SQL Server 针对用户提交的DML语句,通过一系列的优化后,产生出一个能被SQL Server识别并高效“响应”的方案,用Ctrl+M(实际执行计划)在用Ctrl+L(预估执行计划)
提交一个DML语句(CRUD)会引起一系列的活动。
1.发生在关系引擎中的活动
2.发生在存储引擎中的活动
在关系引擎中,查询被解析后传给查询优化器;在查询优化器中,查询被分析计算后生成执行计划,然后发给存储引擎,存储引擎按照计划查找或修改数据,之后返回给客户端
需要注意的是优化器产生的预估执行计划,而在存储引擎中产生的才是实际执行计划。这个计划可能与预估执行计划有出入,一下原因会导致二者有出入。
1.由于超过了并行执行的阈值,导致原有计划更改,使用了并行执行,
2.统计信息变更、过时、这时候也会更改预估执行计划
3.由于某些情况产生了重编译
二:预估与实际执行计划
1.执行计划有两类:一类是预估执行计划,由优化器产生,标识执行的逻辑步骤;另一类是实际执行计划,在实际执行计划中产生,标识实际执行的情况。
大部分情况下实际执行计划和预估执行计划是相同的,预估执行计划是存放在计划缓存中的,可以通过访问这些缓存中的计划得出统计数据。特别是对于一些大查询来说,获取实际执行计划往往不现实。实际执行计划可用于获取实际行数、实际统计信息。
2.执行计划重用
通过重用已经存在的计划缓存中的执行计划。可以大大降低服务器的开销。
在提交查询后,在Algebrizer阶段会创建一个hash数据用于唯一标识这个查询,并且会标识查询的语句,优化器会对比这个hash和缓存中hash,如果查询已经存在,它就会跳过优化并重用缓存中的执行计划。
为了重用执行计划,在编码时,尽可能编写一些SQL Server 重用的代码,参数化查询就是其中的一种,存储过程也是一个不错的选择,如果用硬编码的方式编写语句,即使少量的修改都会引起缓存丢失,因为脚本已经不同,SQL Server 无法找到缓存的hash值,会引起不必要的优化开销。
SQLServer 不会永久保存计划的缓存,并且存在缓存中的计划也不会永久不变,每个计划都会有一个age值,当Algebrizer触发时,会扫描这个age值,并且每次降低这个值。
在满足下面全部的条件时,预估执行计划会被移除出内存。
1.操作系统需要更多的内存
2.Age值已经降低到0
3.执行计划没有被当前的连接使用
导致执行计划重新编译,得避免下面的情景。
1.查询所引用的表结构或者架构更改
2.查询所用的索引更改
3.查询用到的索引被删除
4.显示调用sp_recompile
5.查询引用的表上,由于在键值上有大量的Insert/Delete操作,引起了统计信息的更改
6.单一查询中混合了DDL和DML操作,称为延迟编译
7.在查询中修改了SET选项
8.查询所用到的临时表的架构、结构修改
9.查询过程中游标选项更改
三:清除缓存中的执行计划
DBCC FREEPROCCACHE
四:执行计划格式
SQL Server目前支持3种格式:图形化、文本化、XML格式
1.图形化执行计划
图形化格式分为预估执行计划和实际执行计划两种
2.文本化执行计划
