NumPy简介
Numpy提供了一个在Python中做科学计算的基础库,重在数值计算,主要用于处理多维数组(矩阵)的库。用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多。本身是由C语言开发,是个很基础的扩展,Python其余的科学计算扩展大部分都是以此为基础。
高性能科学计算和数据分析的基础包
ndarray,多维数组(矩阵),具有矢量运算能力,快速、节省空间
矩阵运算,无需循环,可完成类似Matlab中的矢量运算
线性代数、随机数生成
1、创建数组的3种方法
import random
import numpy as np
# numpy是帮助我们进行数值型计算的
a = np.array([1,2,3,4,5])
print(a) # [1 2 3 4 5]
print(type(a)) # <class 'numpy.ndarray'>
b = np.array(range(1,6))
print(b)
print(type(b))
c = np.arange(1,6)
print(c)
print(type(c))
# dtype:查看数组中数据的类型
print(c.dtype) # int64,默认是根据电脑位数来的
# 指定生成的数据类型
d = np.array([1,1,0,1],dtype=bool)
print(d) # [ True True False True]
# numpy中的小数
e = np.array([random.random() for i in range(4)])
print(e) # [0.8908038 0.4591454 0.38334215 0.08534364]
print(type(e)) # <class 'numpy.ndarray'>
print(e.dtype) # float64
# 取数据的几位小数
f = e.round(2) # 或者 f = np.round(e,2)
print(f) # [0.92 0.27 0.07 0.94]
2、数组的形状
import numpy as np
# 数组的形状
a = np.array([[1,3,4],[3,5,6]])
print(a)
"""
二维数组
[[1 3 4]
[3 5 6]]
"""
print(a.shape) # (2,3),代表着2行3列的数组
b = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
print(b)
"""
三维数组
[[[1 2 3]
[4 5 6]]
[[1 2 3]
[4 5 6]]]
"""
print(b.shape) # (2, 2, 3)
# 由于上面这种写法(几维数组)过于复杂
c = np.arange(12) # 生成一个一维数组
d = np.reshape(c,(3,4)) # 将1维数组转变成3*4的二维数组
print(d)
"""
3*4的二维数组
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
"""
e = np.arange(24)
f = e.reshape((2,3,4))
print(f)
"""
2*3*4的三维数组,其中2表示块数,3行4列
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
"""
# 三种方式将3维数组f,转成1维数组
g = f.reshape((24,)) # 一定要有, f.reshape((1,24))也行
h = f.reshape((f.shape[0]*f.shape[1]*f.shape[2],))
i = f.flatten()
print(g)
print(h)
print(i)
3、数组的计算
import numpy as np
# 数组的计算
a = np.array([i for i in range(12)])
b = a.reshape((3,4)) # 2维数组
print(b)
"""
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
"""
print(b+2)
"""
numpy会将数组中的所有元素+2,+—*/同理,下面看一个特殊的
[[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]
"""
# print(b/0)
"""
在numpy中,/0并不会报错,其中nan(not a number)代表未定义或不可表示的值,inf(infimum)表示无穷
[[nan inf inf inf]
[inf inf inf inf]
[inf inf inf inf]]
"""
# 两个相同结构的数组的+——*/
c = np.array([1,2,3,4])
d = np.array([5,6,7,8])
e = c.reshape((2,2))
f = d.reshape((2,2))
print(e+f)
"""
e:
[[1 2]
[3 4]]
f:
[[5 6
[7 8]]
e+f:
[[ 6 8]
[10 12]]
"""
# 因为行的维度两个数组是相同的,所以会对每一行进行+——*/运算
# 多维中有一个(或以上)维度相同的话就可以进行计算
# 所有维度都不相同,无法进行计算
4、加载csv数据
"""
加载csv数据
"""
us_file_path = "./youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "./youtube_video_data/GB_video_data_numbers.csv"
"""
fname:文件路径
delimiter:数据分隔符(默认为空格)
