1. 概念简介
与字节缓冲流BufferedInputStream和BufferedOutputStream对应的,我们还有字符缓冲流BufferedReader和BufferedWriter,顾名思义,它们是带有字符缓冲区的字符输入输出流,原理跟字节缓冲流一样,这两个流也是使用装饰模式对底层字符流进行了包装,并通过字符缓冲区来提高I/O效率,这里不再详细说明。唯一需要注意的是,相对于它们的父类,则两个流分别都新增了一些自己的方法,如下所示:
- BufferedReader新增方法:
String readLine() throws IOException
该方法一次性从输入流中读取一行数据,返回包含该行内容的字符串,不包含任何行终止符,如果已到达流末尾,则返回 null。
- BufferedWriter新增方法:
void newLine() throws IOException
该方法向输出流中写入一个行分隔符。行分隔符字符串由系统属性 line.separator 定义,并且不一定是单个新行 (' ') 符。
2. 字符缓冲流应用示例
下面是两个流的使用示例,代码实现将数据从源文件3.txt复制到目标文件4.txt的功能:
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; public class BufferedCharsTest { public static void main(String[] args) { BufferedReader br = null; BufferedWriter bw = null; try { br = new BufferedReader(new FileReader("./src/res/3.txt")); bw = new BufferedWriter(new FileWriter("./src/res/4.txt")); String str = null; while(null != (str = br.readLine())) { //每次读取一行 bw.write(str); bw.newLine(); //手动添加换行符 bw.flush(); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if(null != bw) { try { bw.close(); } catch (IOException e) { e.printStackTrace(); } } if(null != br) { try { br.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
代码运行效果:

注:用上面的代码, 源文件和目标文件都必须是GBK编码的才行,如果两者编码不一致,或者即使两者都是UTF-8编码的,也会出现乱码,如下所示:
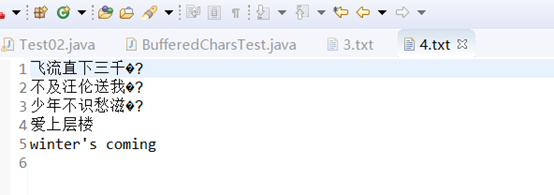
原因就是前面在介绍FileReader时所说的那样,是由于FileReader只能以平台默认的字符集GBK来解码数据,FileWriter只能以平台默认字符集来编码数据,因此只要任何一方不是GBK编码的,就会导致乱码,这是需要注意的一点。