有3种细分格式
(1.SHOWPLAN_ALL:显示完整的预估执行计划信息
(2.SHOWPLAN_TEXT:显示预估执行计划的有限信息,可以用osql.exe等工具分析
(3.STATISTICS PROFILE: 显示完整的实际执行计划信息
3.XML执行计划
SHOWPLAN_XML:优化器在执行之前产生出的执行计划
STATISTICS_XML:实际执行计划的XML格式数据
五:使用SQL Trace自动获取执行计划
在使用SQL Trace时,可以选择下面的事件。
1.SHOWPLAN TEXT:在查询每次执行时触发,和单独使用SHOWPLAN_TEXT选项的结果是一样的
2.SHOWPLAN TEXT(unencoded): 和上面的事件是一样的,但是以二进制数据显示
3.SHOWPLAN ALL:在每次执行时都触发,和SHOWPLAN_ALL选项一样
4.SHOWPLAN ALL FOR QUERY COMPILE:当查询发生编译时触发
5.SHOWPLAN STAISTICS PROFILE:和STATISTICS PROFILE一样
6.SHOWPLAN XML:在每次执行查询并生成预估执行计划时触发
主要介绍图形化执行计划的基础知识、单表查询、表关联、筛选数据、增删改查操作的执行计划
一:基础知识
执行计划包含78种可用的操作符,执行计划分为以下4类:
1.逻辑和物理操作符:也叫跌代器,在执行计划中,以蓝色图标显示,用于标识查询执行计划或者DML操作
2.并行物理操作符:也是蓝色图标,表示并行操作。某种意义上,它们也是逻辑和物理操作符的子集,但是分析的层面及逻辑和物理操作符不同
3.游标操作符:黄色图标,表示T-SQL中的游标操作
4.语言操作符:绿色图标,标识T-SQL语言的元素,如DECLARE、IF、SELECT、WHILE等
二:单表查询
SQL Server对数据表的访问主要有扫描和查找两类操作
1.扫描
包含聚集索引扫描、索引扫描和表扫描
(1).聚集索引扫描
一个查询慢,通产是因为存在非必须的扫描操作,而这其中最常见的就是聚集索引扫描
聚集索引实际上就是表本身,也就是说表有多少列、多少行聚集索引就有多少列、多少行
聚集索引扫描的执行计划代码:
select * from person.ContactType
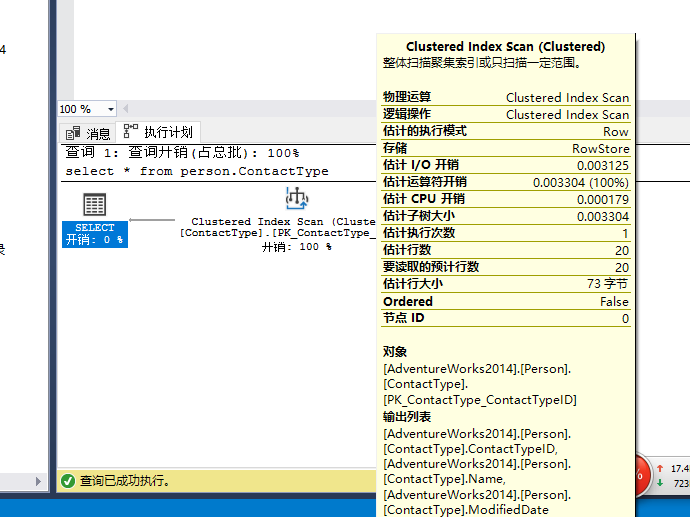
使用了聚集索引扫描操作符来查找所需的数据,在图像化执行计划中Tooltips和图标的属性是用来获取详细信息的手段。
Clustered Index Scan:直接的说明了这个操作符的名字
物理运算符和逻辑运算符:某些操作符是一模一样的,比如此实例中的这个
实际执行模式、估计的执行模式:这两个执行模式是咋SQL Server2012中才出现
实际行数:20,也就是操作符实际查询返回的行数
预估I/O 开销,预估CPU开销:指的是优化预估这个操作所需要的开销
执行次数:这个操作实际被执行了多少次
预估执行次数:优化器预估的操作符被执行的次数
预估操作符开销:指的是操作符开销占执行总过程的比例,由于本例中只有一个操作符,所以这个操作符占本执行计划的全部比例
