使用jTessBoxEditorFX训练Tesseract-OCR教程
注:1,工具是JAVA编写的,所以在使用工具之间,需要安装JAVA环境。
2,安装Tesseract-OCR应用程序,并将目录添加到环境变量中,方便使用cmd调用命令。
步骤一:使用画图软件生成要训练的.tif文件,本例做了34个.tif文件,如下:
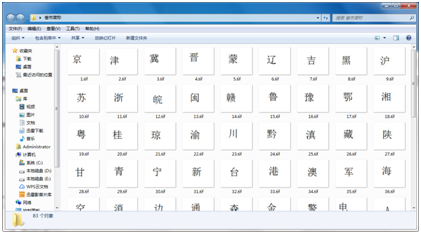
注:图片的格式不限定。我使用灰度图像。
步骤二:使用jTessBoxEditorFX将所有.tif文件合并成一个.tif文件,如图:
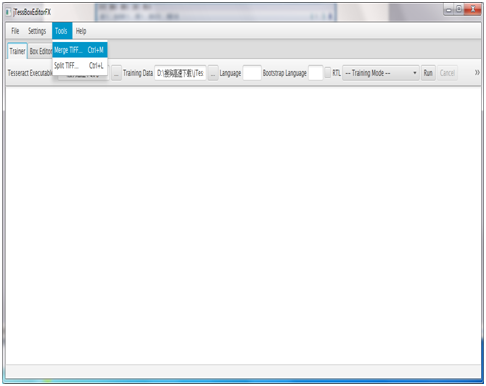


并在该目录下可以看见合并后你所命名的tif文件。如图:
文件名的格式有限制。[lang].[fontname].exp[num].tif
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
例子:num.font.exp0.box
比如我们要训练自定义字库 ec 字体名:unfont
那么我们把tif文件重命名 ec.ufont.exp0.tif
打开cmd窗口,输入以下命令,生成 .box文件
tesseract ec.ufont.exp0.tif ec.ufont.exp0 batch.nochop makebox (主要使用这个命令)
使用训练过的字库生成.box文件
tesseract ec.ufont.exp0.tif ec.ufont.exp0 -l ufont batch.nochop makebox
注:l是L的小写。
先前自己定义tessdata的环境变量 TESSDATA_PREFIX 值为 E: esseract essdata,就是字库的路径。
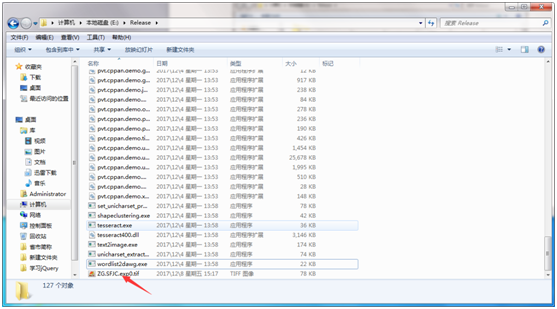
并在该目录下会生成ec.ufont.exp0.box文件,如图:
步骤四:使用jTessBoxEditorFX工具选择Box Editor-Open,打开tif文件(此时同名的tif、box文件必须同处一个目录下,我都给他放在tesseract安装目录下了),如下图:
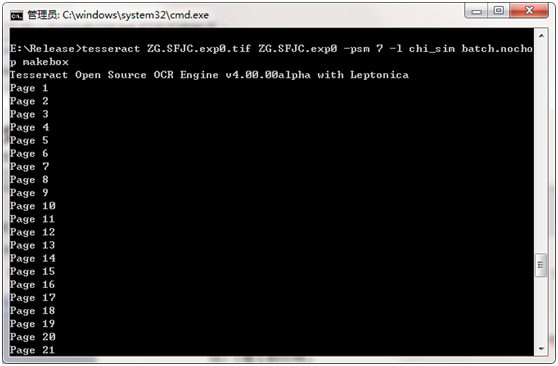
步骤三:打开cmd窗口,输入以下命令,生成box文件,如图:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
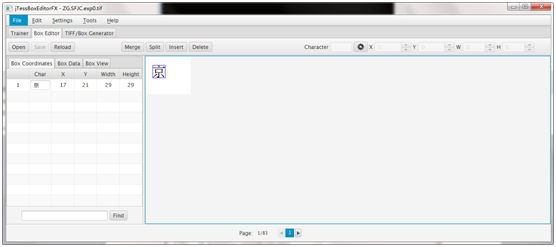
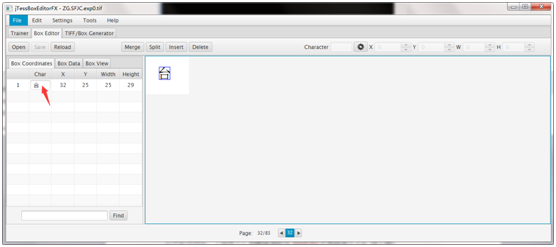
tesseract ec.ufont.exp0.tif ec.ufont.exp0 batch.nochop makebox 查看所有文件并校正错误的文件,如图:
双击红色箭头处,将其修改为台,并单击character 后的后,单击save。矫正完毕。
1. 产生字符特征文件 .tr
tesseract
ec.ufont.exp0.tif ec.ufont.exp0 nobatch box.train
