懒加载&嵌套映射
前言:
基于动态代理实现懒加载,在使用过程中,如果会话关闭、跨线程、序列化等情况下,是否能够继续加载?
懒加载
懒加载是为改善,解析对象属性时大量的嵌套子查询的并发问题。设置懒加载后,只有在使用指定属性时才会加载,从而分散SQL请求。
<resultMap id="blogMap" type="blog" autoMapping="true">
<id column="id" property="id"></id>
<association property="comments" column="id" select="selectCommentsByBlog" fetchType="lazy"/>
</resultMap>
在嵌套子查询中指定 fetchType="lazy" 即可设置懒加载。在调用getComments时才会真正加载。此外调用:"equals", "clone", "hashCode", "toString" 均会触发当前对象所有未执行的懒加载。通过设置全局参数aggressiveLazyLoading=true ,也可指定调用对象任意方法触发所有懒加载。
| 参数 | 描述 |
|---|---|
| lazyLoadingEnabled | 全局懒加载开关 默认false |
| aggressiveLazyLoading | 任意方法触发加载 默认false。 |
| fetchType | 加载方式 eager实时 lazy懒加载。默认eager |
set覆盖 &序列化
当调用setXXX方法手动设置属性之后,对应的属性懒加载将会被移除,不会覆盖手动设置的值。
当对象经过序列化和反序列化之后,默认不在支持懒加载。但如果在全局参数中设置了configurationFactory类,而且采用JAVA原生序列化是可以正常执行懒加载的。其原理是将懒加载所需参数以及配置一起进行序列化,反序列化后在通过configurationFactory获取configuration构建执行环境。
configurationFactory 是一个包含 getConfiguration 静态方法的类
public static class ConfigurationFactory { public static Configuration getConfiguration() { return configuration; } }
原理
通过对Bean的动态代理,重写所有属性的getXxx方法。在获取属性前先判断属性是否加载?然后加载之。
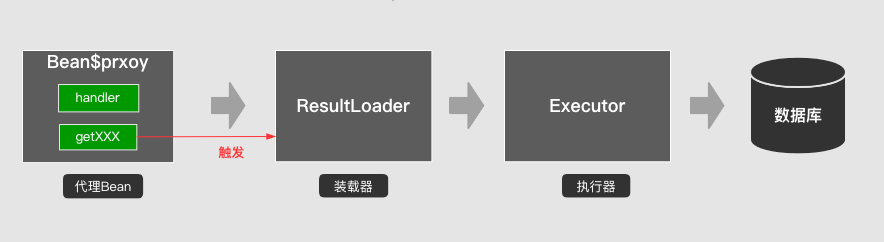
内部结构:
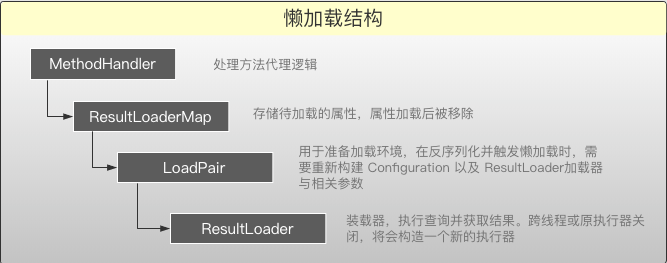
代理之后Bean会包含一个MethodHandler,内部在包含一个Map用于存放待执行懒加载,执行前懒加载前会移除。LoadPair用于针对反序列化的Bean准备执行环境。ResultLoader用于执行加载操作,执行前如果原执行器关闭会创建一个新的。
特定属性如果加载失败,不会在进行二次加载。
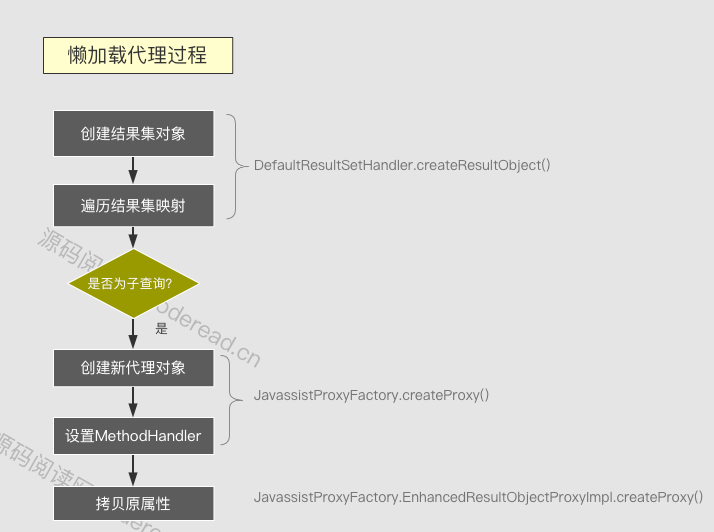
Bean代理过程
代理过程发生在结果集解析 交创建对象之后(DefaultResultSetHandler.createResultObject),如果对应的属性设置了懒加载,则会通过ProxyFactory 创建代理对象,该对象继承自原对象,然后将对象的值全部拷贝到代理对像。并设置相应MethodHandler(原对象直接抛弃)
联合查询&嵌套映射
映射说明
映射是指返回的ResultSet列与Java Bean 属性之间的对应关系。通过ResultMapping进行映射描述,在用ResultMap封装成一个整体。映射分为简单映射与复合嵌套映射。
简单映射:即返回的结果集列与对象属性是1对1的关系,这种情况下ResultHandler 会依次遍历结果集中的行,并给每一行创建一个对象,然后在遍历结果集列填充至对象的映射属性。
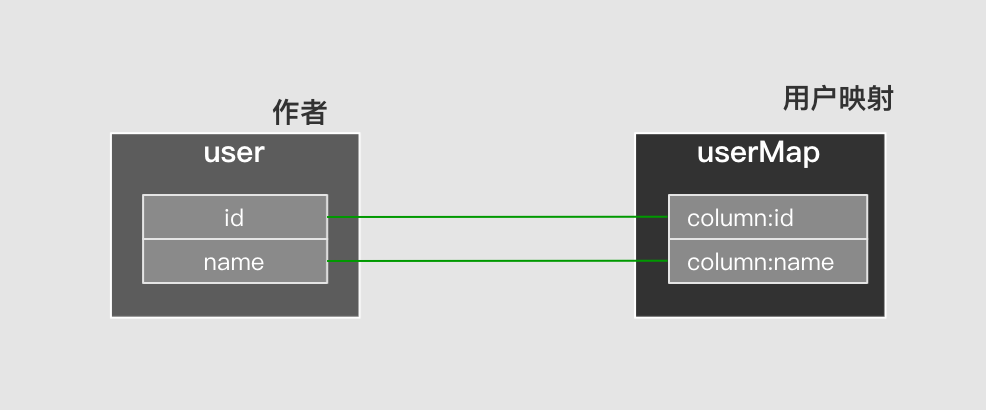
嵌套映射:但很多时候对象结构, 是树级程现的。即对象中包含对象。与之对应映射也是这种嵌套结构。
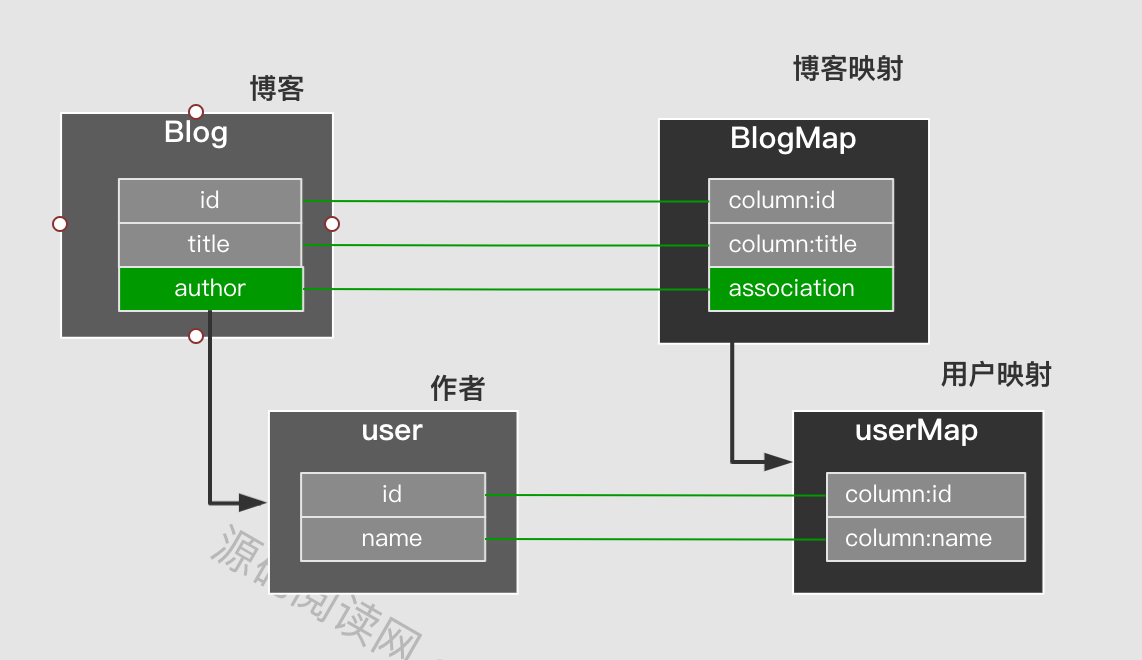
在配置方式上可以直接配置子映射,也以引入外部映射和自动映射。共有两类嵌套结构分别是一对多 与多对多 。

关于映射的使用方式,官网有非常详细的文档。这里就不在赘述。接下来分析一下,嵌套映射结果集填充过程。
联合查询
有了映射之后如何获取结果?普通的单表查询是无法获取复合映射所需结果,这就必须用到联合查询。然后在将联合查询返回的数据列,拆分给不同的对象属性。1对1与1对多拆分和创建的方式是一样的。
1对1查询映射
select a.id,
a.title,
b.id as user_id,
b.name as user_name
from blog a
left join users b on a.author_id=b.id
where a.id = 1;
通过上述语句联合查询语句,可以得出下表中结果。结果中前两字段对应Blog,后两个字段对应User。然后在将User作为author属性填充至Blog对象。


上述两个例子中,每一行都会产生两个对象,一个Blog父对象,一个User子对象。
1对多查询
sql语句
select a.id,a.title, c.id as comment_id, c.body as comment_bodyfrom blog a left join comment c on a.id=c.blog_idwhere a.id = 1;
上述语句可得出三条结果,前两个字段对应Blog,后两个字段对应Comment(评论)。与1对1不同的是,三行指向的是同一Blog。因为它ID都是一样的。


上述结果中,相同的三行Blog将会创建一个Blog,同时分别创建三个不同的Comment组成一个集合,并填充至comments对象。
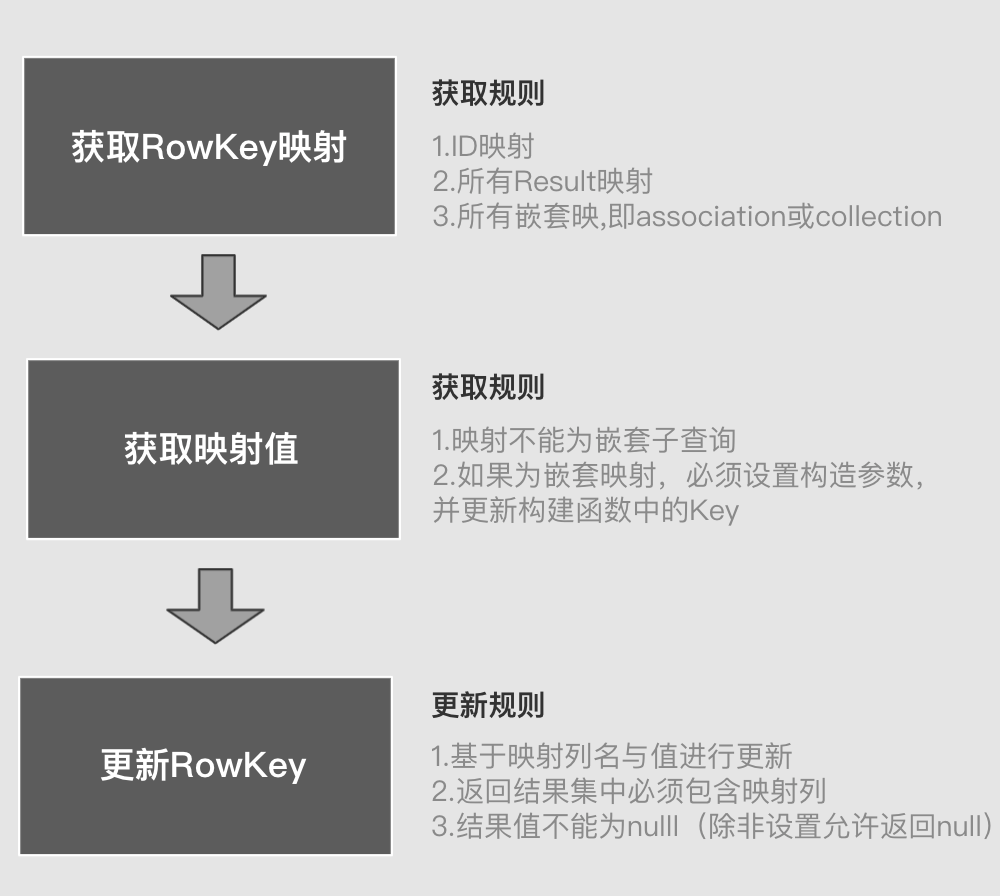
RowKey创建机制
在1对多的查询过程中,是基于RowKey来断定两行数据是否相同的 。RowKey一般基于。但有时并不会指定 这时将会采用其它映射字段创建RowKey具体规则如下:
结果集解析流程
*TODO:待补充源码地图*
这里直接采用1对多的情况进行解析,因为1对1就是1对多的简化版。查询的结果如下表:

其整个解析流程如下图:
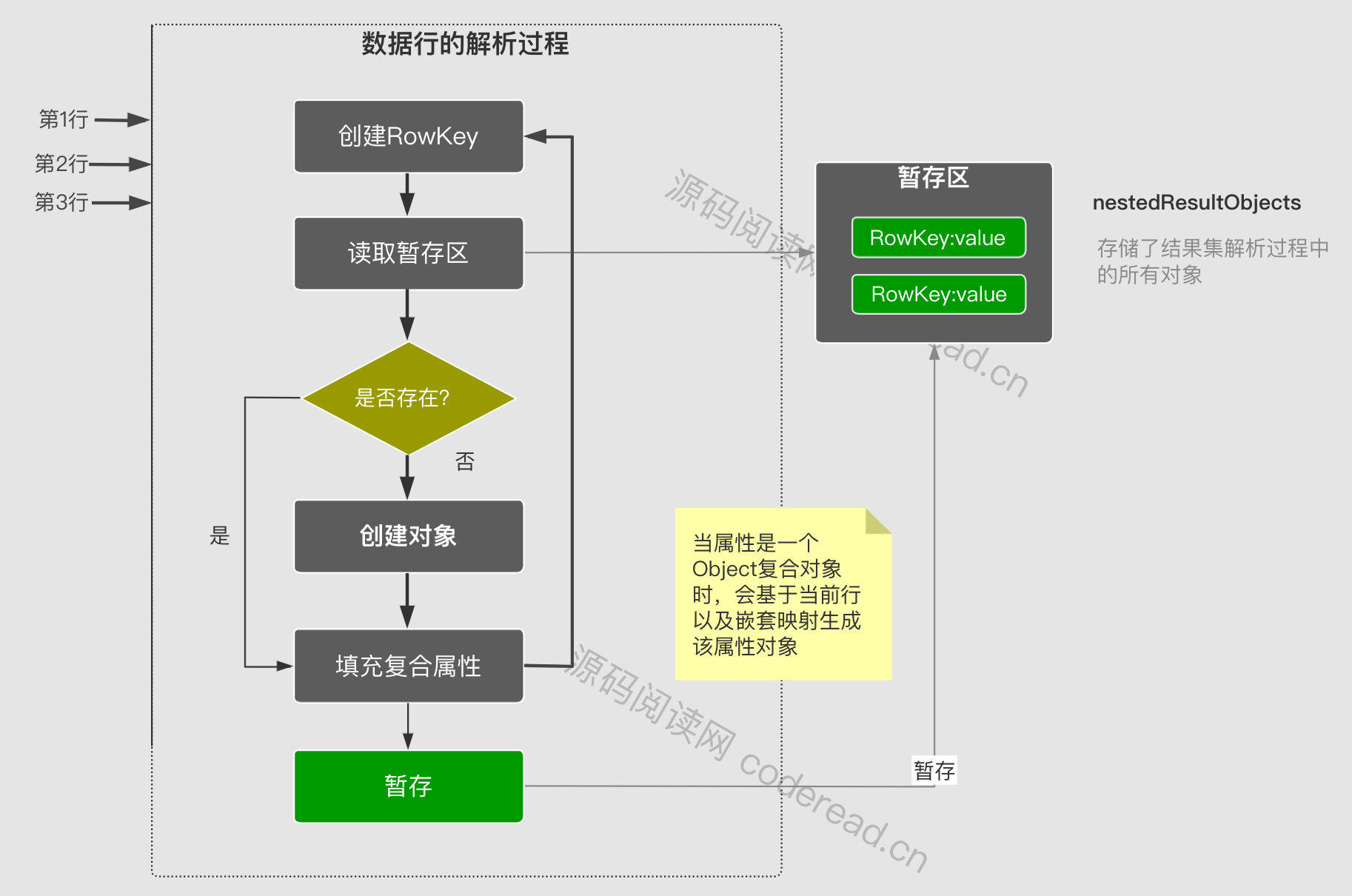
流程说明:
所有映射流程的解析都是在DefaultResultSetHandler当中完成。主要方法如下:
handleRowValuesForNestedResultMap()
嵌套结果集解析入口,在这里会遍历结果集中所有行。并为每一行创建一个RowKey对象。然后调用getRowValue()获取解析结果对象。最后保存至ResultHandler中。
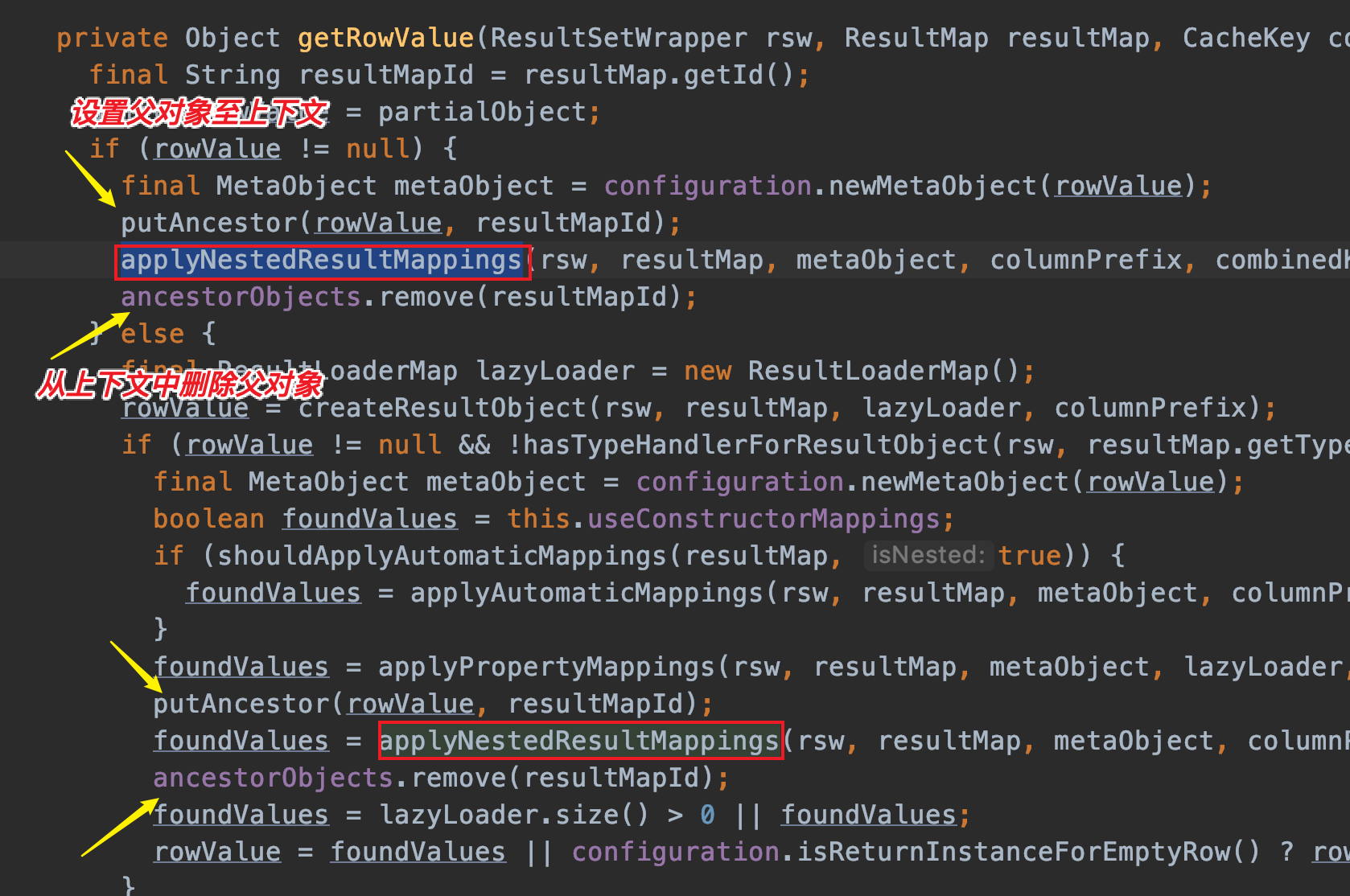
注:调用getRowValue前会基于RowKey获取已解析的对象,然后作为partialObject参数发给getRowValue
getRowValue()
该方法最终会基于当前行生成一个解析好对象。具体职责包括,1.创建对象、2.填充普通属性和3.填充嵌套属性。在解析嵌套属性时会以递归的方式在调用getRowValue获取子对象。最后一步4.基于RowKey 暂存当前解析对象。
如果partialObject参数不为空 只会执行 第3步。因为1、2已经执行过了。
