Oracle 数据库优化
目录
一、 (常用)SELECT查询语句中避免使用 ‘*’ 4
二、 减少数据库访问次数: 4
三、 (常用)Oracle构建自增主键 4
四、 (常用)选择最优表名顺序: 5
五、 (常用)WHERE子句中的连接 6
六、 使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表 6
七、 删除全表操作推荐使用TRUNCATE不建议使用DELETE 6
八、 尽量多使用COMMIT: 7
九、 (常用)减少对表的查询: 8
十、 通过内部函数提高SQL效率.: 8
十一、 (常用)使用表的别名(Alias): 8
十二、 (常用)对常用查询条件设置索引 8
十三、 (常用)sql语句用大写 9
十四、 在java代码中尽量少用连接符“+”连接字符串! 9
十五、 避免在索引列上使用NOT 9
十六、 (常用)避免在索引上使用计算 9
十七、 用>=替代> 9
十八、 用UNION替换OR (适用于索引列) 9
十九、 普通查询中用IN来替换OR 10
二十、 避免在索引列上使用IS NULL和IS NOT NULL 10
二十一、 总是使用索引的第一个列: 10
二十二、 用UNION-ALL 替换UNION ( 如果有可能的话): 10
二十三、 避免改变索引列的类型.: 10
二十四、 (常用)某些WHERE子句不使用索引 10
二十五、 避免使用耗费资源的操作: 11
二十六、 优化GROUP BY 11
二十七、 执行计划(解释计划) 11
一、(常用)SELECT查询语句中避免使用 ‘*’
二、减少数据库访问次数:
减少数据库IO操作压力
三、(常用)Oracle构建自增主键
① 创建带有主键的表
CREATE TABLE 表name(
id INT PRIMARY KEY,
.
.
.
);
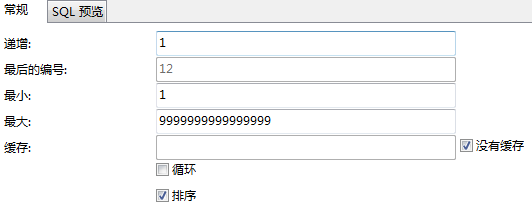
②创建一个序列(1~9999999999999999)
CREATE SEQUENCE 序列name INCREMENT BY 1 START WITH 1
MINVALUE 1 MAXVALUE 9999999999999999 NOCACHE ORDER;
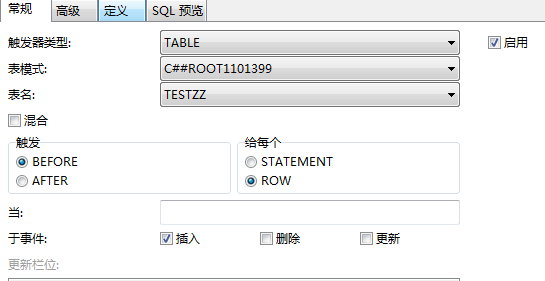
③触发器实现
CREATE OR REPLACE trigger 触发器name
BEFORE INSERT ON 表name
FOR EACH ROW BEGIN
SELECT 序列name.NEXTVAL INTO:new.id FROM dual;
END;
注:新建序列&新建触发器可以在SQL developer 当前用户下的相关文件夹中查看
主键自增 = 主键 + 序列 + 触发器
④ 若删除一张表的数据时想让自增长码重新计数,在删除后点击序列将LAST_NUMBER 改为1或者想要开始的数字。
四、(常用)选择最优表名顺序:
Oracle解析器解析规则从右向左的顺序处理From子句表名,此时宜将记录条数最少的表或者交叉表(被其他引用的表)作为基础表(From子句中写最后的表)
五、(常用)WHERE子句中的连接
Oracle解析器解析WHERE子句采用从下到上的顺序解析,过滤大量数据的筛选条件推荐写在WHERE子句最后
六、使用DECODE函数可以避免重复扫描相同记录或重复连接相同的表
七、删除全表操作推荐使用TRUNCATE不建议使用DELETE
TRUNCATE将会彻底删除数据不可恢复,消耗资源小于DELETE。
① 在功能上,truncate是清空一个表的内容,它相当于delete from table_name
② delete是dml操作,truncate是ddl操作;因此,用delete删除整个表的数据时,会产生大量的roolback(回滚),占用很多的rollback segments(回滚段), 而truncate不会
③ 在内存中,用delete删除数据,表空间中其被删除数据的表占用的空间还在,便于以后的使用,另外它是“假相”的删除,相当于windows中用delete删除数据是把数据放到回收站中,还可以恢复,当然如果这个时候重新启动系统(OS或者RDBMS),它也就不能恢复了!
