的get和post方法的常用参数及其作用?
url,data,params和headers
6.问题1,IP被封,这个用自己的热点
问题2,页码有问题?50页之后的有问题,通过try..except排除异常
7.化妆品生产许可信息管理系统服务
全局搜索:

选择随便一个包,按下ctrl+F搜索,搜索的内容如下图所示
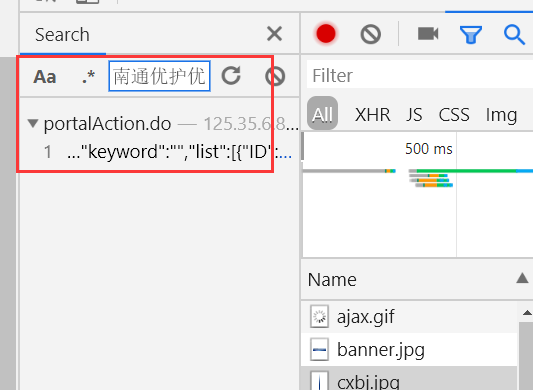
我们看到数据包,就是下图所示的位置:

最好的就是全局搜索,找到对应的搜索包
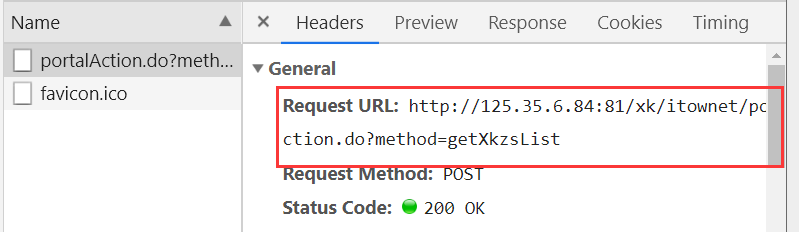
我们看到下图的全局参数:
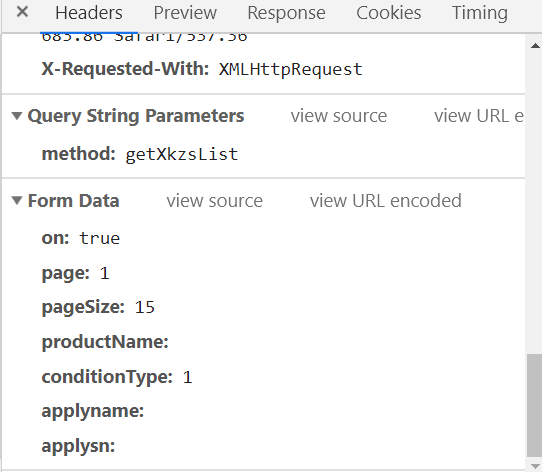
response指代的是响应的数据.

上图是我们响应的json字符串,解析之后,我们看到下图的ID
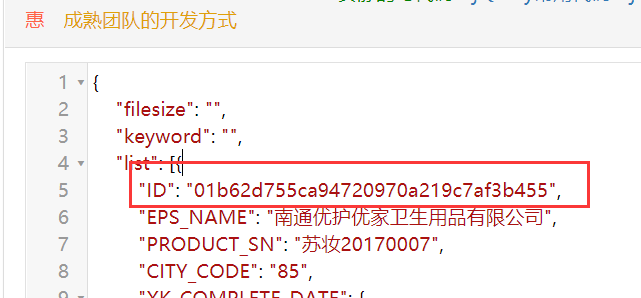
分析:
#搜索的地址:http://125.35.6.84:81/xk/ #Request URL: http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList #Request Method: POST # Content-Type: application/json;charset=UTF-8 #User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36 #Form Data #参数 # on: true # page: 1 # pageSize: 15 # productName: # conditionType: 1 # applyname: # applysn:
分析: (1)通过抓包工具检测出首页中的企业信息数据全部为动态加载 (2)通过抓包工具获取动态加载数据对应的ajax的数据包(url,请求参数) (3)通过对步骤2的url请求后获取的响应数据中分析出有一个特殊的字段ID(每家企业都有一个唯一的ID值) (4)从手动点击企业进入企业的详情页,发现浏览器地址栏中的url中包含了该企业的ID和固定的域名可以拼接成详情页的url (5)发现详情页的企业详情信息对应的数据值是动态加载出来的.上述我们获取详情页中的url是无用的. (6)通过抓包工具的全局搜索的功能,可以定位到企业详情信息对应的ajax数据包(url,请求参数),对应的响应数据就是最终我们想要爬取的企业详细数据. 注意:先写思路,再写程序 程序需要先一点点写,再写出全部. 写一步执行一步.
import requests headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' } #第一请求的url地址 first_url='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList' ids=[] #如何爬取前10页的数据?,双击选中 for page in range(1,11): data={ "on": "true", "page": str(page), "pageSize": "15", "productName": "", "conditionType": "1", "applyname": "", "applysn": "", } #json_obj=requests.post(url=first_url,data=data,headers=headers).json() response=requests.post(url=first_url,data=data,headers=headers) #响应对象 #response.headers返回的是响应头信息(字典) if response.headers['Content-Type']=='application/json;charset=UTF-8': json_obj=response.json() for dic in json_obj['list']: ids.append(dic['ID']) #print(ids) #这个时候我们已经获取到了id detail_url='http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById' for _id in ids: data={ 'id':_id } company_text=requests.post(detail_url,data=data,headers=headers).text print(company_text)
抓取的数据是下面的内容: