1.scrapy的请求传参:
请求传参: - 使用场景:如果使用scrapy爬取的数据没有在同一张页面中,则必须使用请求传参 - 编码流程: - 需求:爬取的是首页中电影的名称和详情页中电影的简介(全站数据爬取) - 基于起始url进行数据解析(parse) - 解析数据 - 电影的名称 - 详情页的url - 对详情页的url发起手动请求(指定的回调函数parse_detail),进行请求传参(meta) meta传递给parse_detail这个回调函数 - 封装一个其他页码对应url的一个通用的URL模板 - 在for循环外部,手动对其他页的url进行手动请求发送(需要指定回调函数==》parse) - 定义parse_detail回调方法,在其内部对电影的简介进行解析。解析完毕后,需要将解析到的电影名称 和电影的简介封装到同一个item中。 - 接收传递过来的item,并且将解析到的数据存储到item中,将item提交给管道
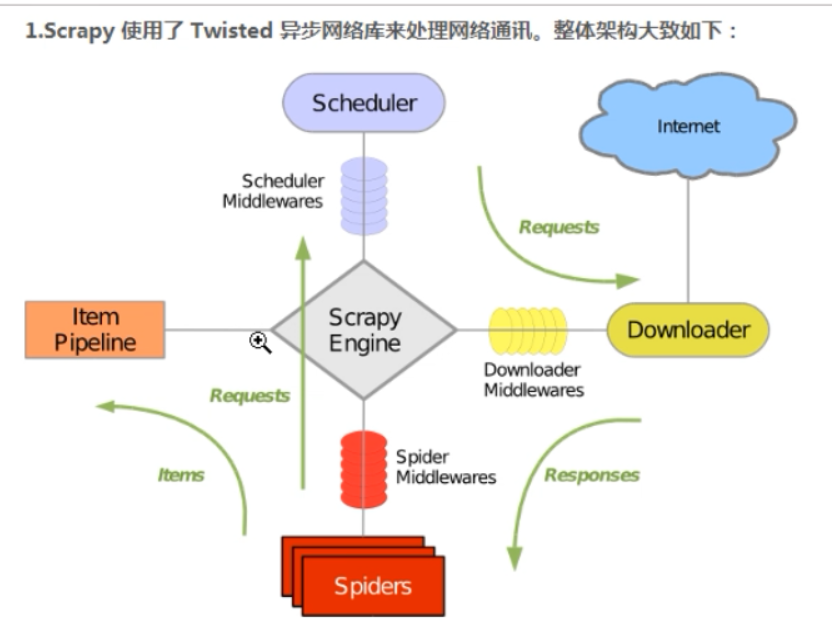
五大组件:所有的数据流都会走"引擎"
"请求对象"
引擎怎么知道什么时间调用什么方法?
引擎:接收所有数据,进行事物的触发
引擎根据接收不同类型的数据流决定下一步触发什么方法.

2.
![]()
上图最后一条修改成下图,加上网址
![]()
settings.py三件套
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
ROBOTSTXT_OBEY = False
LOG_LEVEL='ERROR'
# -*- coding: utf-8 -*- import scrapy class MovieSpider(scrapy.Spider): name = 'movie' # allowed_domains = ['www.xxx.com'] start_urls = ['https://www.4567tv.tv/frim/index1.html'] #爬取电影名称(首页),简介(详情) def parse(self, response): pass
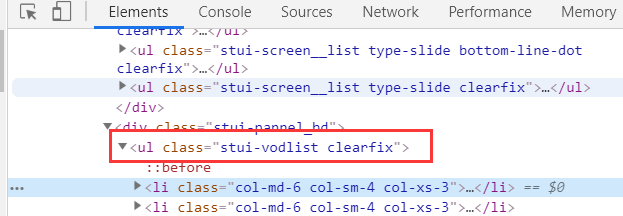
拿取ul的xpath
# -*- coding: utf-8 -*- import scrapy class MovieSpider(scrapy.Spider): name = 'movie' # allowed_domains = ['www.xxx.com'] start_urls = ['https://www.4567tv.tv/frim/index1.html'] #爬取电影名称(首页),简介(详情) def parse(self, response): li_list=response.xpath("/html/body/div[1]/div/div/div/div[2]/ul/li") for li in li_list: name=li.xpath('./div/a/@title').extract_first() detail_url='https://www.4567tv.tv'+li.xpath('./div/a/@href').extract_first() #下面发送请求 #对详情页的url发起get请求 yield scrapy.Request(url=detail_url,callback=self.detail_parse) #解析详情页的页面数据 def detail_parse(self,response): desc=response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
思考,如何写items.py?
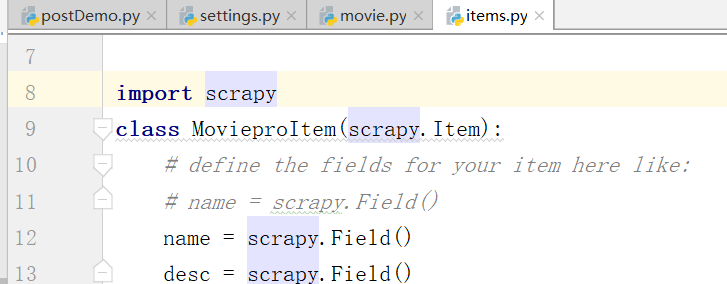
导入上边的文件