预估子数开销:该操作符的子数(子操作)开销
预估行数:优化器预估的返回结果集
预估执行大小:预估的结果集大小
Ordered:在这个操作符中是否排序
NodeID:执行计划的步骤序列
对象:操作符发生在表的什么对象上,ContactType表的PK_ContactType_ContactTypeID这个聚集索引
输出列表:SELECT语句中返回的列
聚集索引实际上包含了整个表的数据,并且是以B-Tree格式存储的,所以聚集索引扫描和表扫描无异,虽然是扫描,但并不是总是全表扫描,有时候会存在范围扫描,另外当表上存在聚集索引时,相关的扫描操作只能是聚集索引扫描或者索引扫描(实际上是非聚集索引扫描)而不会出现表扫描
(2)索引扫描
索引扫描实际上就是非聚集索引扫描
select ct.ContactTypeID from Person.ContactType as ct
实际执行计划:

这个操作符证明了优化器使用了ContactType表上的AK_ContactType_Name这个非聚集索引实现查询,因为SELECT子句中ContactTypeID存在于AK_ContactType_Name这个索引上,所以只需要访问这个索引即可
(3)表扫描
如果出现表扫描,证明这个表上没有聚集索引,由于表dbo.DatabaseLog上没有聚集索引,只有一个非聚集索引,同时查询需要返回所有的列,而上面的非聚集索引只包含DatabaseLogID列,所以优化器选择表扫描操作来查询所有数据
select * from dbo.DatabaseLog
表扫描使用情况:意味着没有合适的索引,导致优化器必须遍历全表来找到所需的数据。其中一种情况是查询的确需要返回所有的数据,所以通过扫描来获取是合理的,如果需要返回全部或者绝大部分数据,不管是否存在索引,优化器都会觉得直接扫描所有的数据比从索引中查找更高效。
2.查找
查找分为聚集索引查找、索引查找、书签查找
(1).聚集索引查找
当表上存在聚集索引,且查询的数据只占表的一小部分,优化器会选择从聚集索引上找到合适的数据。由于聚集索引实际包含了整个表的数据,当查询只需要返回聚集索引上已经包含的数据时,直接查找索引比扫描更有效。
聚集索引查找操作:
select ct.ContactTypeID from Person.ContactType as ct where ct.ContactTypeID=7
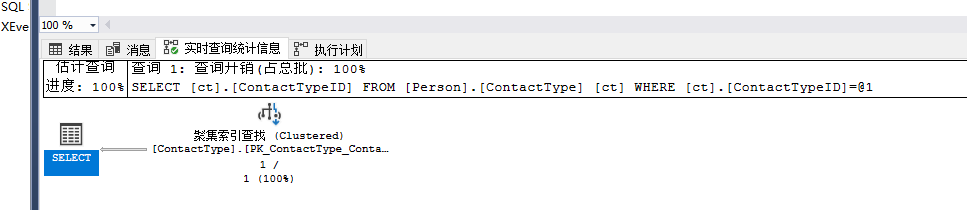
查找和扫描完全不同,扫描是要遍历整个B-Tree机构,而查找可以通过B-tree的键值查找,直接提取数据,并返回结果。当使用查找操作符时,通过键值可以快速、直接定位 数据页,就像你可以通过书的目录定位到所需的章节一样,这里的Tooltips中的Ordered为True,证明优化器在插叙中经过了排序,如果下一个操作符需要对数据进行排序,这个操作是非常有效的,可以减少一次排序操作。
(2)索引查找
