想象用浏览器打开imooc.com网站,HTTP走过的环节: 1.首先,是对imooc.com域名解析,(根据DNS服务器得到域名的IP地址) (1.1)浏览器搜索浏览器自身的DNS缓存。 (1.2)如果浏览器没有找到自身的DNS缓存或之前的缓存已失效,那么浏览器会搜索操作系统自身的DNS缓存。 (1.3)如果操作系统的DNS缓存也没有找到,那么系统会尝试在本地的HOST文件去找。 (1.4)如果在HOST里依然没有找到,浏览器会发起一个DNS的系统调用,即一般向本地的宽带运营商发起域名解析请求。这后面又可以试情况分很多步骤,第一,宽带运营商服务器会首先查看自身的缓存,看是否有结果,如果没有,那么运营商服务器会发起一个迭代DNS解析请求(根域,顶级域,域名注册商),最终会返回对DNS解析的结果。运营商服务器然后把结果返回给操作系统内核(同时也缓存在自己的缓存区),然后操作系统把结果返回给浏览器。 (1.5)以上的最终结果,是让浏览器拿到imooc.com的IP地址,DNS解析完成。 2.然后,在浏览器获得域名的IP地址后,发起“三次握手”,建立TCP/IP连接。 3.在TCP/IP连接建立起来后,浏览器就可以向服务器发送HTTP请求了。比如,用HTTP的GET方法请求一个根域里的某个域名,协议可以采用HTTP 1.0 。
(向IP地址发起(http/https)请求)
4.服务器端接受这个请求,根据路径参数,经过后端的一些处理之后,把处理后的一个结果以数据的形式返回给浏览器,如果是imooc.com网站的页面,服务器就会把完整的HTML页面代码返回给浏览器。
(服务器收到、处理并返回http请求)
5.浏览器拿到了imooc.com这个网站的完整HTML页面代码,在解析和渲染这个页面的时候,里面的Javascript、CSS、图片等静态资源,它们同样也是一个个HTTP请求,都需要经过上面的步骤来获取。
(浏览器拿到返回的内容)
6.浏览器根据拿到的资源对页面进行渲染,最终把一个完整的页面呈现出来。
浏览器渲染页面过程:
根据HTML结构生成DOM Tree
根据css 生成CSSOM(样式)
将DOM Tree和CSSOM整合成 RenderTree(渲染树)
根据RenderTree开始渲染和展示
遇到<script>时,会执行并阻塞渲染
浏览器解析CSS:
按照从右往左的顺序
#molly div.haha span{color:#f00}
浏览器会按照从右向左的顺序去读取选择器。先找到span然后顺着往上找到class为“haha”的div再找到id为“molly”的元素。成功匹配到则加入结果集,如果直到根元素html都没有匹配,则不再遍历这条路径,从下一个span开始重复这个过程。
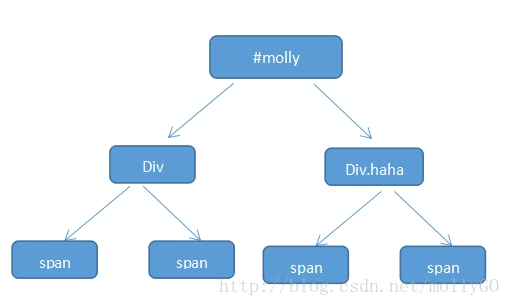
如果从左向右的顺序读取,在执行到左边的分支后发现没有相对应标签匹配,则会回溯到上一个节点再继续遍历,直到找到或者没有相匹配的标签才结束。如果有100个甚至1000个分支的时候会消耗很多性能。反之从右向左查找极大的缩小的查找范围从而提高了性能。
css样式权重:
!important 10000
第一等:代表内联样式,如: style=””,权值为1000。
第二等:代表ID选择器,如:#content,权值为100。
第三等:代表类,伪类和属性选择器,如.content,权值为10。
第四等:代表类型选择器和伪元素选择器,如div p,权值为1。