而用truncate清除数据,内存中表空间中其被删除数据的表占用的空间会被立即释放,相当于windows中用shift+delete删除数据,不能够恢复!
④ truncate 调整high water mark 而delete不;truncate之后,TABLE的HWM退回到 INITIAL和NEXT的位置(默认)delete 则不可以。
⑤truncate只能对TABLE,delete 可以是table,view,synonym
⑥TRUNCATE TABLE 的对象必须是本模式下的,或者有drop any table的权限 而 DELETE 则是对象必须是本模式下的,或被授予 DELETE ON SCHEMA.TABLE 或DELETE ANY TABLE的权限
⑦在外层中,truncate或者delete后,其占用的空间都将释放
⑧truncate和delete只删除数据,而drop则删除整个表(结构和数据)
小技巧:在删除大数据量时(一个表中大部分数据时),
先将不需要删除的数据复制到一个临时表中;
trunc table 表;
将不需要删除的数据复制回来。
八、尽量多使用COMMIT:
尽可能使用COMMIT需求释放的资源而减少:
COMMIT所释放的资源:
a. 回滚段上用于恢复数据的信息.
b. 被程序语句获得的锁
c. redo log buffer 中的空间
d. ORACLE为管理上述3种资源中的内部花费
九、(常用)减少对表的查询:
在含有子查询的SQL语句中,要特别注意减少对表的查询..
十、 通过内部函数提高SQL效率.:
复杂的SQL往往牺牲了执行效率. 更倾向于运用函数解决问题
十一、(常用)使用表的别名(Alias):
当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上.这样一来,就可以减少解析的时间并减少那些由Column歧义引起的语法错误.
十二、(常用)对常用查询条件设置索引
索引是表的一个概念部分,用来提高检索数据的效率,ORACLE使用了一个复杂的自平衡B-tree结构. 通常,通过索引查询数据比全表扫描要快. 当ORACLE找出执行查询和Update语句的最佳路径时, ORACLE优化器将使用索引. 同样在联结多个表时使用索引也可以提高效率. 另一个使用索引的好处是,它提供了主键(primary key)的唯一性验证.。那些LONG或LONG RAW数据类型, 你可以索引几乎所有的列. 通常, 在大型表中使用索引特别有效. 当然,你也会发现, 在扫描小表时,使用索引同样能提高效率. 虽然使用索引能得到查询效率的提高,但是我们也必须注意到它的代价. 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时, 索引本身也会被修改. 这意味着每条记录的INSERT , DELETE , UPDATE将为此多付出4 , 5 次的磁盘I/O . 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢.。定期的重构索引是有必要的:
ALTER INDEX <INDEXNAME> REBUILD <TABLESPACENAME>
十三、(常用)sql语句用大写
因为oracle总是先解析sql语句,把小写的字母转换成大写的再执行
十四、在java代码中尽量少用连接符“+”连接字符串!
十五、避免在索引列上使用NOT
NOT会产生在和在索引列上使用函数相同的影响. 当ORACLE”遇到”NOT,他就会停止使用索引转而执行全表扫描.
十六、(常用)避免在索引上使用计算
索引列是函数的一部分,优化器将不使用索引而使用全表扫描.