dtype:数据类型
skiprows:跳过多少行
usecols:选取指定的列(元组类型)
unpack:是否转置
"""
aaa = np.loadtxt(fname=us_file_path,delimiter=",",dtype=int)
5、转置操作
a = np.array([i for i in range(12)])
b = a.reshape((3,4))
print(b)
"""
转置的3中方法
转置:2维数组的行和列交换
"""
print(b.T)
print(b.transpose())
# 交换0轴和1轴
print(b.swapaxes(1,0))
6、取行/列
"""
取行/列
"""
# 取第3行
print(b[2])
# 取连续的多行(2~4行)
print(b[1:4])
# 取不连续的多行(1、3行)
print(b[[0,2]])
# 取第2列
print(b[:,1])
# 取连续的多列(1~3列)
print(b[:,0:3])
# 取不连续的多列(1,3列)
print(b[:,[0,2]])
# 取行列交叉的点(3行4列)
c = b[2,3]
print(c)
print(type(c))
#取多行和多列,取第3行到第五行,第2列到第4列的结果
#去的是行和列交叉点的位置
print(b[2:5,1:4])
#取多个不相邻的点
#选出来的结果是(0,0) (2,1) (2,3)
print(b[[0,2,2],[0,1,3]])
7、布尔索引、三元运算、裁剪
"""
numpy中的布尔索引
"""
print(b)
"""
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
"""
print(b>5)
"""
[[False False False False]
[False False True True]
[ True True True True]]
"""
# Demo:将数组中>5的值改成5
print(b[b>5]) # [ 6 7 8 9 10 11]
b[b>5] = 5
"""
numpy中的三元运算
"""
# b中小于4的==>0,大于等于4的==>10
c = np.where(b<4,0,10)
# 注意:不会修改b,而是有一个返回值
print(c)
"""
numpy中的裁剪
"""
# 小于10的替换成10,大于18的替换成18
b.clip(10,18)
8、numpy中的nan和inf
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan:
当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷
什么时候回出现inf包括(-inf,+inf)
比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)
注意点:
inf和nan都是float类型

那么问题来了,在一组数据中单纯的把nan替换为0,合适么?会带来什么样的影响?
比如,全部替换为0后,替换之前的平均值如果大于0,替换之后的均值肯定会变小,所以更一般的方式是把缺失的数值替换为均值(中值)或者是直接删除有缺失值的一行
那么问题来了:
如何计算一组数据的中值或者是均值
常用的统计函数
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极值:np.ptp(t,axis=None) 即最大值和最小值只差
标准差:t.std(axis=None)
默认返回多维数组的全部的统计结果,如果指定axis则返回一个当前轴上的结果
Demo:将数组中的nan替换成平均值
import numpy as np
def fill_ndarray(t1):
# 对每列进行操作
for i in range(t1.shape[1]):
# 获取当前列
temp_col = t1[:,i]
# 判断这列中有没有nan
nan_number = np.count_nonzero(temp_col!=temp_col)
if nan_number > 0:
# 获取当前列中不为nan的数组
temp_not_nan_col = temp_col[temp_col==temp_col]
# 找出nan,替换成平均值,或temp_col(np.isnan(temp_col)) = temp_not_nan_col.mean()
temp_col[temp_col!=temp_col] = temp_not_nan_col.mean()
return t1
if __name__ == '__main__':
t1 = np.arange(24).reshape((4, 6)).astype("float")
# 将第二行的3列以后赋值为nan
t1[1, 2:] = np.nan
t2 = fill_ndarray(t1)
print(t2)
更多好用方法
获取最大值最小值的位置
np.argmax(t,axis=0)
np.argmin(t,axis=1)
创建一个全0的数组: np.zeros((3,4))
创建一个全1的数组: np.ones((3,4))
创建一个对角线为1的正方形数组(方阵):np.eye(3)
numpy中的copy和view
=b 完全不复制,a和b相互影响
a = b[:],视图的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管,他们两个的数据变化是一致的,
a = b.copy(),复制,a和b互不影响
生成随机数

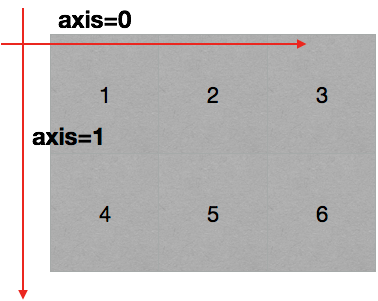
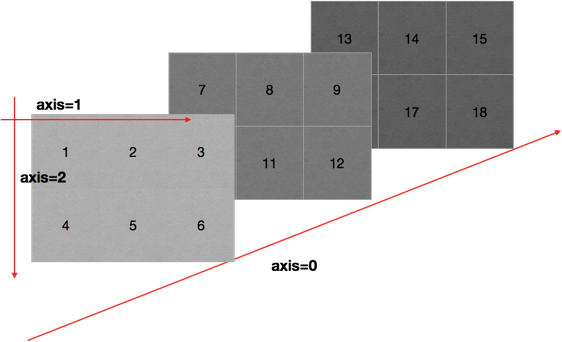
轴