1.DataFrame(续)

(1)

(2)
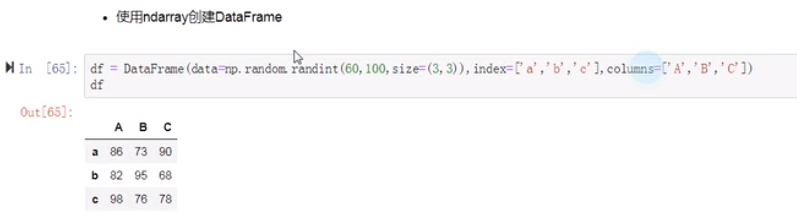
(3)
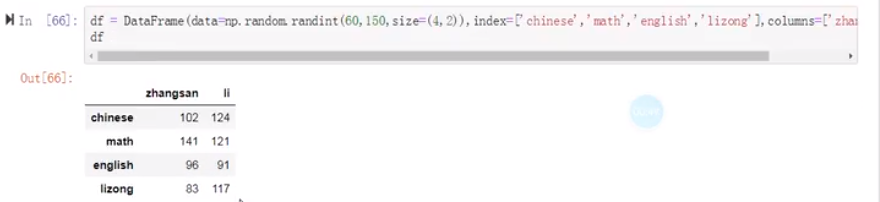
(4)DataFrame的索引

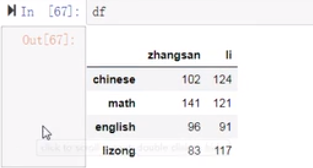
(5)
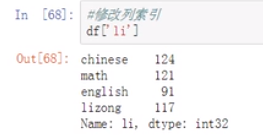
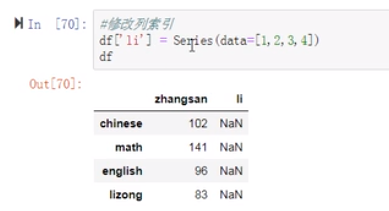
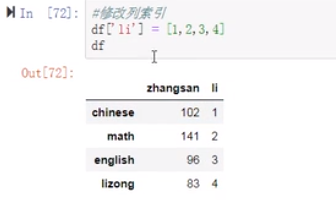
(6)修改列索引
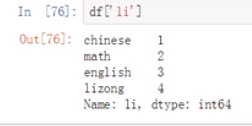
先取出一列
下面这样写会出错,索引的问题出现了NaN
(7)
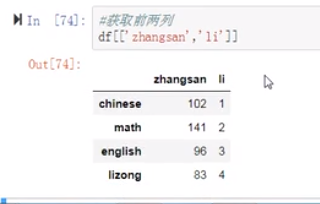
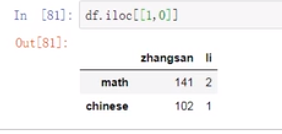
(8)如何取出,前两列?
(9)

(10)

(11)如何取出第一行?
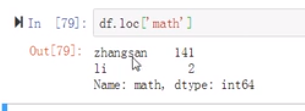
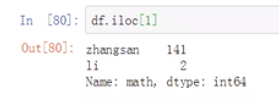
用loc:显式索引
(12)
(13)
(14)
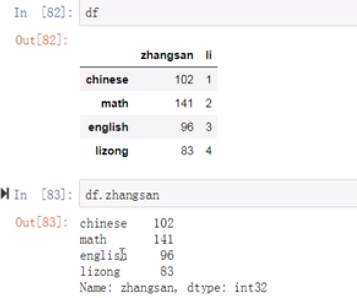

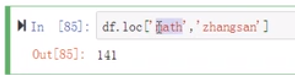
方式:一点点取值
(15)
(16)

切片可以用在行索引
(17)切片也可以用在列索引

(18)
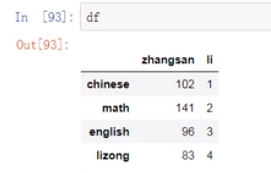
(19)修改索引
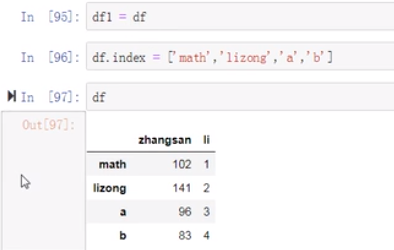
(20)

(21)下面我们copy一下
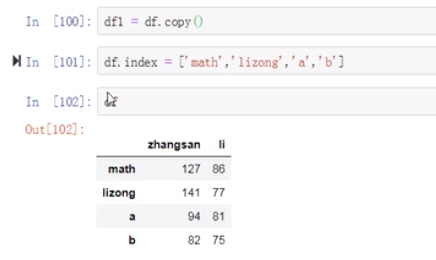
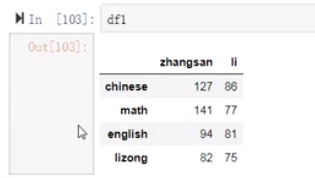
(22)注意:索引对不起会有空值产生
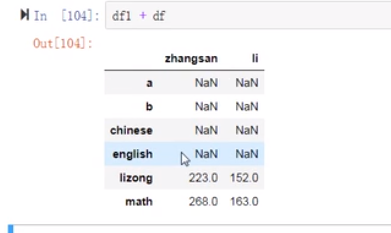
(23)


(24)第一题
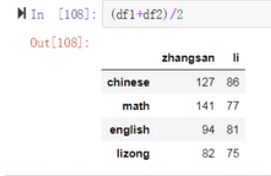
(25)第二题
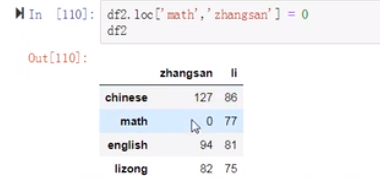
(26)第三题
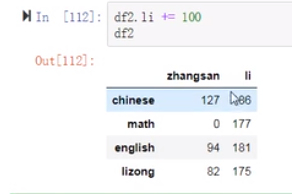
(27)第四题
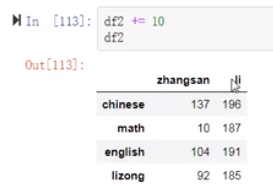
2.处理丢失数据

(1)None空是对象类型
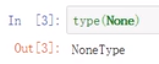
(2)NaN是浮点类型

(3)

index是行索引

(4)
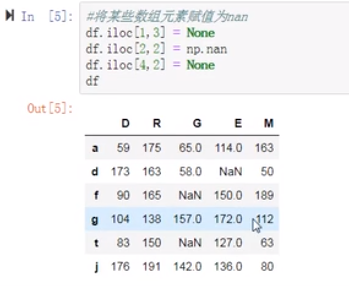
上边的数据,当然是删除有空值的行比较好,或者覆盖也行(用已有的数据进行处理)
(5)下面的方式不合适

对每一个元素进行空值或非空值判断

如果有一个True就可以进行判断了
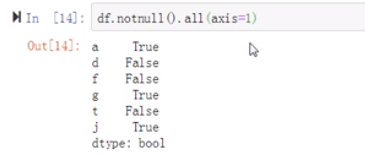
(6)我们需要对每一个元素进行判断
axis中值是1,表示的是行,值是0,表示的是列
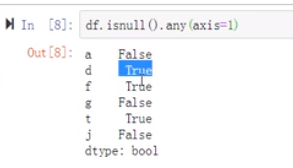
any表示的是其中有一个True,就返回True
(7)
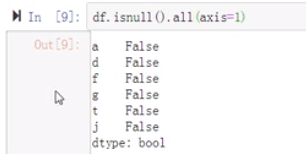
对比any和all的区别?
all是有一个false就返回false
(8)取反操作
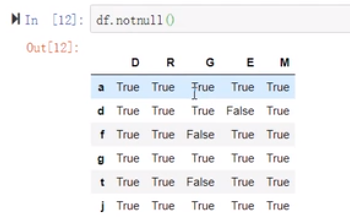
(9)
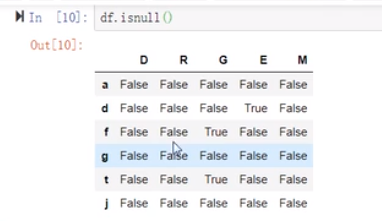
isnull跟any
notnull跟all
(10)
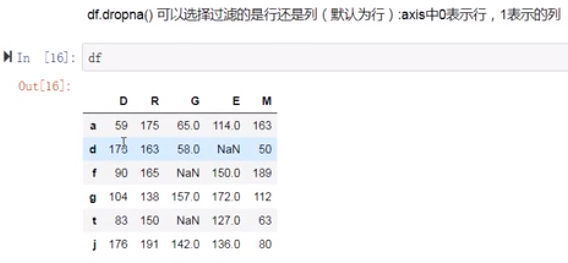
(11)
将含有空值的列删除
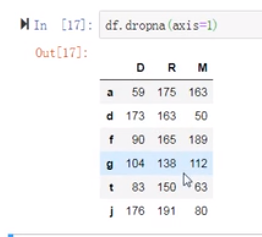
(12)将含有空值的行删除
特点:只有在drop系列的函数中,轴向的参数值0表示的是行,1表示的是列
其他方法是相反的
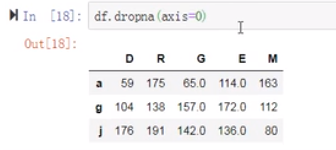
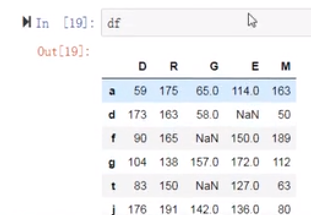
(13)将数据映射回修改好的数据
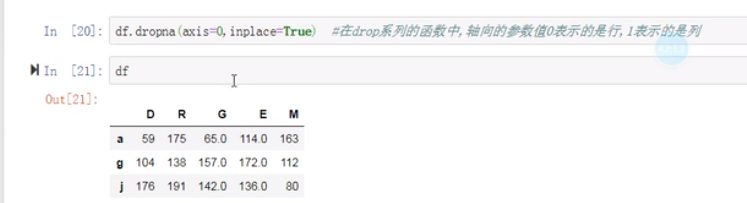
(14)labels看后边的axis的值确定是行索引还是列索引
删除D

(15)

空值都都修改成10,数据误差会比较大

(16)向前填充,向上填充
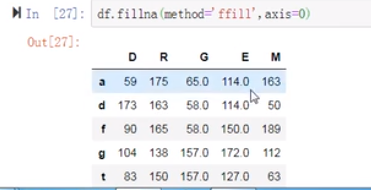
(17)向后填充,向下填充
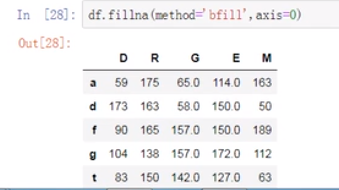
(18)

(19)
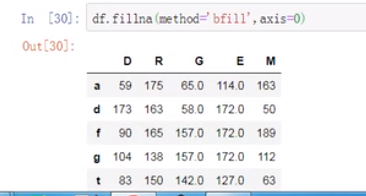
(20)

limit表示限定的次数,知道有这么一个东西就行
(21)
清洗的数据可能是空值或者异常值,我们进行基本的操作.
不是一次性的填充.可以进行多次填充.
(22)

1.pandas中没有区别,numpy是有区别的
None是对象,NaN是浮点型
3.构建多层级索引

最后,记住结论就可以了