这一步将会产生 ec.ufont.exp0.tr文件和一个 ec.ufont.exp0.txt文件,txt文件貌似没什么用,看看而以。
2.计算字符集(生成unicharset文件)
unicharset_extractor ec.ufont.exp0.box
3.定义字体特征文件
—Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties.txt的字体特征文件
手工建立一个文件font_properties.txt
内容如:ufont 0 0 0 0 0
注意:这里 必须与训练名中的名称保持一致,填入下面内容 ,这里全取值为0,表示字体不是粗体、斜体等等。注:[fontname]:即是ec.ufont.exp0中的ufont。公司文档会加密,编辑后一定要进行解密,否者虽然不会报错,但是运行没有反应。
4.聚集字符特征
1) shapeclustering -F font_properties.txt -U unicharset ec.ufont.exp0.tr
注意:如果font_properties不加扩展名.txt,可能会报错
2) mftraining -F font_properties.txt -U unicharset -O unicharset
ec.ufont.exp0.tr
使用上一步产生的字符集文件unicharset,来生成当前新语言的字符集文件unicharset。同时还会产生图形原型文件inttemp和每个字符所对应的字符
特征数文件pffmtable。最重要的就是这个inttemp文件了,他包含了所有需要产生的字的图形原型。
3)cntraining ec.ufont.exp0.tr
这一步产生字符形状正常化特征文件normproto。
shapeclustering 操作不是必须的,若没有进行此步,在mftraining的时候 会自动进行。
5.改名字
把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上ufont.
6.执行combine_tessdata ufont.
然后把ufont.traineddata放到tessdata目录
注:一定不要忘记加ufont后面的那个点
7.测试
必须确定的是第type 1、3、4、5的数据不是-1,那么一个新的字典就算生成了。
tesseract ec.ufont.exp0.tif papapa -l ufont
tesseract也提出,通过使用多个语言训练库联合使用。如此,新的字体训练库也可以与原有的数据训练库联合使用。如参数 -l 之后 tesseract input.tif output -l eng+newfont。
cntraining和mftraining只能最多采用32个.tr文件,因此,对于相同的字体,你必须从多种语言中,以字体独立的方式,将所有的文件cat到一起来让32种语言结合在一起。cntraining/mftraining以及unicharset_extractor命令行工具必须各自由给定的.tr和.box文件,以相同的顺序,为不同的字体进行不同的过滤。可以提供一个程序来完成以上的事情,并在字符集表中挑出相同字符集。这样会将事情更简单些。