应该是非聚集索引查找,在很多情况下,非聚集索引比聚集索引查找更高效。通常来说非聚集索引的列比聚集索引要少,所以非聚集索引的体积更小。查询的速度很大程度上与受访问的数据页有关,如果索引的体积很大,即包含的页数很多,那么势必影响查询性能。
select ct.ContactTypeID from Person.ContactType as ct where Name like 'Own%'
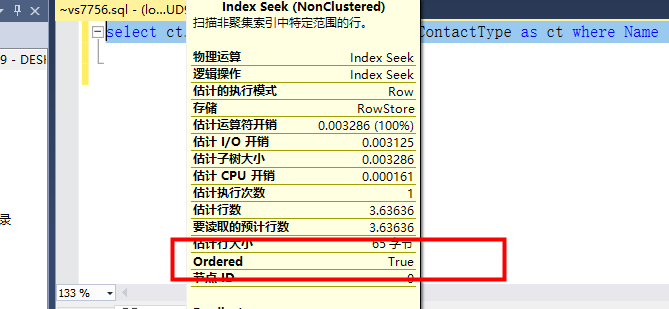

和聚集索引查找类型一样,索引查找也是使用非聚集索引来查找所需的行,优化器会根据查询检查是否有非聚集索引可用,如果同时还存在聚集索引,则对比两者的开销,选择更低开销的索引来查找。
(3)书签查找
最新说法,键值查找和RID查找,键值查找出现在聚集索引上,RID查找出现在堆表上,当使用一个非聚集索引时,如果这个索引没有覆盖所有的列,优化器会借助聚集索引的键值或者堆表上的RID来获取额外的列。
键值查找示例
select p.BusinessEntityID,p.LastName,p.FirstName from person.Person as p where p.LastName like 'Jaf%'
这个执行计划返回多个操作符,图形化执行计划的阅读方式是从右到左,从上到下,这个索引包含了3列,但是查询还多了一列NameStyle,也就是这一列没有被覆盖,这就要借用聚集索引来获取。此时,会引入KEY查找,这就意味着优化器不能从单一操作中获取数据,而需要从聚集索引或者堆表上查找。
从Key Lookup操作符上可以看到,这一列是为了返回NameStyle列。
这种额外的操作符会导致额外的I/O开销,可以借助覆盖索引或者包含索引来把列包含在非聚集索引中,Key Lookup操作符通常会伴随着Nested Loops Join操作符,这种操作符并不意味着有性能问题,只是把索引查找和键值查找的数据合并在一起。
键值查找的出现,暗示着你需要检查查询是佛合理,是否有合适的索引。
对RID Lookup,其原理和键值查找基本上是一样的,不同的地方是RID查找意味着表上没有聚集索引,也就是堆表,在查询中如果为堆表,非聚集索引不能覆盖查询所有的列,这时候优化器就需要到堆表上找数据。由于堆表没有什么组织可言,所以需要根据具体数据的行标识符,也就是所谓的RID或者ROWID来在堆中定位数据.
select * from dbo.DatabaseLog where DatabaseLogID=1
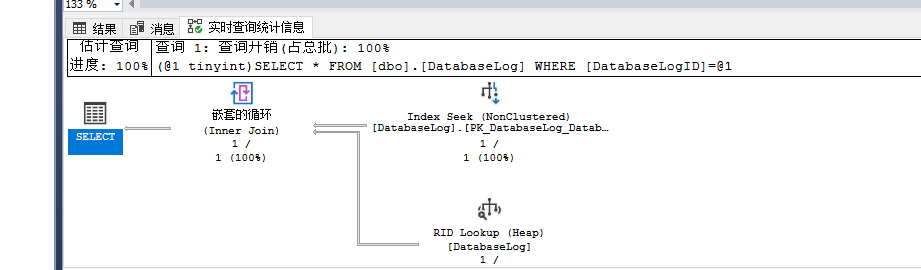
从执行计划来说,针对这个查询,优化器会先借用表上的主键来完成where条件的查询,因为DatabaseLogID在PK_DatabaseLog_DatabaseLogID这个非聚集索引上。
除了这列,SELECT子句中的其他列并不在这个索引上,且没有其他索引可用,所以只能通过堆表上的RID来查找其他列的数据,和键值查找几乎一样,这种操作符也往往伴随着Nested Loops Join一起出现,且RID查找需要额外的I/O开销。
非必要情况下不要用SELECT *,从该查询就可以看出其中的原因。