movie.py文件
# -*- coding: utf-8 -*- import scrapy from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider): name = 'movie' # allowed_domains = ['www.xxx.com'] start_urls = ['https://www.4567tv.tv/frim/index1.html'] #爬取电影名称(首页),简介(详情) def parse(self, response): li_list=response.xpath("/html/body/div[1]/div/div/div/div[2]/ul/li") for li in li_list: name=li.xpath('./div/a/@title').extract_first() detail_url='https://www.4567tv.tv'+li.xpath('./div/a/@href').extract_first() #item实例化的位置 item=MovieproItem() #通过该meta传递item item['name']=name #对详情页的url发起get请求 #请求传参:meta参数对应的字典就可以传递给请求对象中指定好的回调函数 yield scrapy.Request(url=detail_url,callback=self.detail_parse,meta={'item':item}) #解析详情页的页面数据 def detail_parse(self,response): #回调函数内部通过response.meta就可以接收到请求传参传递过来的字典 item=response.meta['item'] desc=response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first() item['desc']=desc yield item
下面在管道中打印一下item
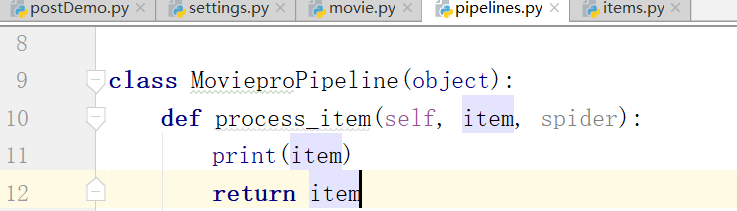
在settings中开启管道

执行一下爬虫文件:

这个时候,我们已经得到了第一页的数据
如何爬取其他页面数据?
# -*- coding: utf-8 -*- import scrapy from moviePro.items import MovieproItem class MovieSpider(scrapy.Spider): name = 'movie' # allowed_domains = ['www.xxx.com'] start_urls = ['https://www.4567tv.tv/frim/index1.html'] #爬取电影名称(首页),简介(详情) #通用的url模板只适用于非第一页 url='https://www.4567tv.tv/frim/index1-%d.html' page=2 def parse(self, response): li_list=response.xpath("/html/body/div[1]/div/div/div/div[2]/ul/li") for li in li_list: name=li.xpath('./div/a/@title').extract_first() detail_url='https://www.4567tv.tv'+li.xpath('./div/a/@href').extract_first() #item实例化的位置 item=MovieproItem() #通过该meta传递item item['name']=name #对详情页的url发起get请求 #请求传参:meta参数对应的字典就可以传递给请求对象中指定好的回调函数 yield scrapy.Request(url=detail_url,callback=self.detail_parse,meta={'item':item}) if self.page<5: new_url=format(self.url%self.page) self.page+=1 yield scrapy.Request(url=new_url,callback=self.parse) #这个地方发起请求,怎样走的下一步的详情页??? #解析详情页的页面数据 def detail_parse(self,response): #回调函数内部通过response.meta就可以接收到请求传参传递过来的字典 item=response.meta['item'] desc=response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first() item['desc']=desc yield item
运行:
这样就得到相应的数据
注意,上边自己调用自己的意思是,重新走了for循环里边的内容
重点内容