既然已经写过Hello World了,说明我已经熟悉了Python,想想就有些小激动。我打算乘胜追击,搞个大激动。什么是大激动,大激动就是Python给人(代指码农)的第一印象是什么,当然是爬虫。
准备工作
不能盲目开搞,古人有话“知其然知其所以然”,理论还是要学一下的。
什么是爬虫
程序猿角度来讲,人逛网站的行为就是数据交互行为,爬虫替代了人的位置来与网站交互,发出请求获取数据。简单来讲,爬虫就是一个机器人,它来模拟人的行为逛网站。为什么逛网站为啥要爬虫来干:网络上数据消息太多了,如果要查找和分析那么多数据,100个肝也扛不住。普遍来讲,程序比人快这也是常识。
那么还有个问题,爬虫只能用Python写吗?当然不是了。
那为什么要用Python写爬虫?大概这就是潮流。
对比Java和python,两者区别:
1)python的requests库比java的jsoup简单;
2)python代码简洁,美观,上手容易;
3)python的scrapy爬虫库的加持;
4)python对excel的支持性比java好;
5)java没有pip这样的包管理工具。
总之,爬虫简单操作易上手。
为什么python写爬虫有优势?
Python独特的优势是写爬虫的关键。
1)跨平台,对Linux和windows都有不错的支持;
2)科学计算、数值拟合:Numpy、Scipy;
3)可视化:2d:Matplotlib, 3d: Mayavi2;
4)复杂网络:Networkx、scrapy爬虫;
5)交互式终端、网站的快速开发。
写爬虫
可能有用可能没用的理论完了,开搞,开搞。语法这些都还没去熟悉,只能查资料,大致看了一些,Python的语法确实简单。
import requests
# 抓取搜狗的主页,存到当前项目文件目录 url = 'https://www.sogou.com' response = requests.get(url) pageText = response.text with open('./sogou.html', 'w', encoding='utf-8') as fp: fp.write(pageText)
以上代码实现的功能就是爬取搜狗的主页,存入本地。现做分析:
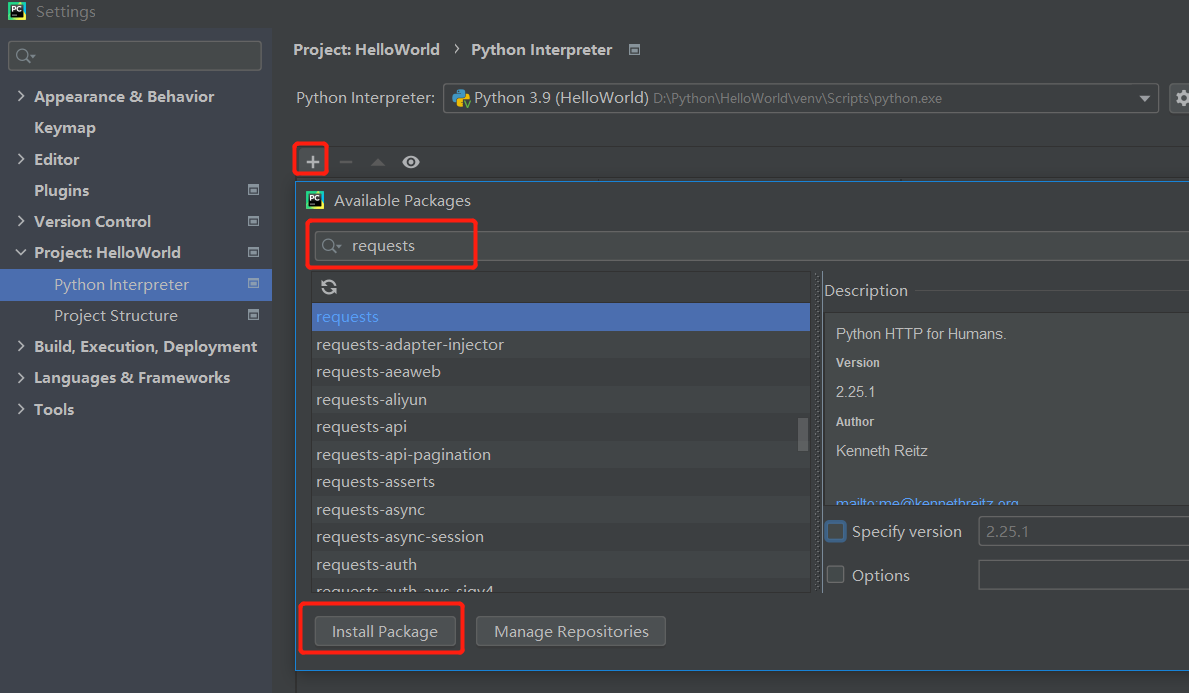
1)import requests导入requests库(网络请求库)。那么这个库从哪里来的?File -> settings -> Projects:HellowWorld -> Python Interpreter -> + -> requests -> Install Pakage,两张图标明
2)使用requests库的网络请求方法get来请求网页。
3)将回复的网页数据存到本地。
为什么要用get请求?数据为什么是用text方法获取的?这就涉及到对网站请求的数据分析了,以下截图是猎豹浏览器请求搜狗网站的网络请求答复的内容:

4)结果(成功)。直接上图:

以上,写一个简单的爬网页的爬虫,完结。
课外班
尝试写完一个简单的网页爬虫后,感觉自己已经会了一点点了,网页会爬了。还不满足,想要再多搞一点?课外补习班了解一下。
众所周知,肯德基有它的主页(废话),今天,我们不爬它主页,我们爬它的深圳门店,好不咯。
整理一下思路,先要找到肯德基门店查询的网站地址(http://www.kfc.com.cn/kfccda/storelist),然后城市选择选深圳,浏览器抓包工具看下它请求数据的形式,然后代码实现,上图:


经查证,“肯德基餐厅信息查询”这个页面,查询门店使用的AJAX模式,用的是POST方式请求的数据,数据反馈的格式是text和编码方式是utf-8。以上的内容貌似多了好些哈,用POST请求数据也不算是弹跳起步了,也就离地高那么一丢丢,稍微深入一点点。放上代码:
import requests # 肯德基全国深圳门店 url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname' headers = { # 伪装成浏览器 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36' } data = { 'cname': '深圳', 'pid': '', 'pageIndex': 1, 'pageSize': 10 } response = requests.post(url=url, data=data, headers=headers) resText = response.text with open('./kfc.txt', 'w', encoding='utf-8') as fp: fp.write(resText) print('获取数据完成')
当前已验证,能取到第1页的数据。结果就不附上了,这代码考去,自己运行一下就知道了。顺带吐槽一下,KFC这么大的企业,网站UI做得真是糟糕,三流企业的样子。
最后说一下感受吧,写了点爬虫代码后,有点心虚,爬虫能这么简单的实现,网络不崩溃才怪了,反爬怕是没这么简单。任重而道远,共勉。
PS:不积跬步,无以至千里。
