Active Learning主动学习
我们使用一些传统的监督学习方法做分类的时候,往往是训练样本规模越大,分类的效果就越好。但是在现实生活的很多场景中,标记样本的获取是比较困难的,这需要领域内的专家来进行人工标注,所花费的时间成本和经济成本都是很大的。而且,如果训练样本的规模过于庞大,训练的时间花费也会比较多。那么有没有办法,用尽可能少的标注,获取尽可能好的训练结果?主动学习(Active Learning)为我们提供了这种可能。主动学习通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样本训练分类模型来提高模型的精确度。
定义:在某些情况下,没有类标签的数据相当丰富而有类标签的数据相当稀少,并且人工对数据进行标记的成本又相当高昂。在这种情况下,我们可以让学习算法主动地提出要对哪些数据进行标注,之后我们要将这些数据送到专家那里,让他们进行标注,再将这些数据加入到训练样本集中对算法进行训练。这一过程叫做主动学习。
由此我们可以看出,主动学习最主要的就是选择策略。
主动学习的模型如下:
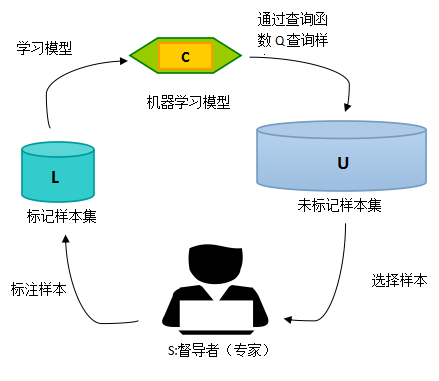
A=(C,Q,S,L,U),其中 C 为一组或者一个分类器,L是用于训练已标注的训练样本。Q 是查询函数,用于从未标注样本池U中查询信息量大的信息,S是督导者,可以为U中样本标注正确的标签.
最开始,先将样本分为少量的已标记样本L,和大量未标记样本U.学习者通过少量初始标记样本L开始学习,通过一定的查询函数Q选择出一个或一批最有用的样本(大多数算法都每次选择一批样本),专家标记,将标记后的样本从U中删除,加入L中,然后利用获得的新知识(所有L)来训练分类器和进行下一轮查询。主动学习是一个循环的过程,直至达到某一停止准则为止。
在各种主动学习方法中,查询函数的设计最常用的策略是:不确定性准则(uncertainty)和差异性准则(diversity)。
不确定性:我们可以借助信息熵的概念来进行理解。我们知道信息熵是衡量信息量的概念,也是衡量不确定性的概念。信息熵越大,就代表不确定性越大,包含的信息量也就越丰富。事实上,有些基于不确定性的主动学习查询函数就是使用了信息熵来设计的,比如熵值装袋查询(Entropy query-by-bagging)。所以,不确定性策略就是要想方设法地找出不确定性高的样本,因为这些样本所包含的丰富信息量,对我们训练模型来说就是有用的。
差异性:怎么来理解呢?之前说到或查询函数每次迭代中查询一个或者一批样本。我们当然希望所查询的样本提供的信息是全面的,各个样本提供的信息不重复不冗余,即样本之间具有一定的差异性。在每轮迭代抽取单个信息量最大的样本加入训练集的情况下,每一轮迭代中模型都被重新训练,以获得的知识去参与对样本不确定性的评估可以有效地避免数据冗余。但是如果每次迭代查询一批样本,那么就应该想办法来保证样本的差异性,避免数据冗余。