一、背景
分页应该是极为常见的数据展现方式了,一般在数据集较大而无法在单个页面中呈现时会采用分页的方法。
各种前端UI组件在实现上也都会支持分页的功能,而数据交互呈现所相应的后端系统、数据库都对数据查询的分页提供了良好的支持。
以几个流行的数据库为例:
查询表 t_data 第 2 页的数据(假定每页 5 条)
MySQL 的做法:
select * from t_data limit 5,5
PostGreSQL 的做法:
select * from t_data limit 5 offset 5
MongoDB 的做法:
db.t_data.find().limit(5).skip(5);
尽管每种数据库的语法不尽相同,通过一些开发框架封装的接口,我们可以不需要熟悉这些差异。如 SpringData 提供的分页接口:
public interface PagingAndSortingRepository<t, serializable="" extends="">
extends CrudRepository<t,> {
Page findAll(Pageable pageable);
}
这样看来,开发一个分页的查询功能是非常简单的。
然而万事皆不可能尽全尽美,尽管上述的数据库、开发框架提供了基础的分页能力,在面对日益增长的海量数据时却难以应对,一个明显的问题就是查询性能低下!
那么,面对千万级、亿级甚至更多的数据集时,分页功能该怎么实现?
下面,我以 MongoDB 作为背景来探讨几种不同的做法。
二、传统方案
就是最常规的方案,假设 我们需要对文章 articles 这个表(集合) 进行分页展示,一般前端会需要传递两个参数:
页码(当前是第几页)
页大小(每页展示的数据个数)
按照这个做法的查询方式,如下图所示:

因为是希望最后创建的文章显示在前面,这里使用了_id 做降序排序。
其中红色部分语句的执行计划如下:
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "appdb.articles",
"indexFilterSet" : false,
"parsedQuery" : {
"$and" : []
},
"winningPlan" : {
"stage" : "SKIP",
"skipAmount" : 19960,
"inputStage" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"_id" : 1
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "backward",
"indexBounds" : {
"_id" : [
"[MaxKey, MinKey]"
]
...
}
可以看到随着页码的增大,skip 跳过的条目也会随之变大,而这个操作是通过 cursor 的迭代器来实现的,对于cpu的消耗会比较明显。
而当需要查询的数据达到千万级及以上时,会发现响应时间非常的长,可能会让你几乎无法接受!
或许,假如你的机器性能很差,在数十万、百万数据量时已经会出现瓶颈
三、改良做法
既然传统的分页方案会产生 skip 大量数据的问题,那么能否避免呢?答案是可以的。
改良的做法为:
选取一个唯一有序的关键字段,比如 _id,作为翻页的排序字段;
每次翻页时以当前页的最后一条数据_id值作为起点,将此并入查询条件中。
如下图所示:
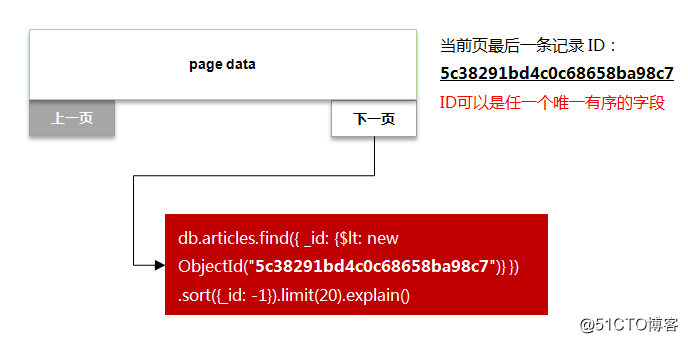
修改后的语句执行计划如下:
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "appdb.articles",
"indexFilterSet" : false,
"parsedQuery" : {
"_id" : {
"$lt" : ObjectId("5c38291bd4c0c68658ba98c7")
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"_id" : 1
},
"indexName" : "_id_",
"isMultiKey" : false,
"direction" : "backward",
"indexBounds" : {
"_id" : [
"(ObjectId('5c38291bd4c0c68658ba98c7'), ObjectId('000000000000000000000000')]"
]
...
}
可以看到,改良后的查询操作直接避免了昂贵的 skip 阶段,索引命中及扫描范围也是非常合理的!
性能对比
为了对比这两种方案的性能差异,下面准备了一组测试数据。
测试方案
准备10W条数据,以每页20条的参数从前往后翻页,对比总体翻页的时间消耗
db.articles.remove({});
var count = 100000;
var items = [];
for(var i=1; i<=count; i++){
var item = {
"title" : "论年轻人思想建设的重要性-" + i,
"author" : "王小兵-" + Math.round(Math.random() * 50),
"type" : "杂文-" + Math.round(Math.random() * 10) ,
"publishDate" : new Date(),
} ;
items.push(item);
if(i%1000==0){
db.test.insertMany(items);
print("insert", i);
items = [];
}
}
传统翻页脚本
function turnPages(pageSize, pageTotal){
print("pageSize:", pageSize, "pageTotal", pageTotal)
var t1 = new Date();
var dl = [];
var currentPage = 0;
//轮询翻页
while(currentPage < pageTotal){
var list = db.articles.find({}, {_id:1}).sort({_id: -1}).skip(currentPage*pageSize).limit(pageSize);
dl = list.toArray();
//没有更多记录
if(dl.length == 0){
break;
}
currentPage ++;
//printjson(dl)
}
var t2 = new Date();
var spendSeconds = Number((t2-t1)/1000).toFixed(2)
print("turn pages: ", currentPage, "spend ", spendSeconds, ".")
}
改良翻页脚本
function turnPageById(pageSize, pageTotal){
print("pageSize:", pageSize, "pageTotal", pageTotal)
var t1 = new Date();
var dl = [];
var currentId = 0;
var currentPage = 0;
while(currentPage ++ < pageTotal){
//以上一页的ID值作为起始值
var condition = currentId? {_id: {$lt: currentId}}: {};
var list = db.articles.find(condition, {_id:1}).sort({_id: -1}).limit(pageSize);
dl = list.toArray();
//没有更多记录
if(dl.length == 0){
break;
}
//记录最后一条数据的ID
currentId = dl[dl.length-1]._id;
}
var t2 = new Date();
var spendSeconds = Number((t2-t1)/1000).toFixed(2)
print("turn pages: ", currentPage, "spend ", spendSeconds, ".")
}
以100、500、1000、3000页数的样本进行实测,结果如下:

可见,当页数越大(数据量越大)时,改良的翻页效果提升越明显!
这种分页方案其实采用的就是时间轴(TImeLine)的模式,实际应用场景也非常的广,比如Twitter、微博、朋友圈动态都可采用这样的方式。
而同时除了上述的数据库之外,HBase、ElastiSearch 在Range Query的实现上也支持这种模式。
四、完美的分页
时间轴(TimeLine)的模式通常是做成“加载更多”、上下翻页这样的形式,但无法自由的选择某个页码。
那么为了实现页码分页,同时也避免传统方案带来的 skip 性能问题,我们可以采取一种折中的方案。
这里参考Google搜索结果页作为说明:

通常在数据量非常大的情况下,页码也会有很多,于是可以采用页码分组的方式。
以一段页码作为一组,每一组内数据的翻页采用ID 偏移量 + 少量的 skip 操作实现
具体的操作如下图所示:

实现步骤郑州不孕不育医院:http://yyk.39.net/zz3/zonghe/1d427.html/郑州不孕不育医院哪家好:http://yyk.39.net/zz3/zonghe/1d427.html/郑州不孕不育医院排名:http://yyk.39.net/zz3/zonghe/1d427.html/
对页码进行分组(groupSize=8, pageSize=20),每组为8个页码;
提前查询 end_offset,同时获得本组页码数量:
db.articles.find({ _id: { $lt: start_offset } }).sort({_id: -1}).skip(20*8).limit(1)
分页数据查询以本页组 start_offset 作为起点,在有限的页码上翻页(skip)
由于一个分组的数据量通常很小(8*20=160),在分组内进行skip产生的代价会非常小,因此性能上可以得到保证。
小结
随着物联网,大数据业务的白热化,一般企业级系统的数据量也会呈现出快速的增长。而传统的数据库分页方案在海量数据场景下很难满足性能的要求。
在本文的探讨中,主要为海量数据的分页提供了几种常见的优化方案(以MongoDB作为实例),并在性能上做了一些对比,旨在提供一些参考。