QuerySet API:
我们通常做查询操作的时候,都是通过模型名字.objects的方式进行操作。其实模型名字.objects是一个django.db.models.manager.Manager对象,而Manager这个类是一个“空壳”的类,他本身是没有任何的属性和方法的。他的方法全部都是通过Python动态添加的方式,从QuerySet类中拷贝过来的。示例图如下:
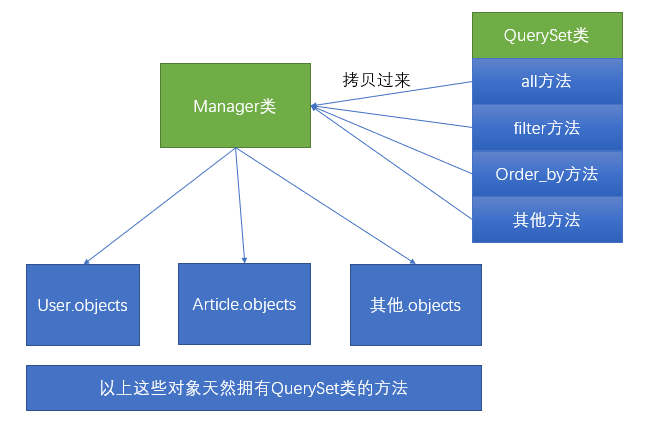
所以我们如果想要学习ORM模型的查找操作,必须首先要学会QuerySet上的一些API的使用。
返回新的QuerySet的方法:
在使用QuerySet进行查找操作的时候,可以提供多种操作。比如过滤完后还要根据某个字段进行排序,那么这一系列的操作我们可以通过一个非常流畅的链式调用的方式进行。比如要从文章表中获取标题为123,并且提取后要将结果根据发布的时间进行排序,那么可以使用以下方式来完成:
articles = Article.objects.filter(title='123').order_by('create_time')
可以看到order_by方法是直接在filter执行后调用的。这说明filter返回的对象是一个拥有order_by方法的对象。而这个对象正是一个新的QuerySet对象。因此可以使用order_by方法。
那么以下将介绍在那些会返回新的QuerySet对象的方法。
-
filter:将满足条件的数据提取出来,返回一个新的QuerySet。具体的filter可以提供什么条件查询。请见查询操作章节。 -
exclude:排除满足条件的数据,返回一个新的QuerySet。示例代码如下:Article.objects.exclude(title__contains='hello')以上代码的意思是提取那些标题不包含
hello的图书。 -
annotate:给QuerySet中的每个对象都添加一个使用查询表达式(聚合函数、F表达式、Q表达式、Func表达式等)的新字段。示例代码如下:articles = Article.objects.annotate(author_name=F("author__name"))以上代码将在每个对象中都添加一个
author__name的字段,用来显示这个文章的作者的年龄。 -
order_by:指定将查询的结果根据某个字段进行排序。如果要倒叙排序,那么可以在这个字段的前面加一个负号。示例代码如下:# 根据创建的时间正序排序 articles = Article.objects.order_by("create_time") # 根据创建的时间倒序排序 articles = Article.objects.order_by("-create_time") # 根据作者的名字进行排序 articles = Article.objects.order_by("author__name") # 首先根据创建的时间进行排序,如果时间相同,则根据作者的名字进行排序 articles = Article.objects.order_by("create_time",'author__name')一定要注意的一点是,多个
order_by,会把前面排序的规则给打乱,而使用后面的排序方式。比如以下代码:articles = Article.objects.order_by("create_time").order_by("author__name")他会根据作者的名字进行排序,而不是使用文章的创建时间。
-
values:用来指定在提取数据出来,需要提取哪些字段。默认情况下会把表中所有的字段全部都提取出来,可以使用values来进行指定,并且使用了values方法后,提取出的QuerySet中的数据类型不是模型,而是在values方法中指定的字段和值形成的字典:articles = Article.objects.values("title",'content') for article in articles: print(article)以上打印出来的
article是类似于{"title":"abc","content":"xxx"}的形式。
如果在values中没有传递任何参数,那么将会返回这个恶模型中所有的属性。 -
values_list:类似于values。只不过返回的QuerySet中,存储的不是字典,而是元组。示例代码如下:articles = Article.objects.values_list("id","title") print(articles)那么在打印
articles后,结果为<QuerySet [(1,'abc'),(2,'xxx'),...]>等。
如果在values_list中只有一个字段。那么你可以传递flat=True来将结果扁平化。示例代码如下:articles1 = Article.objects.values_list("title") >> <QuerySet [("abc",),("xxx",),...]> articles2 = Article.objects.values_list("title",flat=True) >> <QuerySet ["abc",'xxx',...]> -
all:获取这个ORM模型的QuerySet对象。 -
