目录
声明:本文转载自 小猿取经,在排版和内容上做了点小改动
selenium 模块
selenium 最初是一个自动化测试工具,而爬虫中使用它主要是为了解决 requests 模块无法直接执行 JavaScript 代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果(可支持多种浏览器,下不同的浏览器驱动即可)
但相对 request 模块而言,性能不是很高(但它可以和 request 合用,用 selenium 来模拟登录,然后再拿着 cookie 用 request 来接着操作)(可以用这个模块来绕过禁掉 request 模块的那部分)
- 安装 selenium:
pip3 install selenium - 下载对应版本的浏览器驱动(可参照下面的这张长截图,写的比较通俗易懂(原文地址:
https://www.cnblogs.com/babycomeon/p/11909567.html))
以谷歌浏览器为例:
下载与电脑上谷歌浏览器对应版本的浏览器驱动 chromdriver.exe,并把它放到 python 安装路径的 scripts 目录下(其实也可以放在)
对应版本可以在网上搜对照表(其实差几个小版本问题不大)
chromedriver 浏览器驱动下载与存放
原文地址:
https://www.cnblogs.com/babycomeon/p/11909567.html
淘宝的镜像源: http://npm.taobao.org/mirrors/chromedriver
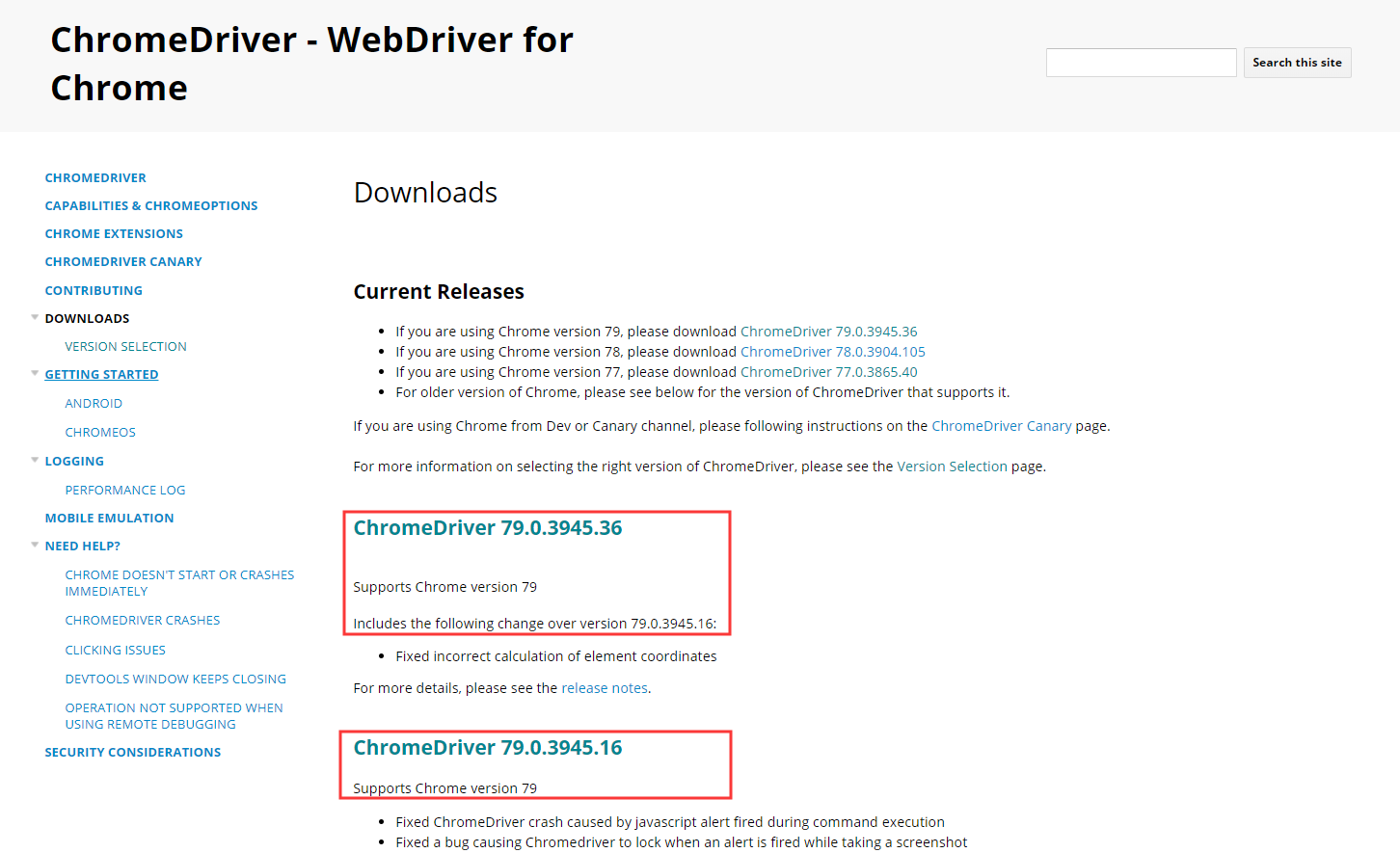
下图链接:https://sites.google.com/a/chromium.org/chromedriver/downloads
# 验证安装
from selenium import webdriver
driver = webdriver.Chrome() #弹出浏览器
driver.get('https://www.baidu.com')
driver.page_source
# 注意:
# selenium3 默认支持的 webdriver 是 Firfox,而 Firefox 需要安装 geckodriver
# 下载链接:https://github.com/mozilla/geckodriver/releases
PhantomJS 无界面浏览器
PhantomJS 已经不再更新了, chrome 从 59 / 60 正式版 开始后便支持 Headless mode 了,即支持无界面,故已经不需要用 PhantomJS 了
标签元素查找方法
#官网链接:http://selenium-python.readthedocs.io/locating-elements.html
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
import time
driver=webdriver.Chrome()
driver.get('https://www.baidu.com')
wait=WebDriverWait(driver,10)
try:
#===============所有方法===================
# 1、find_element_by_id
# 2、find_element_by_link_text
# 3、find_element_by_partial_link_text
# 4、find_element_by_tag_name
# 5、find_element_by_class_name
# 6、find_element_by_name
# 7、find_element_by_css_selector
# 8、find_element_by_xpath
# 强调:
# 1、上述均可以改写成find_element(By.ID,'kw')的形式
# 2、find_elements_by_xxx的形式是查找到多个元素,结果为列表
```
#===============示范用法===================
# 1、find_element_by_id
print(driver.find_element_by_id('kw'))
# 2、find_element_by_link_text
# login=driver.find_element_by_link_text('登录')
# login.click()
# 3、find_element_by_partial_link_text
login=driver.find_elements_by_partial_link_text('录')[0]
login.click()
# 4、find_element_by_tag_name
print(driver.find_element_by_tag_name('a'))
# 5、find_element_by_class_name
button=wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'tang-pass-footerBarULogin')))
button.click()
# 6、find_element_by_name
input_user=wait.until(EC.presence_of_element_located((By.NAME,'userName')))
input_pwd=wait.until(EC.presence_of_element_located((By.NAME,'password')))
commit=wait.until(EC.element_to_be_clickable((By.ID,'TANGRAM__PSP_10__submit')))
input_user.send_keys('18611453110')
input_pwd.send_keys('xxxxxx')
commit.click()
# 7、find_element_by_css_selector
driver.find_element_by_css_selector('#kw')
# 8、find_element_by_xpath
```
time.sleep(5)
finally:
driver.close()
xpath 格式用法
#官网链接:http://selenium-python.readthedocs.io/locating-elements.html
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
import time
driver=webdriver.PhantomJS()
driver.get('https://doc.scrapy.org/en/latest/_static/selectors-sample1.html')
# wait=WebDriverWait(driver,3)
driver.implicitly_wait(3) #使用隐式等待
try:
# find_element_by_xpath
#//与/
# driver.find_element_by_xpath('//body/a') # 开头的//代表从整篇文档中寻找,body之后的/代表body的儿子,这一行找不到就会报错了
driver.find_element_by_xpath('//body//a') # 开头的//代表从整篇文档中寻找,body之后的//代表body的子子孙孙
driver.find_element_by_css_selector('body a')
```
#取第n个
res1=driver.find_elements_by_xpath('//body//a[1]') #取第一个a标签
print(res1[0].text)
#按照属性查找,下述三者查找效果一样
res1=driver.find_element_by_xpath('//a[5]')
res2=driver.find_element_by_xpath('//a[@href="image5.html"]')
res3=driver.find_element_by_xpath('//a[contains(@href,"image5")]') #模糊查找
print('==>', res1.text)
print('==>',res2.text)
print('==>',res3.text)
```
```
#其他
res1=driver.find_element_by_xpath('/html/body/div/a')
print(res1.text)
res2=driver.find_element_by_xpath('//a[img/@src="image3_thumb.jpg"]') #找到子标签img的src属性为image3_thumb.jpg的a标签
print(res2.tag_name,res2.text)
res3 = driver.find_element_by_xpath("//input[@name='continue'][@type='button']") #查看属性name为continue且属性type为button的input标签
res4 = driver.find_element_by_xpath("//*[@name='continue'][@type='button']") #查看属性name为continue且属性type为button的所有标签
```
```
time.sleep(5)
```
finally:
driver.close()
获取标签属性
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
browser=webdriver.Chrome()
browser.get('https://www.amazon.cn/')
wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'cc-lm-tcgShowImgContainer')))
tag=browser.find_element(By.CSS_SELECTOR,'#cc-lm-tcgShowImgContainer img')
#获取标签属性,
print(tag.get_attribute('src'))
#获取标签ID,位置,名称,大小(了解)
print(tag.id)
print(tag.location)
print(tag.tag_name)
print(tag.size)
browser.close()
等待元素被加载
# 1、selenium只是模拟浏览器的行为,而浏览器解析页面是需要时间的(执行css,js),一些元素可能需要过一段时间才能加载出来,为了保证能查找到元素,必须等待
# 2、等待的方式分两种:
# 隐式等待:在browser.get('xxx')前就设置,针对所有元素有效
# 显式等待:在browser.get('xxx')之后设置,只针对某个元素有效
# -------------隐式等待-------------
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
browser=webdriver.Chrome()
#隐式等待:在查找所有元素时,如果尚未被加载,则等10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER)
contents=browser.find_element_by_id('content_left') #没有等待环节而直接查找,找不到则会报错
print(contents)
browser.close()
# -------------显式等待-------------
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER)
#显式等待:显式地等待某个元素被加载
wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left')))
contents=browser.find_element(By.CSS_SELECTOR,'#content_left')
print(contents)
browser.close()
显式等待
元素交互操作
点击清空
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
browser=webdriver.Chrome()
browser.get('https://www.amazon.cn/')
wait=WebDriverWait(browser,10)
input_tag=wait.until(EC.presence_of_element_located((By.ID,'twotabsearchtextbox')))
input_tag.send_keys('iphone 8')
button=browser.find_element_by_css_selector('#nav-search > form > div.nav-right > div > input')
button.click()
import time
time.sleep(3)
input_tag=browser.find_element_by_id('twotabsearchtextbox')
input_tag.clear() #清空输入框
input_tag.send_keys('iphone7plus')
button=browser.find_element_by_css_selector('#nav-search > form > div.nav-right > div > input')
button.click()
# browser.close()
ActionChains
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
import time
driver = webdriver.Chrome()
driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
wait=WebDriverWait(driver,3)
# driver.implicitly_wait(3) # 使用隐式等待
try:
driver.switch_to.frame('iframeResult') ##切换到iframeResult
sourse=driver.find_element_by_id('draggable')
target=driver.find_element_by_id('droppable')
```
#方式一:基于同一个动作链串行执行
# actions=ActionChains(driver) #拿到动作链对象
# actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行
# actions.perform()
#方式二:不同的动作链,每次移动的位移都不同
```
ActionChains(driver).click_and_hold(sourse).perform()
distance=target.location['x']-sourse.location['x']
```
track=0
while track < distance:
ActionChains(driver).move_by_offset(xoffset=2,yoffset=0).perform()
track+=2
ActionChains(driver).release().perform()
time.sleep(10)
```
finally:
driver.close()
在交互动作比较难实现的时候可以自己写 JS(万能方法)
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
try:
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('alert("hello world")') #打印警告
finally:
browser.close()
补充:frame 的切换
#frame相当于一个单独的网页,在父frame里是无法直接查看到子frame的元素的,必须switch_to_frame切到该frame下,才能进一步查找
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
try:
browser=webdriver.Chrome()
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
```
browser.switch_to.frame('iframeResult') #切换到id为iframeResult的frame
```
tag1=browser.find_element_by_id('droppable')
print(tag1)
```
# tag2=browser.find_element_by_id('textareaCode') #报错,在子frame里无法查看到父frame的元素
browser.switch_to.parent_frame() #切回父frame,就可以查找到了
tag2=browser.find_element_by_id('textareaCode')
print(tag2)
```
finally:
browser.close()
其他交互
模拟浏览器的前进后退
#模拟浏览器的前进后退
import time
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.get('https://www.taobao.com')
browser.get('http://www.sina.com.cn/')
browser.back()
time.sleep(10)
browser.forward()
browser.close()
模拟浏览器的前进后退
cookies 操作
#cookies
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'k1':'xxx','k2':'yyy'})
print(browser.get_cookies())
# browser.delete_all_cookies()
选项卡(标签页)管理
#选项卡管理:切换选项卡,有js的方式windows.open,有windows快捷键:ctrl+t等,最通用的就是js的方式
import time
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles) #获取所有的选项卡
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(10)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://www.sina.com.cn')
browser.close()
异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException
try:
browser=webdriver.Chrome()
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframssseResult')
except TimeoutException as e:
print(e)
except NoSuchFrameException as e:
print(e)
finally:
browser.close()
小练习
自动登录 163 邮箱并发送邮件
#注意:网站都策略都是在不断变化的,精髓在于学习流程。下述代码生效与2017-11-7,不能保证永久有效
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser=webdriver.Chrome()
try:
browser.get('http://mail.163.com/')
```
wait=WebDriverWait(browser,5)
frame=wait.until(EC.presence_of_element_located((By.ID,'x-URS-iframe')))
browser.switch_to.frame(frame)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.m-container')))
inp_user=browser.find_element_by_name('email')
inp_pwd=browser.find_element_by_name('password')
button=browser.find_element_by_id('dologin')
inp_user.send_keys('18611453110')
inp_pwd.send_keys('xxxx')
button.click()
#如果遇到验证码,可以把下面一小段打开注释
# import time
# time.sleep(10)
# button = browser.find_element_by_id('dologin')
# button.click()
```
wait.until(EC.presence_of_element_located((By.ID,'dvNavTop')))
write_msg=browser.find_elements_by_css_selector('#dvNavTop li')[1] #获取第二个li标签就是“写信”了
write_msg.click()
```
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tH0')))
recv_man=browser.find_element_by_class_name('nui-editableAddr-ipt')
title=browser.find_element_by_css_selector('.dG0 .nui-ipt-input')
recv_man.send_keys('378533872@qq.com')
title.send_keys('圣旨')
print(title.tag_name)
```
```
frame=wait.until(EC.presence_of_element_located((By.CLASS_NAME,'APP-editor-iframe')))
browser.switch_to.frame(frame)
body=browser.find_element(By.CSS_SELECTOR,'body')
body.send_keys('egon很帅,可以加工资了')
browser.switch_to.parent_frame() #切回他爹
send_button=browser.find_element_by_class_name('nui-toolbar-item')
send_button.click()
#可以睡时间久一点别让浏览器关掉,看看发送成功没有
import time
time.sleep(10000)
```
except Exception as e:
print(e)
finally:
browser.close()
自动登录163邮箱并发送邮件
爬取京东商城商品信息
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
import time
def get_goods(driver):
try:
goods=driver.find_elements_by_class_name('gl-item')
```
for good in goods:
detail_url=good.find_element_by_tag_name('a').get_attribute('href')
p_name=good.find_element_by_css_selector('.p-name em').text.replace('
','')
price=good.find_element_by_css_selector('.p-price i').text
p_commit=good.find_element_by_css_selector('.p-commit a').text
msg = '''
商品 : %s
链接 : %s
价钱 :%s
评论 :%s
''' % (p_name,detail_url,price,p_commit)
print(msg,end='
')
```
```
button=driver.find_element_by_partial_link_text('下一页')
button.click()
time.sleep(1)
get_goods(driver)
except Exception:
pass
```
def spider(url,keyword):
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(3) # 使用隐式等待
try:
input_tag=driver.find_element_by_id('key')
input_tag.send_keys(keyword)
input_tag.send_keys(Keys.ENTER)
get_goods(driver)
finally:
driver.close()
if __name__ == '__main__':
spider('https://www.jd.com/',keyword='iPhone8手机')
其余练习
爬取亚马逊iphone手机的商品信息
爬取天猫python书籍的商品信息
爬取京东小米手机的商品信息