安装tensorflow
Ubuntu 下 pycharm 安装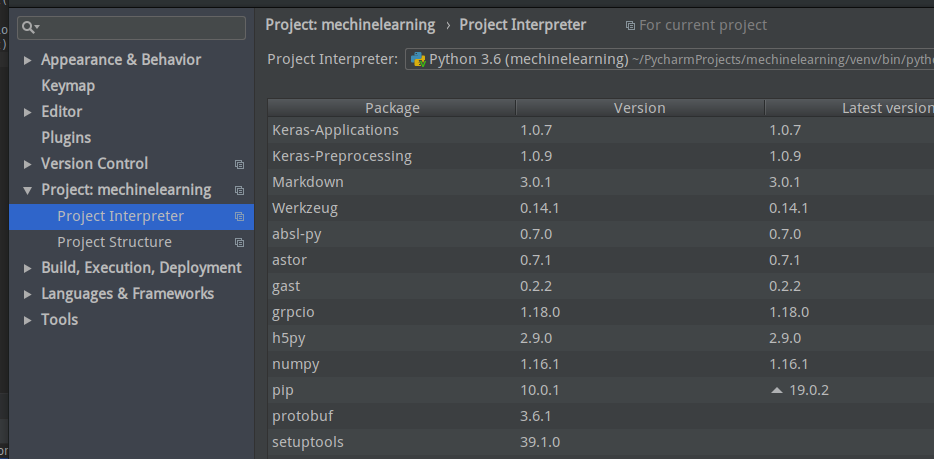
点击最右边加号, 选择Tensorflow 然后点击install ok 完成
使用测试代码 检查是否安装成功 定义两个常量(tf.constant) 然后将其相加 要输出相加结果 需要生成一个session来计算
import tensorflow as tf a = tf.constant([1.0,2.0], name = 'a') b = tf.constant([2.0,3.0], name="b") result = a+b sess = tf.Session() print(sess.run(result))
结果出现错误
/home/sun/PycharmProjects/mechinelearning/venv/bin/python /home/sun/PycharmProjects/mechinelearning/ch2/test.py 2019-02-09 17:59:38.627974: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA Process finished with exit code 0
当前的CPU可以支持未编译为二进制的指令AVX2 消除此提示 添加两行代码
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
运行结果
计算模型
计算图:
Tensorflow名字中包含两个重要的概念——Tensor和Flow。Tensor代表张量的意思,可以简单理解成多维数组,表明了他的数据结构。Flow则体现了它的计算模型,直观地表示了张量之间通过计算相互转化的过程。TensorFlow是一个通过计算图的形式来表述计算的编程系统。TensorFlow中每一个计算都是计算图的一个节点,而节点之间的边表示计算之间的依赖关系

add依赖于a和b的运算 所以有两条指向add的边
在Tensorflow程序中,系统会自动维护一个默认的计算图,通过tf.get_default_graph函数可以获取当前默认的计算图
print(a.graph is tf.get_default_graph())
通过graph属性可以查看张量所属的计算图,因为上述代码没有特意指定 所以应该输出 True
除了使用默认的计算图,TensorFlow支持通过tf.Graph函数生成新的计算图。不同计算图上的张量和运算都不会共享
以下代码展示如何在不同计算图上定义和使用变量
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' g1 = tf.Graph() with g1.as_default(): #在计算图g1中定义变量"v",并设置初始值为0. v = tf.get_variable("v",shape=[1],initializer=tf.zeros_initializer) g2 = tf.Graph() with g2.as_default(): # 在计算图g2中定义变量"v",并设置初始值为1. v = tf.get_variable("v",shape=[1],initializer=tf.ones_initializer) #在计算图g1中读取变量"v"的取值 with tf.Session(graph=g1) as sess: tf.global_variables_initializer().run() with tf.variable_scope("",reuse=True): #在计算图g1中,变量"v"的取值应该为0 所以下面这行会输出[0.]。 print(sess.run(tf.get_variable("v"))) # 在计算图g2中读取变量"v"的取值 with tf.Session(graph=g2) as sess: tf.global_variables_initializer().run() with tf.variable_scope("", reuse=True): # 在计算图g1中,变量"v"的取值应该为1 所以下面这行会输出[1.]。 print(sess.run(tf.get_variable("v")))
上面代码产生了两个计算图每个计算图定义了一个名字为“v“的变量,g1将v初始化为0,g2将v初始化为1,运行不同计算图时,变量v的值也是不一样的。
Tensorflow中的计算图不仅仅可以隔离张量和计算,还提供管理张量和计算的机制。计算图可以通过tf.Graph.device函数指定运行计算的设备,比如可以跑在GPU上
g = tf.Graph()
#指定运行的设备 with g.device('/gpu:0'): result =a +b
张量Tensor
从功能角度上看,张量可以被简单理解为多维数组。其中零阶张量表示标量,也就是一个数。第一阶张量为向量,也就是一个一维数组,第n阶张量可以理解为一个n维数组。但张量在Tensorflow中的实现并不是直接采用数组的形式,只是对Tensorflow中运算结果的引用,在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。
比如如下代码 并不会得到加法的结果 而会得到对结果的一个引用。