applyNestedResultMappings()
解析并填充嵌套结果集映射,遍历所有嵌套映射,然后获取其嵌套ResultMap。接着创建RowKey 去获取暂存区的值。然后调用getRowValue 获取属性对象。最后填充至父对象。
如果通过RowKey能获取到属性对象,它还是会去调用getRowsValue,因为有可能属下还存在未解析的属性。
循环引用
两个对象之间互相引用即循环引用,如下图就是一个例子:
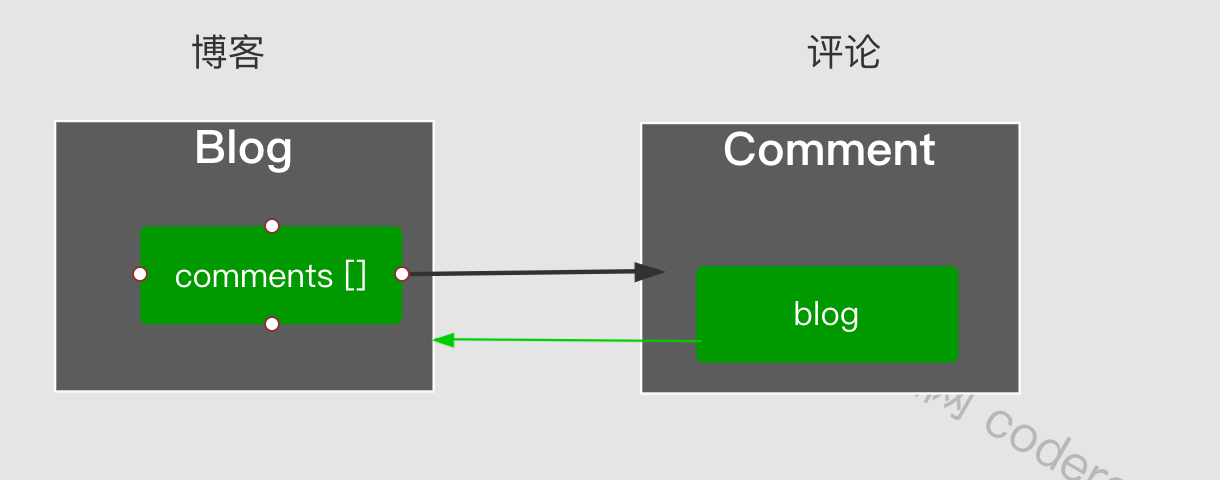
对应ResultMap如下:
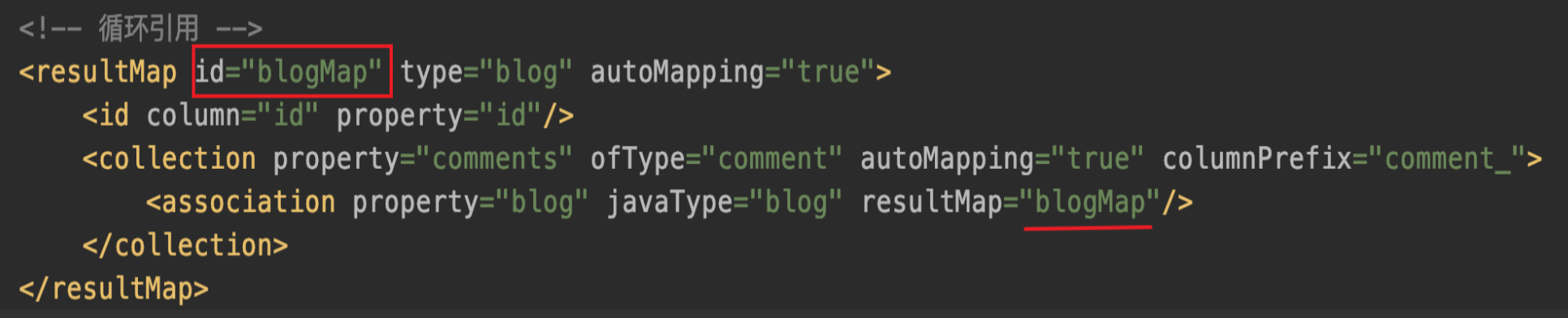
这种情况会导致解析死循环吗?答案是不会。DefaultResultSetHandler 在解析复合映射之前都会在上下文中填充当前解析对象(使用resultMapId做为Key)。如果子属性又映射引用了父映射ID,就可以直接获取不需要在去解析父对象。具体流程如下:
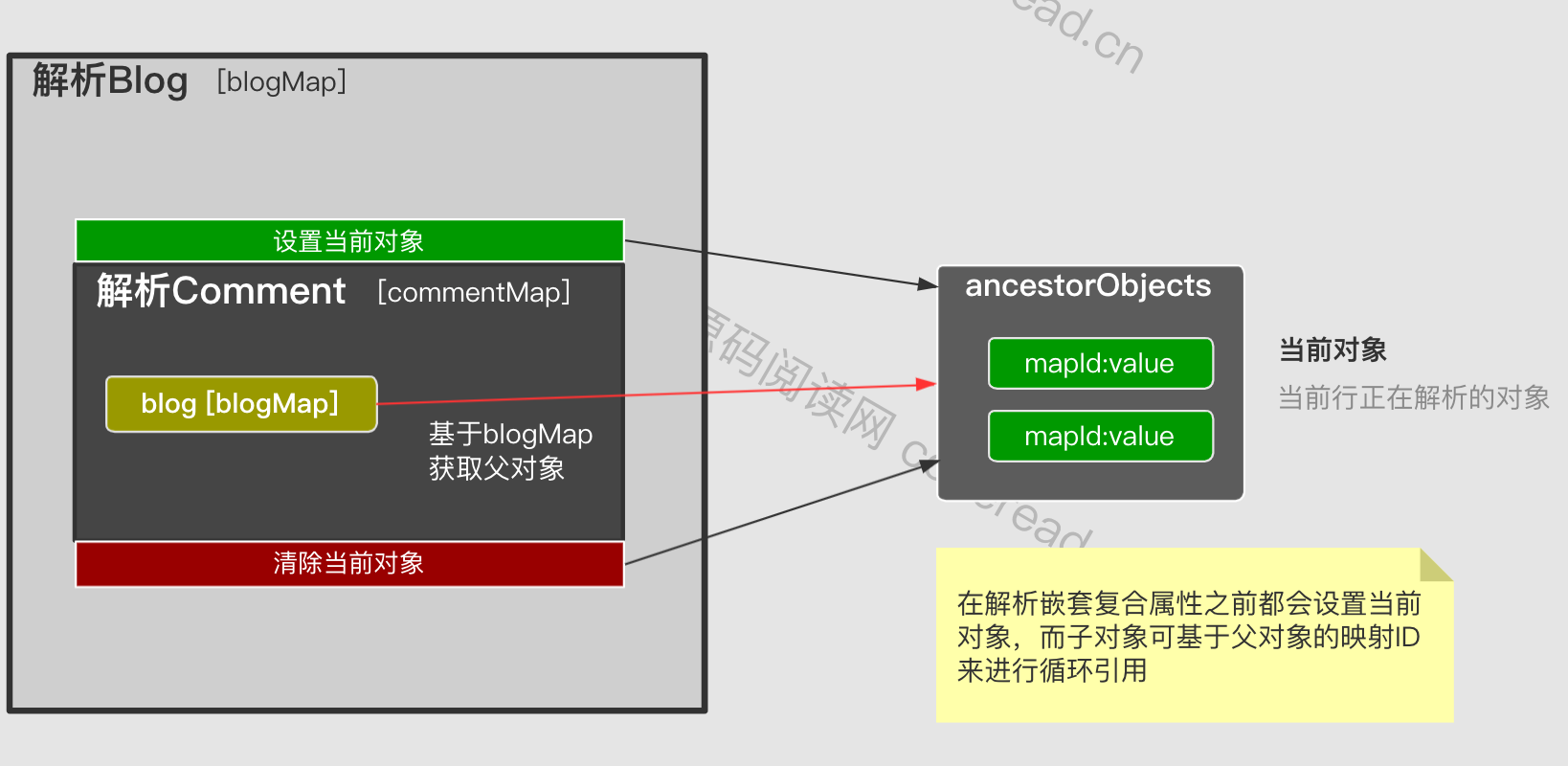
具体代码: