选一个自己感兴趣的主题
首先选取一个网站,我选电影天堂网站进行爬虫操作,网站网址为http://www.dytt8.net/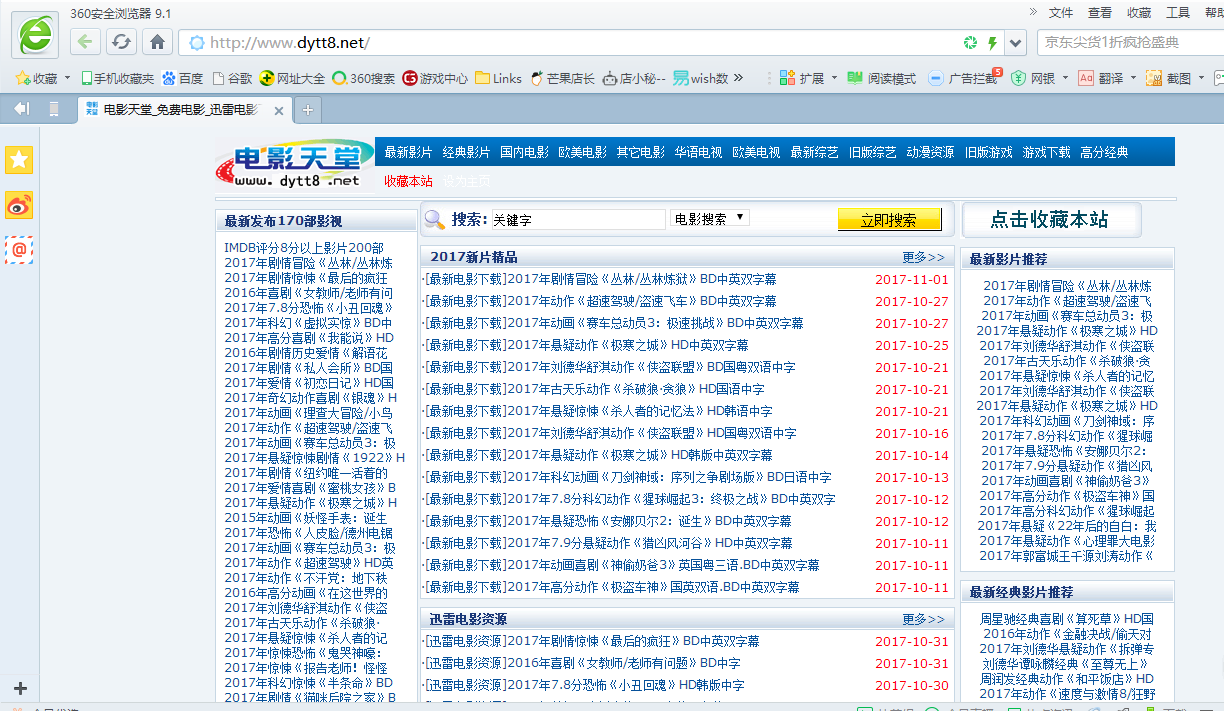
从网络上爬取相关的数据
import requests
from bs4 import BeautifulSoup
url = 'http://www.dytt8.net/'
res = requests.get(url)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
for news in soup.select('li'):
if len(news.select('.ecst'))>0:
title=news.select('.ecst')[0].text
url=news.select('a')[0]['href']
source=soup.select('span')[0].text
resd=requests.get(url)
resd.encoding='utf-8'
soupd=BeautifulSoup(resd.text,'html.parser')
pa=soupd.select('.gmIntro')[0].text
print(title,url,source,pa)
提取到的数据代码
import re
from bs4 import BeautifulSoup
from datetime import datetime
import pandas
import sqlite3
def getdetail(url):
resd = requests.get(url)
resd.encoding='gbk'
soupd=BeautifulSoup(resd.text,'html.parser')
namels={}
#print(url)
for names in soupd.select('.mtext'):
namels['标题'] = names.select('li')[0].contents[0].text
namels['链接']= url
action= names.select('li')[1].text
return(namels)
def onepage(pageurl):
res = requests.get(pageurl)
res.encoding = 'gbk'
soup = BeautifulSoup(res.text,'html.parser')
namels = []
for names in soup.select('dl'):
name = names.select('a')[0]['href']
#print(name)
addname = "http://www.80dyy.cc{}".format(name)
namels.append(getdetail(addname))
#break #这个用来停止循环,等一页的所有信息都完成后删去即可
return namels
newst= []
zurl = 'http://www.80dyy.cc/80kehuan/'
resd = requests.get(zurl)
resd.encoding='gbk'
soup=BeautifulSoup(resd.text,'html.parser')
newst.extend(onepage(zurl))
for i in range(2,4):
listurl='http://www.80dyy.cc/80kehuan/index{}.html'.format(i)
newst.extend(onepage(listurl))
#print(newst)
df = pandas.DataFrame(newst)
with sqlite3.connect("dyactiondb10.sqlite") as db:
df.to_sql('dyactiondb108',con = db)
保存成功

其中一部电影
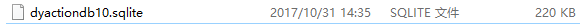

import jieba
import WordCloud
import matplotlib.pyplot as plt
txt = open("ac1.txt","r",encoding='utf-8').read()
wordlist = jieba.cut(text,cut_all=True)
wl_split = "/".join(wordlist)
mywc = WordCloud().generate(text)
plt.imshow(mywc)
plt.axis("off")
plt.show()
