结论
先说结论,可以使用group_concat group by的组合实现多行变一行,将一个字段的多个类型串成一个字段
需求:
如题,一个字段如电影类别,一部电影可以是多个类别,如喜剧、动作片等,其形式可以是这样的1::Toy Story (1995)::Animation|Children's|Comedy 字段分别为id,电影名称,电影类别
现有一表cour_info,存储课程与专业的关系,而课程与专业是一对多关系,即一个KCMC可以对应多个major,现在需要将major字段处理为电影类别类似的形式,该如何处理?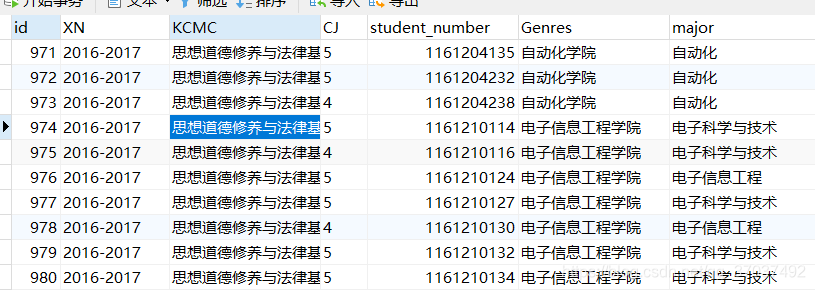
尝试
第一印象想到的是利用update SQL语句进行major字段的字符串拼接的方法,主要使用concat()方法 方法查看
步骤一:对表cour_info进行复制,得下表
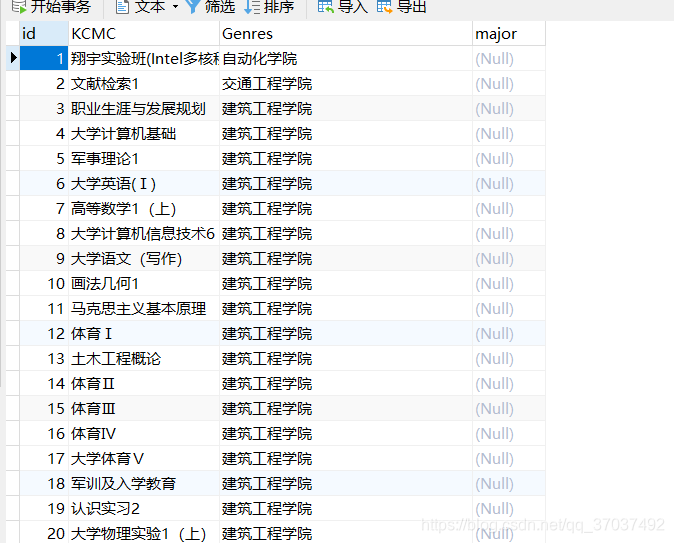
使用语句
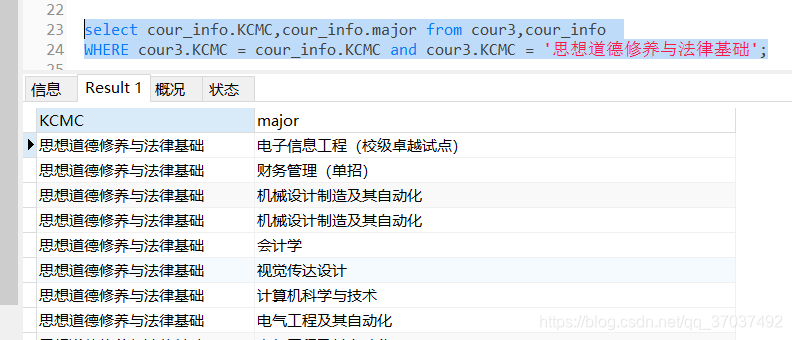
UPDATE cour3,cour_info
set cour3.major= concat_ws('|',ifNULL(cour3.major,''),cour_info.major)
WHERE cour3.KCMC = cour_info.KCMC and cour3.KCMC = '思想道德修养与法律基础';
这里,查询两张表得kcmc为“思想道德修养与法律基础”的相同记录,利用原表major不断对新表major进行字符串拼接,但是并没有像我预想一样,这个语句仅把第一个major拼接了上去,sql功力太浅~~~

原表形如
这种做法失败了,不知道咋回事,有知道的小伙伴可以告诉博主~~
再尝试
这一次使用group_concat group by的组合实现
一开始不知道怎么使用group_concat

发现这样可以使用
SELECT cour_info.KCMC,GROUP_CONCAT(cour_info.major separator'|')
FROM cour_info WHERE cour_info.KCMC = '思想道德修养与法律基础'
结果如下

但是去除where条件后结果出错,只存在第一条记录

大发奇想,难道需要分组查询??
结果验证我的猜想,嘿嘿

此时,我意识到group_concat xx group by极有可能是一个常用用法,果然
查看group_concat xx group by用法
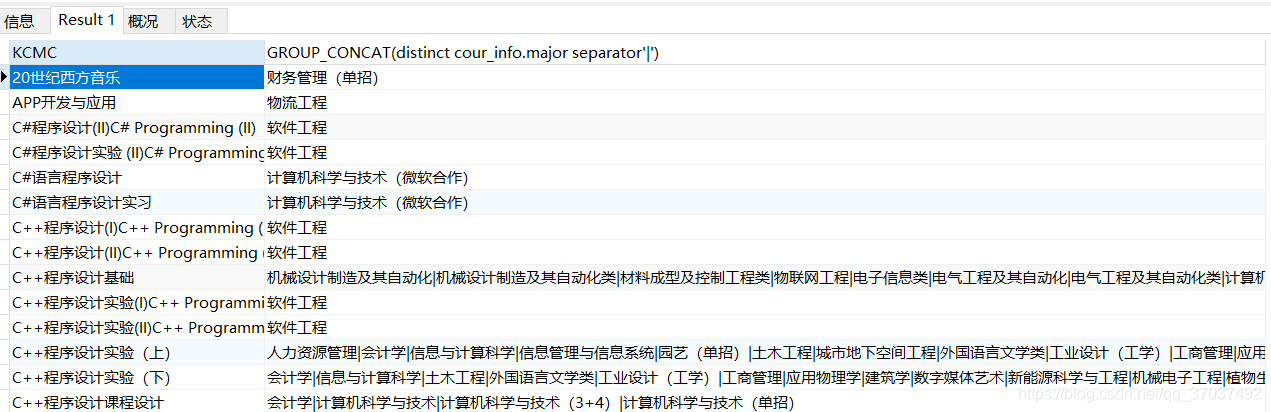
这时,查询出的结果有重复,可以使用distinct去重,代码如下
GROUP_CONCAT(distinct cour_info.major separator '|')
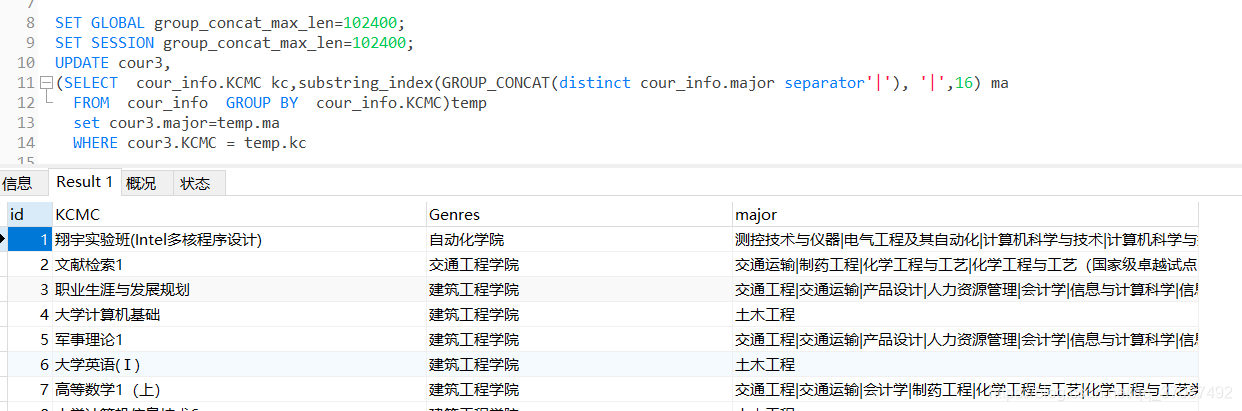
使用SQL语句更新新表
UPDATE cour3,
(SELECT cour_info.KCMC kc,
substring_index(GROUP_CONCAT(distinct cour_info.major separator'|'), '|',16) ma
FROM cour_info GROUP BY cour_info.KCMC)temp
set cour3.major=temp.ma
WHERE cour3.KCMC = temp.kc
因为类别对应过多,这里取16个作为最大的数量
但是发生了错误ERROR 1260 (HY000): Row 17 was cut by GROUP_CONCAT(),这是因为
group_concat存在长度限制
最终添加SQL语句
SET GLOBAL group_concat_max_len=102400;
SET SESSION group_concat_max_len=102400;
解决问题:
好了,本次的分享到这就结束了~~