select_related:在提取某个模型的数据的同时,也提前将相关联的数据提取出来。比如提取文章数据,可以使用select_related将author信息提取出来,以后再次使用article.author的时候就不需要再次去访问数据库了。可以减少数据库查询的次数。示例代码如下:article = Article.objects.get(pk=1) >> article.author # 重新执行一次查询语句 article = Article.objects.select_related("author").get(pk=2) >> article.author # 不需要重新执行查询语句了select_related只能用在一对多或者一对一中,不能用在多对多或者多对一中。比如可以提前获取文章的作者,但是不能通过作者获取这个作者的文章,或者是通过某篇文章获取这个文章所有的标签。 -
prefetch_related:这个方法和select_related非常的类似,就是在访问多个表中的数据的时候,减少查询的次数。这个方法是为了解决多对一和多对多的关系的查询问题。比如要获取标题中带有hello字符串的文章以及他的所有标签,示例代码如下:from django.db import connection articles = Article.objects.prefetch_related("tag_set").filter(title__contains='hello') print(articles.query) # 通过这条命令查看在底层的SQL语句 for article in articles: print("title:",article.title) print(article.tag_set.all()) # 通过以下代码可以看出以上代码执行的sql语句 for sql in connection.queries: print(sql)但是如果在使用
article.tag_set的时候,如果又创建了一个新的QuerySet那么会把之前的SQL优化给破坏掉。比如以下代码:tags = Tag.obejcts.prefetch_related("articles") for tag in tags: articles = tag.articles.filter(title__contains='hello') #因为filter方法会重新生成一个QuerySet,因此会破坏掉之前的sql优化 # 通过以下代码,我们可以看到在使用了filter的,他的sql查询会更多,而没有使用filter的,只有两次sql查询 for sql in connection.queries: print(sql)那如果确实是想要在查询的时候指定过滤条件该如何做呢,这时候我们可以使用
django.db.models.Prefetch来实现,Prefetch这个可以提前定义好queryset。示例代码如下:tags = Tag.objects.prefetch_related(Prefetch("articles",queryset=Article.objects.filter(title__contains='hello'))).all() for tag in tags: articles = tag.articles.all() for article in articles: print(article) for sql in connection.queries: print('='*30) print(sql)因为使用了
Prefetch,即使在查询文章的时候使用了filter,也只会发生两次查询操作。 -
defer:在一些表中,可能存在很多的字段,但是一些字段的数据量可能是比较庞大的,而此时你又不需要,比如我们在获取文章列表的时候,文章的内容我们是不需要的,因此这时候我们就可以使用defer来过滤掉一些字段。这个字段跟values有点类似,只不过defer返回的不是字典,而是模型。示例代码如下:articles = list(Article.objects.defer("title")) for sql in connection.queries: print('='*30) print(sql)在看以上代码的
sql语句,你就可以看到,查找文章的字段,除了title,其他字段都查找出来了。当然,你也可以使用article.title来获取这个文章的标题,但是会重新执行一个查询的语句。示例代码如下:articles = list(Article.objects.defer("title")) for article in articles: # 因为在上面提取的时候过滤了title # 这个地方重新获取title,将重新向数据库中进行一次查找操作 print(article.title) for sql in connection.queries: print('='*30) print(sql)defer虽然能过滤字段,但是有些字段是不能过滤的,比如id,即使你过滤了,也会提取出来。 -
only:跟defer类似,只不过defer是过滤掉指定的字段,而only是只提取指定的字段。 -
get:获取满足条件的数据。这个函数只能返回一条数据,并且如果给的条件有多条数据,那么这个方法会抛出MultipleObjectsReturned错误,如果给的条件没有任何数据,那么就会抛出DoesNotExit错误。所以这个方法在获取数据的只能,只能有且只有一条。 -
create:创建一条数据,并且保存到数据库中。这个方法相当于先用指定的模型创建一个对象,然后再调用这个对象的save方法。示例代码如下:article = Article(title='abc') article.save() # 下面这行代码相当于以上两行代码 article = Article.objects.create(title='abc') -
get_or_create:根据某个条件进行查找,如果找到了那么就返回这条数据,如果没有查找到,那么就创建一个。示例代码如下:obj,created= Category.objects.get_or_create(title='默认分类')如果有标题等于
默认分类的分类,那么就会查找出来,如果没有,则会创建并且存储到数据库中。
这个方法的返回值是一个元组,元组的第一个参数obj是这个对象,第二个参数created代表是否创建的。 -
bulk_create:一次性创建多个数据。示例代码如下:Tag.objects.bulk_create([ Tag(name='111'), Tag(name='222'), ]) -
count:获取提取的数据的个数。如果想要知道总共有多少条数据,那么建议使用count,而不是使用len(articles)这种。因为count在底层是使用select count(*)来实现的,这种方式比使用len函数更加的高效。 -
first和last:返回QuerySet中的第一条和最后一条数据。 -
aggregate:使用聚合函数。 -
exists:判断某个条件的数据是否存在。如果要判断某个条件的元素是否存在,那么建议使用exists,这比使用count或者直接判断QuerySet更有效得多。示例代码如下:if Article.objects.filter(title__contains='hello').exists(): print(True) 比使用count更高效: if Article.objects.filter(title__contains='hello').count() > 0: print(True) 也比直接判断QuerySet更高效: if Article.objects.filter(title__contains='hello'): print(True) -
distinct:去除掉那些重复的数据。这个方法如果底层数据库用的是MySQL,那么不能传递任何的参数。比如想要提取所有销售的价格超过80元的图书,并且删掉那些重复的,那么可以使用distinct来帮我们实现,示例代码如下:books = Book.objects.filter(bookorder__price__gte=80).distinct()需要注意的是,如果在
distinct之前使用了order_by,那么因为order_by会提取order_by中指定的字段,因此再使用distinct就会根据多个字段来进行唯一化,所以就不会把那些重复的数据删掉。示例代码如下:orders = BookOrder.objects.order_by("create_time").values("book_id").distinct()那么以上代码因为使用了
order_by,即使使用了distinct,也会把重复的book_id提取出来。 -
update:执行更新操作,在SQL底层走的也是update命令。比如要将所有category为空的article的article字段都更新为默认的分类。示例代码如下:Article.objects.filter(category__isnull=True).update(category_id=3)注意这个方法走的是更新的逻辑。所以更新完成后保存到数据库中不会执行
save方法,因此不会更新auto_now设置的字段。 -
delete:删除所有满足条件的数据。删除数据的时候,要注意on_delete指定的处理方式。 -
切片操作:有时候我们查找数据,有可能只需要其中的一部分。那么这时候可以使用切片操作来帮我们完成。
QuerySet使用切片操作就跟列表使用切片操作是一样的。示例代码如下:books = Book.objects.all()[1:3] for book in books: print(book)切片操作并不是把所有数据从数据库中提取出来再做切片操作。而是在数据库层面使用
LIMIE和OFFSET来帮我们完成。所以如果只需要取其中一部分的数据的时候,建议大家使用切片操作。
什么时候Django会将QuerySet转换为SQL去执行:
生成一个QuerySet对象并不会马上转换为SQL语句去执行。
比如我们获取Book表下所有的图书:
books = Book.objects.all()
print(connection.queries)
我们可以看到在打印connection.quries的时候打印的是一个空的列表。说明上面的QuerySet并没有真正的执行。
在以下情况下QuerySet会被转换为SQL语句执行:
-
迭代:在遍历
QuerySet对象的时候,会首先先执行这个SQL语句,然后再把这个结果返回进行迭代。比如以下代码就会转换为SQL语句:for book in Book.objects.all(): print(book) -
使用步长做切片操作:
QuerySet可以类似于列表一样做切片操作。做切片操作本身不会执行SQL语句,但是如果如果在做切片操作的时候提供了步长,那么就会立马执行SQL语句。需要注意的是,做切片后不能再执行filter方法,否则会报错。 -
调用
len函数:调用len函数用来获取QuerySet中总共有多少条数据也会执行SQL语句。 -
调用
list函数:调用list函数用来将一个QuerySet对象转换为list对象也会立马执行SQL语句。 -
判断:如果对某个
QuerySet进行判断,也会立马执行SQL语句。