参考
https://www.cnblogs.com/ytfcz/p/4507481.html
https://techlog.cn/article/list/10183401
https://learnku.com/articles/20702
https://www.cnblogs.com/cobbliu/p/4311926.html
Debian开启Binary Log
1.在配置文件增加参数
[/etc/mysql/mysql.conf.d/mysqld.cnf]
[mysqld]
log-bin=mysql-bin log-bin-index=mysql-bin.index binlog_format=mixed server-id=10
参数解释
- log-bin--开启binlog日志,日志的命名规范是后面的参数,mysql-bin是前缀。这个参数可以指定目录[/data/mysql/mysql-bin],如果不指定目录存放位置在配置文件中指定的data目录中。
- log-bin-index--binlog索引名字
- binlog_format--指定写入binlog的模式
statement--记录每次运行的sql语句。优点就是日志占用空间少;缺点就是会导致数据不一致。比如使用了uuid()函数,随机产生唯一标识,那么每次运行的结果肯定不一样,就无法达到备份的要求。所以这个排除。
row--记录每次修改的行。这个能保证数据一致,但是缺点就是日志量大。如果执行一条update,更新多条记录,那么日志就会记录多条信息,而不是一条sql语句。
mixed--[推荐]综合了上面的两个优点。如果sql语句不会产生异议,那么就用statement模式记录日志,如果sql语句会产生异议,就用row模式记录。
- server-id--用来主从的时候表示是哪一台服务器,如果仅仅是本地备份开启binlog,也要设置这个参数,不然无法启动binlog。
额外配置
- expire_logs_days=7--binlog过期清理时间
- max_binlog_size=100m--binlog每个日志文件大小,默认为 1G
- binlog_cache_size=4m--binlog缓存大小
- max_binlog_cache_size=512m--最大binlog缓存大小
- binlog_do_db=techlog--指定需要记录binlog的数据库
- binlog_ignore_db=test--指定忽略记录binlog的数据库
2.重启系统或是MySQL服务

我们可以看到,binlog已经有了。
Windows设置注意事项
设置路径的时候log-bin=D:mysqllog/binlog
这里mysqllog是路径,binlog是文件名字缩影,后面的是斜杠,不可以是反斜杠,会被转义
单机恢复实践
1.全量备份
mysqldump -uroot -ppassword --all-databases > dbback1
上面红色的字是需要自己修改的,第一个-u后面当然就是数据库的用户名,-p后面就是前面用户的密码。这样写可以直接写到脚本中,定时运行做增量备份。如果不指定密码,运行完命令后还需要人工手动输入密码,无法达到自动备份。
这里需要注意,可以自己设置需要备份哪些数据库,因为保存账户信息的默认数据库也会备份。这样从服务器会同步到主服务器的用户信息。
遇到的问题
如果你的数据库密码中有特殊字符,会导致上面的语句运行失败。做法就是在特殊字符前面加反斜杠()进行转义。但是这里有一点需要注意,你可能第一次运行,并不知道哪些字符需要转义,所以会出错,出错的现象一般是运行了没结果或是提示--all-databasses cannot found command等莫名其妙的问题。这个时候加了转义字符,也会导致有问题。这个可能是有缓存或是其他问题导致的。可以直接运行mysqldump试一下,理论上会提示你需要增加的参数,如果还是有莫名其妙的错误,那就退出当前ssh,再重新连接即可。
已知的需要转义的特殊字符有&()等。
2.开启Binary Log
3.修改数据
- a.修改前10的uid为123
- b.把id大于2000的uid改成了1111
- c.把id小于3000的uid改为2222
- d.删除3000之前的数据
- e.把所有sign设置为null
4.数据还原
上面d和e是错误操作,我们需要还原到c。
还原之前,暂停数据库的一切操作,把当前的数据库文件备份,以免还原步骤操作失误导致更多的数据丢失。如果不做这一步,就不要进行下面的还原。
4.1 暂停Binary Log
因为还原的时候,对于数据库来说,也是正常的读写操作,所以也会记录下操作日志。这样就使得binlog又记录了一份重复的日志,可以先暂停binlog再还原。
暂停binlog暂时没发现即时关闭的方法,只能通过修改配置文件,注释对应的参数,然后重启mysql服务。
4.2 找到最新一次的全量备份数据进行还原
mysql -uroot -p < dbback1
输入密码。要看清,备份是mysqldump,还原是mysql。这里还原如果遇到unknow command 的错误,那是因为备份的是utf8,还原的终端不是utf8编码,一般出在windows上,这时增加一个参数 --default-character-set=utf8
4.3 查看当前Binary Log信息[可选]
看一下当前binlog是落在哪个文件,好分析,也可以直接在binlog日志目录下,根据修改时间判断,最新的肯定是正在操作的。
查看当前的binlog
show master status
查看有哪些binlog
show binary logs
4.4 从Binary Log还原
- 通过mysqlbinlog导出对应binlog日志
mysqlbinlog mysql-bin.000001 > test
如果信息不详细,可以增加-v的参数
如果遇到这个错误unknown variable 'default-character-set=utf8',增加--no-defaults参数,因为mysqlbinlog无法识别default-character-set=utf8这条语句,忽略掉就可以了。如下
mysqlbinlog --no-defaults mysql-bin.000001 > test
- 找到对应还原点
首先,需要找到全量备份后第一个event id;然后是出错的event id。
因为a是备份后的第一个,所以需要找到a和d对应的event id。
a对应的是10873135,d对应的id是10873735,这个语句是左闭右开的,也就是从正确的位置到错误的位置之前结束。[start-position, stop-position)
- 导出sql语句
mysqlbinlog --start-position=10873135 --stop-position=10873735 mysql-bin.000001 > test.sql
- 还原数据
mysql -uroot -p < test.sql
收尾
数据还原确认没问题后,我们需要做一些收尾工作。
- 重新打开binlog配置[需要重启服务或是系统]
- 全量备份数据
- 清除以前的binlog
- 上线运营
清除binlog的方法
把指定文件之前的日志清除
purge master logs to "mysql-bin.000006"
把指定时间之前的日志清除
purge master logs before '2019-03-29 07:36:40'
把所有的日志清除
reset master
主从配置
上面是单机模式下的备份恢复。为了更加保险,我们可以设置一个备份服务器,把数据通过主从,实时同步过去。
参数设置
从服务器可选参数
这里需要注意,把mysql默认的4个数据库[information_schema mysql performance_schema sys]忽略掉,不然主服务器数据库的用户密码信息会覆盖从服务器的信息。
mysql默认的4个数据库是保存的本地的配置信息,与数据也无关,不需要同步。
#如果从服务器崩溃,防止数据不一致,建议必选 relay_log_recovery=on #从主服务器同步的信息,也写入从服务器binlog,建议必选 log_slave_updates=on
#不同步哪些数据库
replicate-ignore-db=test
#同步哪些数据库
replicate-do-db=order
创建主从账户
从服务器访问主服务器,需要一个账户。可以使用现有的,只要有replication slave权限就可以。为了方便管理,防止相互影响,可以创建一个账户,只有replication slave权限。
这个账户是主服务器上的,在从服务器上登录。因为数据是从主服务器发送到从服务器,所以主服务器不需要知道从服务器是谁,从服务器登录到主服务器,把数据拷贝过来,然后再回放一边。所以从服务器断开,也不会影响主服务器。
创建一个账户repl,所有example.com的子域名都可以访问,密码是password,授予repl账户REPLICATION SLAVE权限。
CREATE USER 'repl'@'%.example.com' IDENTIFIED BY 'password'; GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%.example.com';
备份主库数据
mysqldump --all-databases --master-data > dbdump.db
--master-data的作用是把主库当前所在binlog信息放置进去,用于从库与主库同步。
从服务器还原数据
mysql -uroot -p < dbdump.db
查看主服务器binlog信息
SHOW MASTER STATUS;
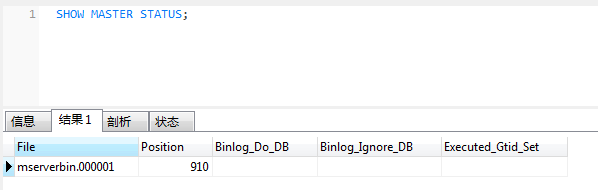
记录下File和Position的信息
设置主服务器信息
在从服务器上,登录mysql,运行
CHANGE MASTER TO MASTER_HOST='192.168.1.199', MASTER_USER='repl', MASTER_PASSWORD='password', MASTER_LOG_FILE='mserverbin.000001', MASTER_LOG_POS=910;
启动主从
start slave;
查看状态
show slave status

看到上面两个参数都是Yes的时候,表示成功。
在主服务器修改数据,可以看到从服务器也修改了,这就表示成功了。
遇到的问题
主从服务器数据都一样后,开启主从的时候,设置主从信息,把主服务器密码设置错误,执行语句并不会报错。开启主从也不会报错。会显示Slave_IO_Running状态是connecting。
这时修改主数据,发现从数据没有修改。
我们再次根据上面的步骤,查看主服务器的binlog信息,关掉从服务器的slave,设置slave信息,开启slave,查看slave状态。两个参数都是Yes,表示这次成功了。但是刚才修改的不一样的数据从服务器并没有与主服务器同步。
主服务器再次修改那条信息,信息同步了。
也就是slave开启后,主从只负责把当前的操作到从服务器上回放一遍,并不确保之前数据是一样的,所以开启主从之前要先拷贝数据,确保主从数据完全一致。
其他
主从同步之后,就算从服务器关掉,主服务器在这之间修改了数据,从服务器重新打开的时候,也会再次自动连接,并且把之前的数据都同步过来。