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' a = tf.constant([1.0,2.0], name='a') b = tf.constant([2.0,3.0], name="b") result = tf.add(a,b, name="add") print(result)
输出

Tensorflow计算的结果不是一个具体的数字,而是一个张量的结构。主要保存三个属性:名字(name) 维度(shape)和类型(type)
张量的第一个属性名字不仅是一个张量的唯一标识符,也给出了这个张量是如何计算出来的。由于Tensorflow的计算都是通过计算图的模型来建立,而计算图上每一个节点代表一个计算,计算的结果都保存在张量中。所以张量和计算图上的节点所代表的计算结果是对应的,这样张量的命名就可以通过"node:src_output"的形式来给出。其中node为节点的名称,src_output表示当前张量来自节点的第几个输出。比如上面结果”add:0"就说明result、这个张量是计算节点"add"输出的第一个结果(编号从0开始)
张量的第二个属性是张量的维度shape,这个属性描述了一个张量的维度信息。上面列子shape = (2,)说明张量result是一个一维数组,这个数组的长度为2
张量的第三个属性是类型type,每一个张量都会有一个唯一的类型。Tensorflow会对参与运算的所有张量进行类型的检查,发现类型不匹配时会报错
以下是一个类型不匹配报错的
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' a = tf.constant([1.0,2.0], name='a') b = tf.constant([2,3], name="b")#如果改成 b = tf.constant([2,3], name="b",dtype = tf.float32) 就不会报错
result = tf.add(a,b, name="add") print(result)
张量的用途
- 是对中间计算结果的引用,当一个计算包含很多中间结果时,使用张量可以提高代码可读性
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' #使用张量记录中间结果 a = tf.constant([1.0,2.0], name='a') b = tf.constant([2.0,3.0], name="b") result =a + b #直接计算向量的和 result = tf.constant([1.0,2.0], name='a') + tf.constant([2.0,3.0], name="b")
- 当计算图构造完成,张量可以用来获得计算结果,也就是得到真实的数字,虽然没有存储 但通过session会话就可以得到这些具体的数字 上述代码可以使用tf.Session().run(result)语句来得到计算结果
会话session
Tensorflow中的会话session来执行定义好的运算。会话拥有并管理Tensorflow程序运行时的所有资源。当所有计算完成之后需要关闭回话来帮助系统回收资源,否则就可能出现资源泄露的问题。Tensorflow中使用会话的模式一般有两种:
- 需要明确调用会话生成函数和关闭会话函数,这种代码的流程如下:
#创建一个会话 sess = tf.Session() #使用这个创建好的会话来得到关心的运算的结果 sess.run(...) #关闭会话 释放资源 sess.close()
使用这种模式,需要明确调用close函数关闭会话并释放资源,然后程序因为异常而退出时,关闭会话的函数可能就不会执行导致资源泄露
- 为了解决异常退出时资源释放的问题 Tensorflow可以通过Python的上下文管理器来使用会话
#创建一个会话,并通过python上下文管理器来管理这个会话 with tf.Session() as sess: #使用这个创建好的会话来得到关心的运算的结果 sess.run(...) #不需要再用session.close()函数来关闭会话 #当上下文退出时会话关闭和资源释放也自动完成了
在交互式环境下,通过设置默认会话的方式来获取张量的取值更加方便。通过使用函数tf.InteractiveSession函数会自动将生成的会话注册为默认会话
sess = tf.InteractiveSession()
print(result.eval())
sess.close()
无论使用哪个方法都可以通过ConfigProto Protocol Buffer来配置需要生成的会话
config = tf.ConfigProto(allow_soft_placement = True, log_device_placement = True) sess1 = tf.InteractiveSession(config=config) sess2 = tf.Session(config = config)
通过ConfigProto可以配置类似并行的线程数、GPU分配策略、运算超时时间等参数
第一个参数 allow_soft_placement = True时在以下任意一个条件成立时 GPU的运算可以放到CPU上运行,可以程序在拥有不同数量的GPU机器上顺利运行:
- 运算无法在GPU上运行
- 没有GPU资源
- 运算包含对CPU计算结果的引用
第二个参数 log_device_placement 当他为True时日志中将会记录每个节点被安排在哪个设备上以方便调试。而在生产环境中将这个参数设置为False可以减少日志量