十七、用>=替代>
数据记录处理机制问题
十八、用UNION替换OR (适用于索引列)
用UNION替换WHERE子句中的OR将会起到较好的效果. 对索引列使用OR将造成全表扫描. 注意, 以上规则只针对多个索引列有效. 如果有column没有被索引, 查询效率可能会因为你没有选择OR而降低
十九、普通查询中用IN来替换OR
二十、避免在索引列上使用IS NULL和IS NOT NULL
尽量避免在字段信息中出现空值,在索引中出现空值字段会导致ORACLE无法使用该索引
二十一、总是使用索引的第一个列:
如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引. 这也是一条简单而重要的规则,当仅引用索引的第二个列时,优化器使用了全表扫描而忽略了索引
二十二、 用UNION-ALL 替换UNION ( 如果有可能的话):
当SQL语句需要UNION两个查询结果集合时,这两个结果集合会以UNION-ALL的方式被合并, 然后在输出最终结果前进行排序. 如果用UNION ALL替代UNION, 这样排序就不是必要了
UNION ALL 将重复输出两个结果集合中相同记录,所以请根据具体需求使用。
二十三、避免改变索引列的类型.:
当比较不同数据类型的数据时, ORACLE自动对列进行简单的类型转换. .
二十四、(常用)某些WHERE子句不使用索引
(1)‘!=' 将不使用索引. 记住, 索引只能告诉你什么存在于表中, 而不能告诉你什么不存在于表中.
(2)‘||'是字符连接函数. 就象其他函数那样, 停用了索引.
(3)‘+'是数学函数. 就象其他数学函数那样, 停用了索引.
(4)相同的索引列不能互相比较,这将会启用全表扫描.
二十五、 避免使用耗费资源的操作:
带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY的SQL语句会启动SQL引擎
执行耗费资源的排序(SORT)功能. DISTINCT需要一次排序操作, 而其他的至少需要执行两次排序. 通常, 带有UNION, MINUS , INTERSECT的SQL语句都可以用其他方式重写.
二十六、 优化GROUP BY
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉
二十七、执行计划(解释计划)
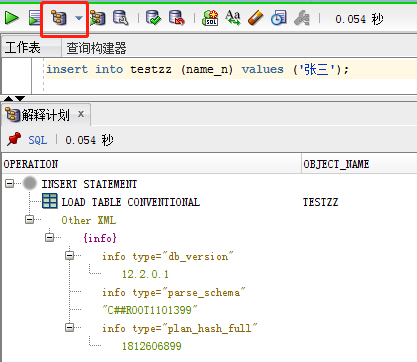
① SQL developer 中SQL语句界面点击解释计划按钮,或者SQL语句界面使用快捷键 F10 打开执行计划界面
② 在Navicat Premium 中SQL 语句界面点击解释按钮
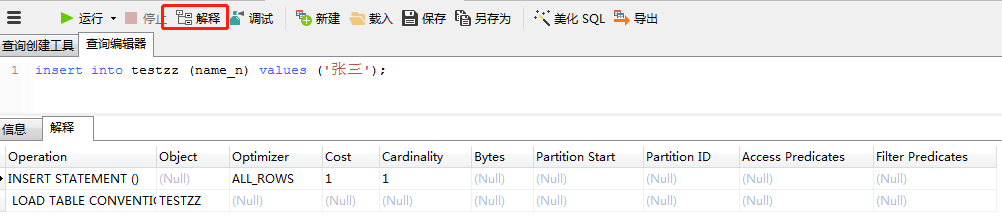
执行计划(解释计划)相关SQL

① DELETE PLAN_TABLE
② EXPLAIN PLAN FOR SQL语句
③ SELECT
LPAD (' ', LEVEL - 1) || OPERATION || ' (' || OPTIONS || ')' "Operation",
OBJECT_NAME "Object",
OPTIMIZER "Optimizer",
COST "Cost",
CARDINALITY "Cardinality",
BYTES "Bytes",
PARTITION_START "Partition Start",
PARTITION_ID "Partition ID",
ACCESS_PREDICATES "Access Predicates",
FILTER_PREDICATES "Filter Predicates"
FROM
PLAN_TABLE START WITH ID = 0 CONNECT BY PRIOR ID = PARENT_ID
执行计划:
在SQL执行之后相关内容存储于表PLAN_TABLE中。
|
字段 |
数据类型 |
NULL |
描述 |
|
STATEMENT_ID |
VARCHAR2(30) |
