机器学习离不开数据,数据分析离不开pandas。昨天感受了一下,真的方便。按照一般的使用过程,将pandas的常用方法说明一下。
首先,我们拿到一个excel表,我们将之另存为csv文件。因为文件是实验室的资源,我就不分享了。
首先是文件读取
def load_csv(filename): data=pd.read_csv(filename) data = data.drop(data.columns[39:], axis=1) return data
我们调用read_csv文件可以直接读取csv文件。其返回值为DataFrame。excel如果横向拖动太多的话,会生成很多空列。这里我们通过drop方法删掉39列之后的列。
然后pandas为了让显示美观,会在输出信息的时候自动隐藏数据。我们调整参数,使数据全部显示。
pd.set_option('display.max_rows', 10) pd.set_option('display.max_columns', 500) pd.set_option('display.width', 500)
设置最多显示10行,500列。宽度为500.
使用 data.head()可以查看前4行的数据。
print(data.head())

可以看到全部数据都被显示出来了。然后我们可以使用data.info() ,data.discribe()、data.count()查看数据的整体信息。
print(data.info()) print(data.describe()) print(data.count())
data.info()显示的是:

data.describe()显示的是:
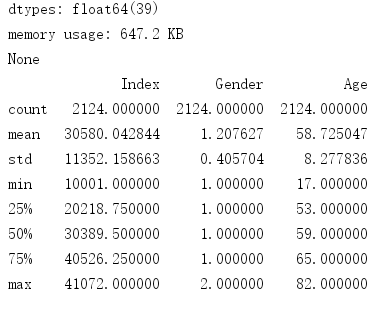
data.count()显示的是:

可以看到数据的值跨度很大,所以我们对数据进行normalization:
keys=X.keys().tolist() keys.remove("Index") keys.remove("Label") for key in keys: #将数值范围限定在-0.5~0.5 #normalize_col=(X[key]-(X[key].max()+X[key].min())/2)/(X[key].max()-X[key].min()) #用mean来normolize normalize_col = (X[key] - X[key].mean()) / (X[key].max() - X[key].min()) X = X.drop(key, axis=1) X[key]=normalize_col
我们可以通过keys中列名来有选择的进行归一化处理。
有时候,有的不和规范的数据我们想删掉:
#删掉JiGan为-1的人 data = data[data["JiGan"].isin([-1.0]) == False]
数据筛选还有其他函数,用到了在慢慢补充吧。