Linux文件系统 inode block superblock
简述 linux文件系统 -->inode/block/superblock/dentry
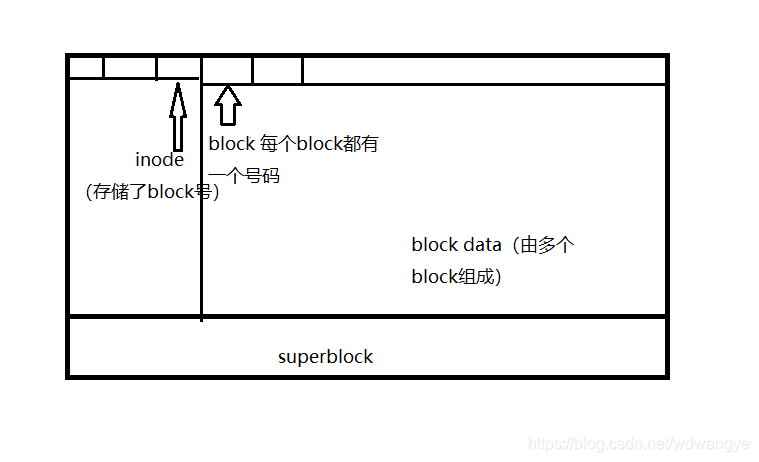
操作系统的文件数据除了文件实际内容外,还有非常多的属性,如文件权限(rwx)与文件属性(所有者、群组、时间参数等)。
文件系统通常将这两部分数据存放在不同的块。权限属性放到 inode 中,实际数据放到 data block 中。
inode
- 索引节点 。
- 记录文件的属性,和此文件的数据所在的block 号码。
- 一个文件占用一个inode。
- inode相同的文件,互为硬链接文件(文件又另一个入口)。
- 每个inode大小均固定为 128bytes。
block
- 实际记录文件的内容。
- 若文件太大时,会占用多个block ,若文件太小时,一个block剩余空间会被浪费。
- 每个block一般大小1k,2k,4k,引导分区boot是1k其他都是4k。
- 磁盘读取数据是按block为单位读取的。
.superblock:(超级块)
- 记录此filesystem 的整体信息,包括inode和block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等。
- 文件系统的挂载时间、最近一次写入数据的时间、最近一次检验磁盘(fsck)的时间等。
- 还有一个validbit数值,若此文件系统已经被挂载,validbit的值为 0 ,若未被挂载,则validbit值为 1 。
四大对象的关系:
在super_block、inode、dentry和file对象中,都有对应的super_operations、inode_operations、dentry_operations和file_operations结构体,这些struct中定义了函数指针来对对象进行操作。如file_operations中定义了read、write、open、flush等函数指针,对该file对象进行读、写、打开和写回的操作。
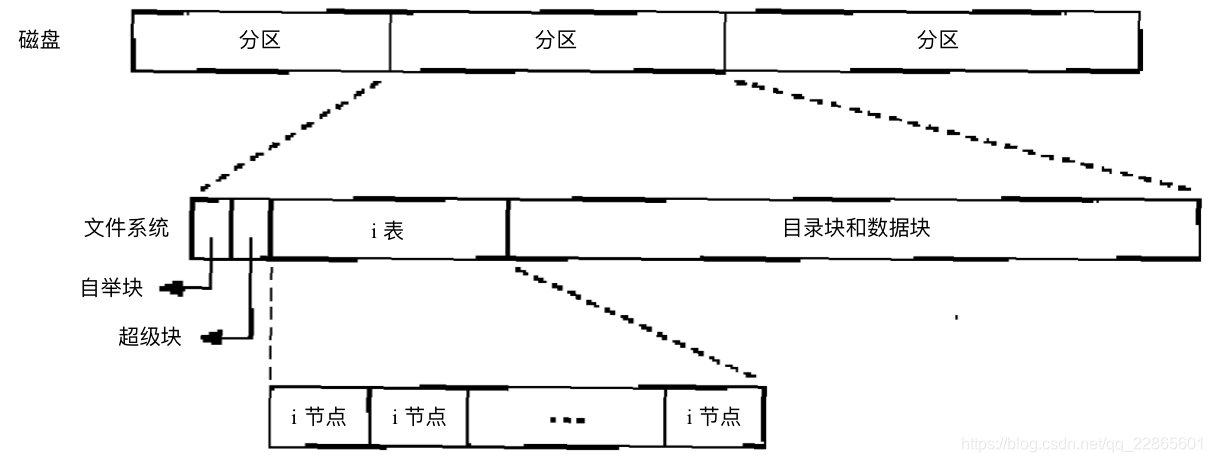
如果将磁盘分为多个分区,每个分区代表一个文件系统,则在文件系统在磁盘中的表示可以分为:自举块、超级块、inode表和数据块(包括目录和数据)。每个文件对应一个inode结构,有唯一的inode编号,并且unix将目录看作是一种特殊的文件,也用一个inode结构表示,可以嵌套包含普通文件和子目录。超级块用于储存特定文件系统的信息,对于非基于磁盘的文件系统,如sysfs,则在内存中现场创建此结构。
忽略超级块和自举块,文件系统的结构就是下图的样子。inode表中可以指向文件的数据块,可以指向目录块。而目录如前所述,是一种特殊的文件,里面包含一个及多个目录项,用inode号和文件名来表示。所以unix文件系统不是按照文件名存取文件的,而是借由inode来完成,它在当前文件系统的唯一表示一个文件的。一个大文件可能包括多个数据块,目录块也包含多个目录项。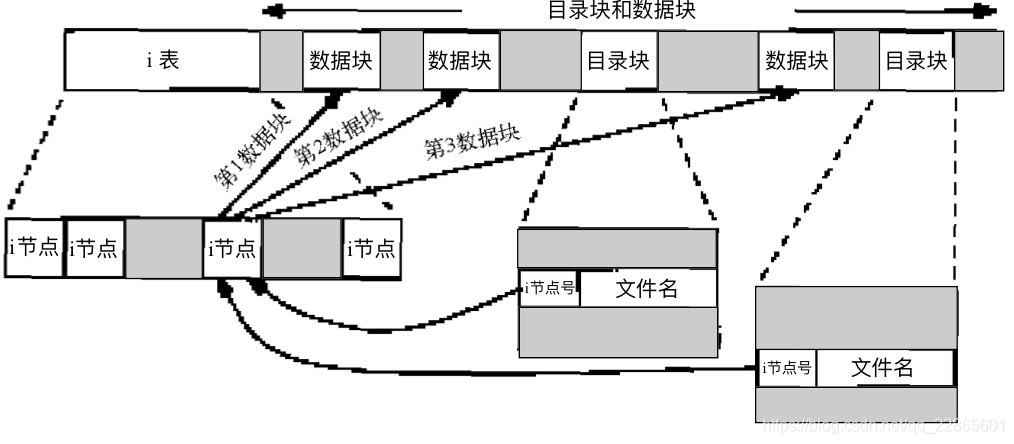
DENTRY与INODE有什么联系和区别
dentry和inode共同来定位文件系统中的一个文件,detry存在文件名,inode的索引号,以及父目录,子目录等信息,在遍历过程中,可以通过遍历dentry目录同时判断文件名信息来寻找菌体的文件。
我们在进程中要怎样去描述一个文件呢?我们用目录项(dentry)和索引节点(inode)。它们的定义如下:
struct dentry {
struct inode *d_inode; /* Where the name belongs to - NULL is
struct dentry *d_parent; /* parent directory */
struct list_head d_child; /* child of parent list */
struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
......
};
struct inode {
unsigned long i_ino;
atomic_t i_count;
umode_t i_mode;
unsigned int i_nlink;
uid_t i_uid;
gid_t i_gid;
dev_t i_rdev;
loff_t i_size;
struct timespec i_atime;
unsigned long i_blocks;
unsigned short i_bytes;
unsigned char _sock;
12
struct inode_operations *i_op;
struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct super_block *i_sb;
......
};
所谓"文件", 就是按一定的形式存储在介质上的信息,所以一个文件其实包含了两方面的信息,一是存储的数据本身,二是有关该文件的组织和管理的信息。在内存中, 每个文件都有一个dentry(目录项)和inode(索引节点)结构,dentry记录着文件名,上级目录等信息,正是它形成了我们所看到的树状结构;而有关该文件的组织和管理的信息主要存放inode里面,它记录着文件在存储介质上的位置与分布。同时dentry->d_inode指向相应的inode结构。dentry与inode是多对一的关系,因为有可能一个文件有好几个文件名(硬链接, hard link, 可以参考这个网页http://www.ugrad.cs.ubc.ca/~cs219/CourseNotes/Unix/commands-links.html)。
所有的dentry用d_parent和d_child连接起来,就形成了我们熟悉的树状结构。
inode代表的是物理意义上的文件,通过inode可以得到一个数组,这个数组记录了文件内容的位置,如该文件位于硬盘的第3,8,10块,那么这个数组的内容就是3,8,10。其索引节点号inode->i_ino,在同一个文件系统中是唯一的,内核只要根据i_ino,就可以计算出它对应的inode在介质上的位置。就硬盘来说,根据i_ino就可以计算出它对应的inode属于哪个块(block),从而找到相应的inode结构。但仅仅用inode还是无法描述出所有的文件系统,对于某一种特定的文件系统而言,比如ext3,在内存中用ext3_inode_info描述。他是一个包含inode的"容器"。
struct ext3_inode_info {
__le32 i_data[15];
......
struct inode vfs_inode;
};
le32 i data[15]这个数组就是上一段中所提到的那个数组。
注意,在遥远的2.4的古代,不同文件系统索引节点的内存映像(ext3_inode_info,reiserfs_inode_info,msdos_inode_info ...)都是用一个union内嵌在inode数据结构中的. 但inode作为一种非常基本的数据结构而言,这样搞太大了,不利于快速的分配和回收。但是后来发明了container_of(...)这种方法后,就把union移到了外部,我们可以用类似container of(inode, struct ext3_inode_info, vfs_inode),从inode出发,得到其的"容器"。
dentry和inode终究都是在内存中的,它们的原始信息必须要有一个载体。否则断电之后岂不是玩完了?且听我慢慢道来。
文件可以分为磁盘文件,设备文件,和特殊文件三种。设备文件暂且不表。
磁盘文件
就磁盘文件而言,dentry和inode的载体在存储介质(磁盘)上。对于像ext3这样的磁盘文件来说,存储介质中的目录项和索引节点载体如下,
struct ext3_inode {
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Creation time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
......
__le32 i_block[EXT2_N_BLOCKS];/* Pointers to blocks */
......
}
struct ext3_dir_entry_2 {
__u32 inode; /* Inode number */
__u16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[EXT3_NAME_LEN]; /* File name */
};
le32 i block[EXT2 N BLOCKS];/* Pointers to blocks */
i_block数组指示了文件的内容所存放的地点(在硬盘上的位置)。
ext3_inode是放在索引节点区,而ext3_dir_entry_2是以文件内容的形式存放在数据区。我们只要知道了ino,由于ext3_inode大小已知,我们就可以计算出ext3_inode在索引节点区的位置( ino * sizeof(ext3_inode) ),而得到了ext3_inode,我们根据i_block就可以知道这个文件的数据存放的地点。将磁盘上ext3_inode的内容读入到ext3_inode_info中的函数是ext3_read_inode()。以一个有100 block的硬盘为例,一个文件系统的组织布局大致如下图。位图区中的每一位表示每一个相应的对象有没有被使用。

特殊文件
特殊文件在内存中有inode和dentry数据结构,但是不一定在存储介质上有"索引节点",它断电之后的确就玩完了,所以不需要什么载体。当从一个特殊文件读时,所读出的数据是由系统内部按一定的规则临时生成的,或从内存中收集,加工出来的。sysfs里面就是典型的特殊文件。它存储的信息都是由系统动态的生成的,它动态的包含了整个机器的硬件资源情况。从sysfs读写就相当于向kobject层次结构提取数据。
还请注意, 我们谈到目录项和索引节点时,有两种含义。一种是在存储介质(硬盘)中的(如ext3_inode),一种是在内存中的,后者是根据在前者生成的。内存中的表示就是dentry和inode,它是VFS中的一层,不管什么样的文件系统,最后在内存中描述它的都是dentry和inode结构。我们使用不同的文件系统,就是将它们各自的文件信息都抽象到dentry和inode中去。这样对于高层来说,我们就可以不关心底层的实现,我们使用的都是一系列标准的函数调用。这就是VFS的精髓,实际上就是面向对象。
我们在进程中打开一个文件F,实际上就是要在内存中建立F的dentry,和inode结构,并让它们与进程结构联系来,把VFS中定义的接口给接起来。我们来看一看这个经典的图。这张图之于文件系统,就像每天爱你多一些之于张学友,番茄炒蛋之于复旦南区食堂,刻骨铭心。

硬链接文件删除 : 另一个文件目录detry指向了inode节点,硬连接的inode以及数据块和原文件相同。 由于是指向原有inode,所以不能跨文件系统。由于inode节点号相同,必须将链接文件和原文件同时删除。
软链接文件删除 :另外新建了一个inode和数据块,其中数据块中的记录是原文件的路径。当原文件路径发生变化时,该软连接就失效了。因为是新建inode,可以跨文件系统。inode号不同,链接文件只是原文件的一个快捷方式,删除软链接文件不影响原文件的数据。
https://blog.csdn.net/lickylin/article/details/100178824?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160293769519724838501760%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=160293769519724838501760&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-1-100178824.pc_v1_rank_blog_v1&utm_term=vfs&spm=1018.2118.3001.4187