EXPLAIN PLAN语句中指定的可选STATEMENT_ID参数的值 |
|
|
PLAN_ID |
NUMBER |
数据库中计划的唯一标识符 |
|
|
TIMESTAMP |
DATE |
EXPLAIN PLAN语句生成的日期和时间(产生) |
|
|
REMARKS(注释) |
VARCHAR2(4000) |
任何评论(注释)(最多4000字节)你想关联(关联)与解释计划的每一步。 此列用于指示查询是否使用大纲或SQL配置文件。 如果您需要在PLAN_TABLE的任何行上添加或更改备注,请使用UPDATE语句修改PLAN_TABLE的行。 |
|
|
OPERATION |
VARCHAR2(30) |
在此步骤中执行的内部(内部)操作的名称。 在为语句生成的第一行中,该列包含以下值之一: DELETE STATEMENT INSERT STATEMENT SELECT STATEMENT UPDATE STATEMENT |
|
|
OPTIONS(选项) |
VARCHAR2(255) |
操作栏中描述的操作变化(变动) |
|
|
OBJECT_NODE |
VARCHAR2(128) |
用于引用对象的数据库链接的名称(表名或视图名称)。 对于使用并行执行的本地查询,此列描述了操作输出的消耗顺序(消费) |
|
|
OBJECT_OWNER |
VARCHAR2(128) |
表或索引的所有者 |
|
|
OBJECT_NAME |
VARCHAR2(128) |
表或索引的名称 |
|
|
OBJECT_ALIAS |
VARCHAR2(261) |
SQL语句中表或视图的唯一别名(别名)。 对于索引,它是底层(底层)表的对象别名。 |
|
|
OBJECT_INSTANCE |
NUMBER(38) |
在原始语句中出现对象的顺序位置(顺序数位置)时对应的数目。 编号从左向右进行(往前),从外部到内部遵守原始声明文本。 查看扩展结果的不可预知的数字。 |
|
|
OBJECT_TYPE |
VARCHAR2(30) |
提供关于对象的描述性信息的修饰符; 例如,索引的非唯一性 |
|
|
OPTIMIZER |
VARCHAR2(255) |
优化器的当前模式 |
|
|
SEARCH_COLUMNS |
NUMBER |
目前未使用 |
|
|
ID |
NUMBER(38) |
分配给执行计划中每个步骤的编号 |
|
|
PARENT_ID |
NUMBER(38) |
在ID步骤的输出上操作的下一个执行步骤的ID |
|
|
DEPTH |
NUMBER(38) |
该计划表示的行源树中操作的深度(深度)。 该值可用于缩小计划表格报告中的行(表示)。 |
|
|
POSITION |
NUMBER(38) |
对于第一行输出,这表示优化器执行语句的估计成本(优化器估计的消耗)。 对于其他行,它表示相对于同一父母的其他孩子的相对位置。 |
|
|
COST |
NUMBER(38) |
根据优化程序的查询方法(途径)估算的操作成本。 表访问操作的成本不确定。 此栏的值没有任何特定的测量单位(测量特定的单位); 它仅仅是(仅)用来比较执行计划成本的加权值。 该列的值是CPU_COST和IO_COST列的函数。 |
|
|
CARDINALITY |
NUMBER(38) |
通过查询优化方法估算操作访问的行数 |
|
|
BYTES |
NUMBER(38) |
通过查询优化方法估算操作访问的字节数 |
|
|
OTHER_TAG |
VARCHAR2(255) |
介绍OTHER栏的内容: SERIAL(顺序的) - 串行执行。 目前,在这种情况下,SQL不会加载到OTHER栏中。 SERIAL_FROM_REMOTE - 在远程站点执行串行(位置)。 PARALLEL_FROM_SERIAL - 串行执行。 步的输出被分区或广播(广播)到并行执行服务器。 PARALLEL_TO_SERIAL - 并行执行。 步骤输出返回到串行查询协调器(QC)(查询协调)过程。 PARALLEL_TO_PARALLEL - 并行执行。 步骤的输出被重新分区到第二组并行执行服务器。 PARALLEL_COMBINED(联合)_WITH_PARENT - 并行执行; 步骤输出在相同的并行过程中进入下一步。 没有进程间通信(父进程间通信)。 PARALLEL_COMBINED_WITH_CHILD - 并行执行。 步骤的输入来自同一个并行处理中的先前(先)步骤。 没有来自孩子的进程间通信。 |
