近期在工作中遇到某表某字段是可扩展数据内容,信息以逗号分隔生成的,现需求要根据此字段数据在其它表查询相关的内容展现出来,第一想法是切割数据,以逗号作为切割符,以下为总结的实现方法,以供大家参考、指教。
1、regexp_substr函数,通过正则来拆分字符串,函数用法为:(必须是oracle 10g+的版本才支持)
REGEXP_SUBSTR函数格式如下:
function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
__srcstr :需要进行正则处理的字符串
__pattern :进行匹配的正则表达式
__position :起始位置,从第几个字符开始正则表达式匹配(默认为1)
__occurrence :获取第几个分割出来的组(分割后最初的字符串会按分割的顺序排列成组),默认为1
__modifier :模式('i'不区分大小写进行检索;'c'区分大小写进行检索。默认为'c'。)针对的是正则表达式里字符大小写的匹配
-------------------------------------------------------------------------------------------------------------------

此函数只能每次取一个字符串出来,有点鸡肋,字符串中逗号的数量是不确定的,如果有2个逗号,需要提取的字段就是3个。为了确定有多少个需要提取的字段,需要用到connect by命令实现动态参数构造连续的值,通过原字符串长度和被替换后字符串长度相减,可以得到原字符串中的逗号数量,加1后得到需要提取的匹配字段数量。
SQL:
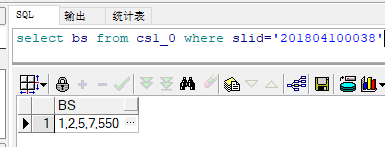
select bs from cs1_0 where slid='201804100038' --正则分割后的第一个值 SELECT REGEXP_SUBSTR((select bs from cs1_0 where slid='201804100038'),'[^,]+',1,1,'i') as 分割后结果 FROM DUAL; --获取一个多个数值的列,从而能够让结果以多行的形式展示出来 SELECT LEVEL FROM DUAL CONNECT BY LEVEL <=5; --将上面REGEXP_SUBSTR的occurrence(标识第几个匹配组)实现动态参数,使用 connect by组合起来 SELECT REGEXP_SUBSTR((select bs from cs1_0 where slid='201804100038'),'[^,]+',1,LEVEL,'i') as 分割后结果 FROM DUAL CONNECT BY LEVEL <=5; --优化一下(动态获匹配组标识行数) select regexp_substr((select bs from cs1_0 where slid='201804100038'),'[^,]+',1,LEVEL,'i') as 分割后结果 from dual connect by level <= length((select bs from cs1_0 where slid='201804100038'))-length(regexp_replace((select bs from cs1_0 where slid='201804100038'),',',''))+1;
2、以Type类型和function函数的方式实现
1)建立TYPE类型 CREATE OR REPLACE TYPE strsplit_type_12 IS TABLE OF VARCHAR2 (4000)
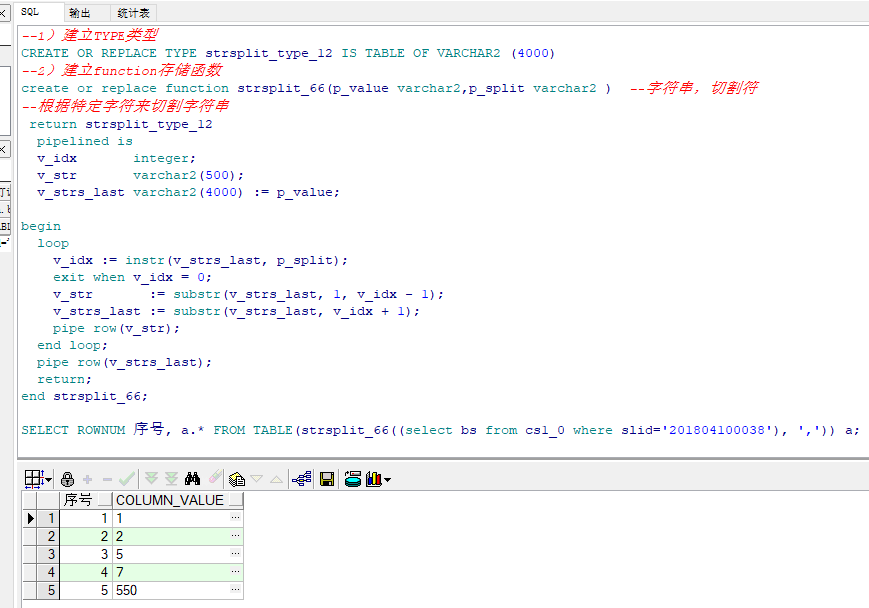
2)建立function存储函数 create or replace function strsplit_66(p_value varchar2,p_split varchar2 ) --字符串,切割符 --根据特定字符来切割字符串 return strsplit_type_12 pipelined is v_idx integer; v_str varchar2(500); v_strs_last varchar2(4000) := p_value; begin loop v_idx := instr(v_strs_last, p_split); exit when v_idx = 0; v_str := substr(v_strs_last, 1, v_idx - 1); v_strs_last := substr(v_strs_last, v_idx + 1); pipe row(v_str); end loop; pipe row(v_strs_last); return; end strsplit_66; SELECT ROWNUM 序号, a.* FROM TABLE(strsplit_66((select bs from cs1_0 where slid='201804100038'), ',')) a;
测试一下: