两种方式,分别查询数据有多少行:
hive (gmall)> select * from ods_log;
Time taken: 0.706 seconds, Fetched: 2955 row(s)
hive (gmall)> select count(*) from ods_log;
2959
两次查询结果不一致的原因分析
hive (gmall)>
drop table if exists ods_log;
CREATE EXTERNAL TABLE ods_log (`line` string)
PARTITIONED BY (`dt` string) -- 按照时间创建分区
STORED AS -- 指定存储方式,读数据采用LzoTextInputFormat;
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_log' -- 指定数据在hdfs上的存储位置
;
这是当时创建表时的语句,指定了存储格式为lzo,然后执行了为lzo文件创建索引的命令
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer -Dmapreduce.job.queuename=hive /warehouse/gmall/ods/ods_log/dt=2020-06-14
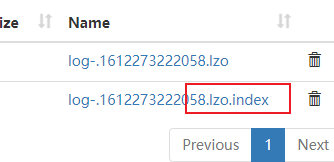
所以在HDFS上的hive里存着lzo格式数据和lzo.index索引文件,这便于对文件进行切片。
- 但是
select * from ods_log不执行MR操作,默认采用的是ods_log建表语句中指定的DeprecatedLzoTextInputFormat,能够识别lzo.index为索引文件。 select count(*) from ods_log执行MR操作,默认采用的是CombineHiveInputFormat,不能识别lzo.index为索引文件,将索引文件当做普通文件处理。更严重的是,这会导致LZO文件无法切片。