|
|
PARTITION_START |
VARCHAR2(255) |
开始分区的一系列访问分区: number - 开始分区已由SQL编译器(编译)识别,其分区号由数字给出 KEY - 启动分区将在运行时根据分区键值进行标识 ROW REMOVE_LOCATION - 开始分区(与停止分区相同)将在运行时根据正在检索的每个记录的位置计算(检索)。 记录位置(位置)由用户或全局索引获得(获得)。 INVALID - 访问分区的范围为空 |
|
|
PARTITION_STOP |
VARCHAR2(255) |
停止分区的一系列访问分区: number - 停止分区已由SQL编译器识别,其分区号由数字给出 KEY - 停止分区将在运行时从分区键值中识别 ROW REMOVE_LOCATION - 停止分区(与开始分区相同)将在运行时从每个正在检索的记录的位置计算得出。 记录位置由用户或全局索引获取。 INVALID - 访问分区的范围为空 |
|
|
PARTITION_ID |
NUMBER(38) |
计算了PARTITION_START和PARTITION_STOP列的值对的步骤 |
|
|
OTHER |
LONG |
其他特定于执行步骤的信息,用户可能会觉得有用(请参阅OTHER_TAG专栏) |
|
|
OTHER_XML |
CLOB |
提供特定于执行计划执行步骤的额外信息。 本专栏的内容是使用XML构建的,因为可以在那里存储多条信息。 这包括: 查询被解析的模式的名称 生成解释计划的Oracle数据库的版本号 与执行计划相关的哈希值 大纲的名称(如果有)或用于构建执行计划的SQL配置文件 指出是否使用动态统计来制定计划 轮廓数据,可用于重新生成相同计划的一组优化器提示 |
|
|
DISTRIBUTION |
VARCHAR2(30) |
用于将生产者查询服务器的行分配给使用者查询服务器的方法 另请参见:Oracle数据库数据仓库指南了解有关使用者和生产者查询服务器的更多信息 |
|
|
CPU_COST |
NUMBER(38) |
按查询优化程序的方法估算的操作的CPU成本。 该列的值与操作所需的机器周期数成正比。 对于使用基于规则的方法的语句,此列为NULL。 |
|
|
IO_COST |
NUMBER(38) |
按查询优化程序的方法估算的操作的I / O成本。 该列的值与操作读取的数据块的数量成正比。 对于使用基于规则的方法的语句,此列为NULL。 |
|
|
TEMP_SPACE |
NUMBER(38) |
临时空间(以字节为单位)由操作使用,由查询优化器的方法估计。 对于使用基于规则的方法的语句,或者对于不使用任何临时空间的操作,此列为NULL。 |
|
|
ACCESS_PREDICATES |
VARCHAR2(4000) |
用于在访问结构中查找行的谓词。 例如,启动或停止索引范围扫描的谓词。 |
|
|
FILTER_PREDICATES |
VARCHAR2(4000) |
用于在生成它们之前过滤行的谓词 |
|
|
PROJECTION |
VARCHAR2(4000) |
表达式由操作产生(Expressions produced by the operation) |
|
|
TIME |
NUMBER(38) |
通过查询优化估计的操作的已用时间(以秒为单位)。 对于使用基于规则的方法的语句,此列为NULL。 |
|
|
QBLOCK_NAME |
VARCHAR2(30) |
查询块的名称(由系统生成或由具有QB_NAME提示的用户定义) |
参考资料:PLAN_TABLE