查出重复的coupon_no :select count(coupon_no) as t,coupon_no from xy_service_coupon.e_coupon_redeemcode group by coupon_no having t>1
查看表结构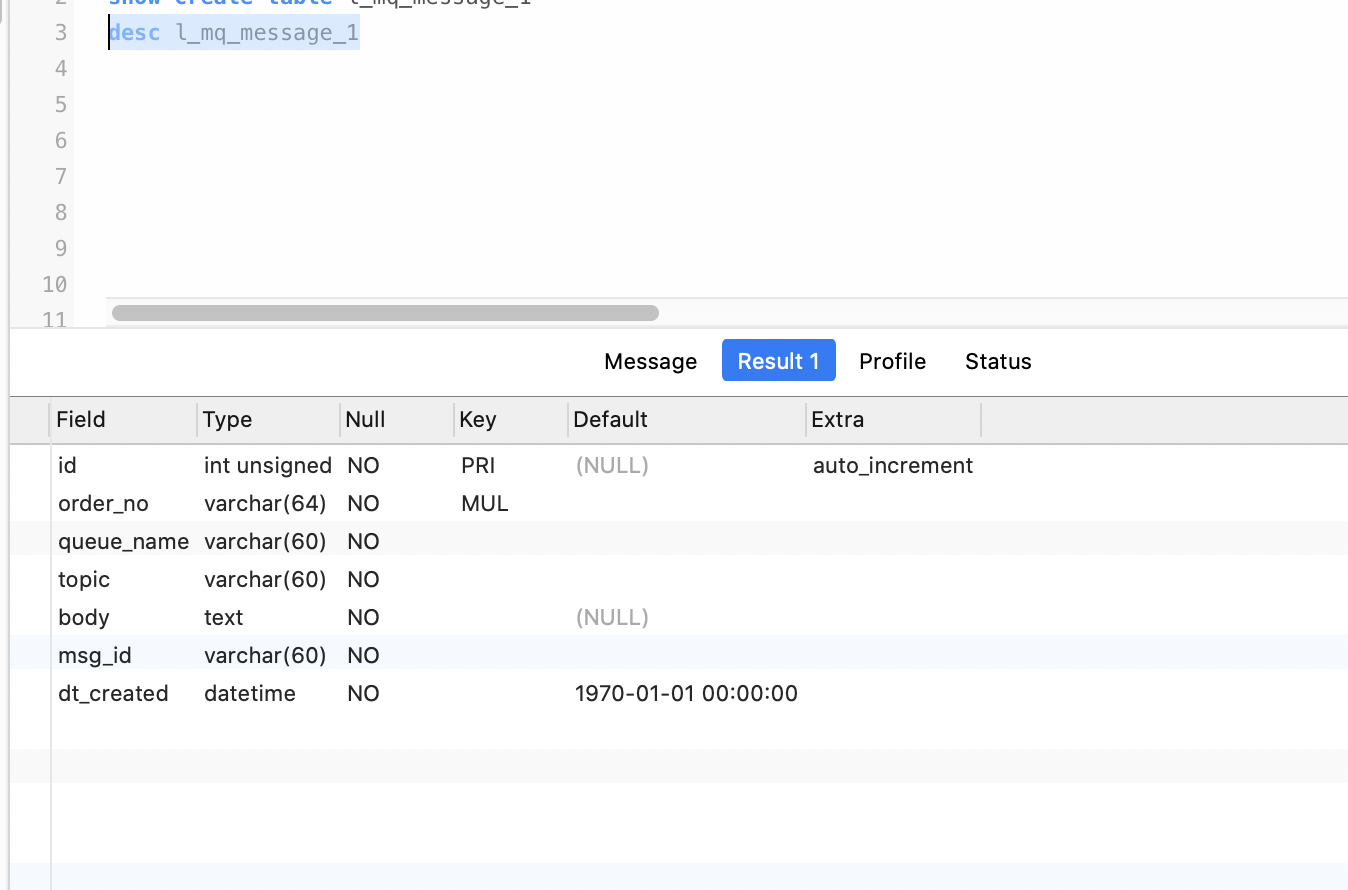

看到有好几种查看表结构的方式,总结一下。
以student(sid,sname,birthday,sex)的查看为例。
【方式一】:desc student;
语法:desc 表名;---------------------用于查看表整体结构
【方式二】:describe student;
语法:describe 表名;---------------------用于查看表整体结构;
【方式三】:show columns from student;
语法:show columns from 表名;--------------------------用于查看表整体结构;
【方式四】:show create table student;
语法:show create table 表名;--------------------------用于查看表整体结构;
【方式五】:show full fields from student;
语法:show full fields from 表名;--------------------------------- 用于查看表整体结构;
【方式六】:show fields from student;
语法:show fields from 表名;----------------------------用于查看表整体结构;
【方式七】:desc student sname;
语法:desc 表名 成员名;--------------------------------用于查询表中的一部分;
【方式八】:show index from student;
语法:show index from 表名;------------------------------------用于查看表局部结构;这种显示不是很直观,也不是可以完全显示所有信息。
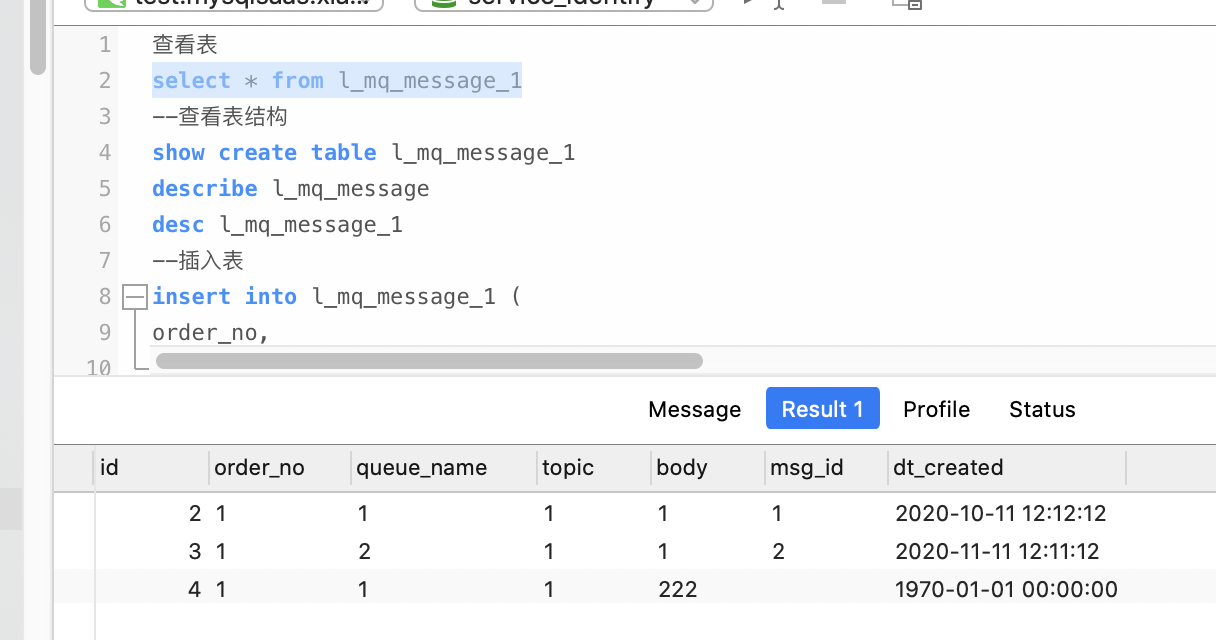
查看表
select * from l_mq_message_1
--查看表结构
show create table l_mq_message_1
describe l_mq_message
desc l_mq_message_1
--插入表
insert into l_mq_message_1 (
order_no,
queue_name,topic,body,msg_id,dt_created)
values ('1','2','1','1','2','2020-11-11 12:11:12')
insert into l_mq_message_1 (order_no,queue_name,topic,body) values ('1','1','1','222')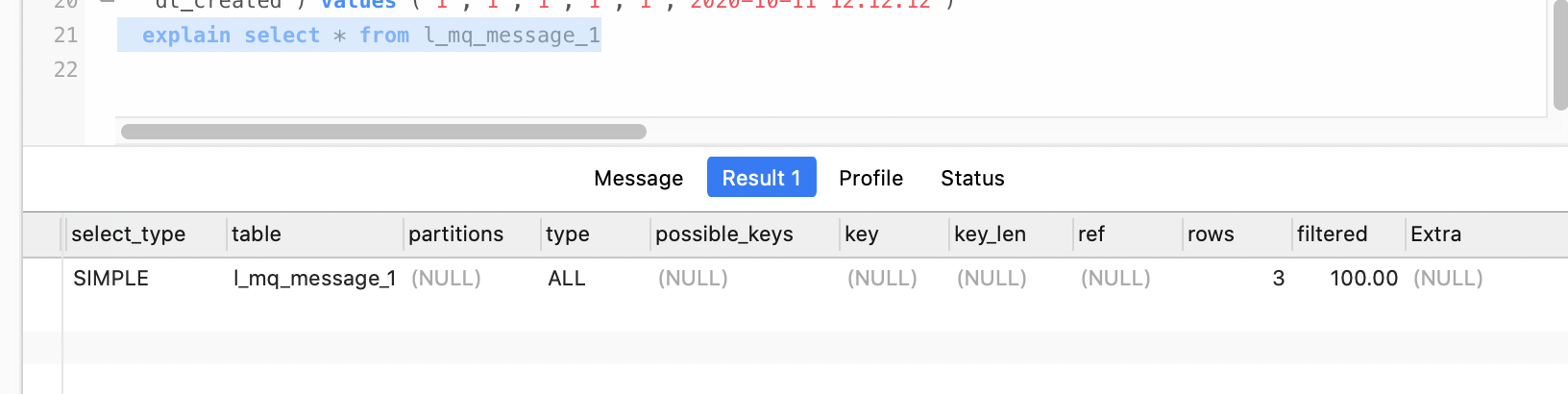
MySQL Explain详解
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看。所以我们深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用。
-- 实际SQL,查找用户名为Jefabc的员工 select * from emp where name = 'Jefabc'; -- 查看SQL是否使用索引,前面加上explain即可 explain select * from emp where name = 'Jefabc';

expain出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra
概要描述:
id:选择标识符
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
下面对这些字段出现的可能进行解释:
一、 id
SELECT识别符。这是SELECT的查询序列号
我的理解是SQL执行的顺序的标识,SQL从大到小的执行
1. id相同时,执行顺序由上至下
2. 如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
3. id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
-- 查看在研发部并且名字以Jef开头的员工,经典查询 explain select e.no, e.name from emp e left join dept d on e.dept_no = d.no where e.name like 'Jef%' and d.name = '研发部';

二、select_type
示查询中每个select子句的类型
(1) SIMPLE(简单SELECT,不使用UNION或子查询等)
(2) PRIMARY(子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY)
(3) UNION(UNION中的第二个或后面的SELECT语句)
(4) DEPENDENT UNION(UNION中的第二个或后面的SELECT语句,取决于外面的查询)
(5) UNION RESULT(UNION的结果,union语句中第二个select开始后面所有select)
(6) SUBQUERY(子查询中的第一个SELECT,结果不依赖于外部查询)
(7) DEPENDENT SUBQUERY(子查询中的第一个SELECT,依赖于外部查询)
(8) DERIVED(派生表的SELECT, FROM子句的子查询)
(9) UNCACHEABLE SUBQUERY(一个子查询的结果不能被缓存,必须重新评估外链接的第一行)
三、table
显示这一步所访问数据库中表名称(显示这一行的数据是关于哪张表的),有时不是真实的表名字,可能是简称,例如上面的e,d,也可能是第几步执行的结果的简称
四、type
对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。
常用的类型有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行
index: Full Index Scan,index与ALL区别为index类型只遍历索引树
range:只检索给定范围的行,使用一个索引来选择行
ref: 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
eq_ref: 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件
const、system: 当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system
NULL: MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
五、possible_keys
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null)
该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询
六、Key
key列显示MySQL实际决定使用的键(索引),必然包含在possible_keys中
如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
七、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
不损失精确性的情况下,长度越短越好
八、ref
列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
九、rows
估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数
十、Extra
该列包含MySQL解决查询的详细信息,有以下几种情况:
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by
Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
-- 测试Extra的filesort explain select * from emp order by name;
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果)。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
No tables used:Query语句中使用from dual 或不含任何from子句
-- explain select now() from dual;
总结:
• EXPLAIN不会告诉你关于触发器、存储过程的信息或用户自定义函数对查询的影响情况
• EXPLAIN不考虑各种Cache
• EXPLAIN不能显示MySQL在执行查询时所作的优化工作
• 部分统计信息是估算的,并非精确值
• EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划。
通过收集统计信息不可能存在结果
explain select * from l_mq_message_1
UPDATE table_reference SET col_name1=expr1 WHERE where_condition
INSERT INTO tbl_name (字段,字段)VALUES(expr, expr)
SELECT select_expr FROM table_references
SQL中distinct的用法
SQL中distinct的用法
- 1.作用于单列
- 2.作用于多列
- 3.COUNT统计
- 4.distinct必须放在开头
- 5.其他
-
今天本来是测试一段代码,然后用到Distinct关键字,查看执行计划之后,突然发现过程中有对表进行sort! 上网搜索和加之验证得出如下结果:
结论:
1.使用distinct 关键字后会对distinct后面用到的关键字进行默认的升序排序.
2.可以使用order by 来改变排序规则.
3.使用distinct后,出现在order by 中的字段必须要写在 SELECT 句中,非充要条件。
在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。关键词 distinct用于返回唯一不同的值。
表A:

表B:

1.作用于单列
select distinct name from A
执行后结果如下:

2.作用于多列
示例2.1
select distinct name, id from A
执行后结果如下:

实际上是根据name和id两个字段来去重的,这种方式Access和SQL Server同时支持。
示例2.2
select distinct xing, ming from B
返回如下结果:

返回的结果为两行,这说明distinct并非是对xing和ming两列“字符串拼接”后再去重的,而是分别作用于了xing和ming列。
3.COUNT统计
select count(distinct name) from A; --表中name去重后的数目, SQL Server支持,而Access不支持
count是不能统计多个字段的,下面的SQL在SQL Server和Access中都无法运行。
select count(distinct name, id) from A;
若想使用,请使用嵌套查询,如下:
select count(*) from (select distinct xing, name from B) AS M;
4.distinct必须放在开头
select id, distinct name from A; --会提示错误,因为distinct必须放在开头
5.其他
distinct语句中select显示的字段只能是distinct指定的字段,其他字段是不可能出现的。例如,假如表A有“备注”列,如果想获取distinc name,以及对应的“备注”字段,想直接通过distinct是不可能实现的。但可以通过其他方法实现关于SQL Server将一列的多行内容拼接成一行的问题讨论
select a.*,b.* ,c.* from e_inquiry_sub a left join e_user_inquiry b on a.id = b.inquiry_sub_id
left join e_user_inquiry_offer c on a.id = c.inquiry_sub_id
where a.inquiry_no='X2021041315584643446';
left join
2.哪种联结呢?
涉及到多表查询,在之前的课程《从零学会sql:多表查询》里讲过需要用到联结。
多表的联结又分为以下几种类型:
1)左联结(left join),联结结果保留左表的全部数据
2)右联结(right join),联结结果保留右表的全部数据
3)内联结(inner join),取两表的公共数据
作者:houzidata
链接:https://leetcode-cn.com/problems/combine-two-tables/solution/tu-jie-sqlmian-shi-ti-duo-biao-ru-he-cha-xun-by-ho/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
sql学习网址:https://www.w3school.com.cn/sql/sql_join_left.asp
基本用法 https://blog.csdn.net/wheredata/article/details/87191983
wheredata 2019-02-13 17:32:40 37732 收藏 70
分类专栏: sql 文章标签: left join
版权
废话不多说,来看例子
一、建表,导入测试数据
create table temp1
(
aid VARCHAR2(5) not null,
car VARCHAR2(10) not null
);
create table temp2
(
bid VARCHAR2(5) not null,
username VARCHAR2(10) not null
);
create table temp3
(
cid VARCHAR2(5) not null,
dogname VARCHAR2(10) not null
);
insert into temp1(aid,car) values('001','benz');
insert into temp1(aid,car) values('001','BMW');
insert into temp1(aid,car) values('001','ford');
insert into temp1(aid,car) values('001','jeep');
insert into temp1(aid,car) values('002','jeep');
insert into temp1(aid,car) values('003','hongqi');
insert into temp2(bid,username) values('001','mayun');
insert into temp3(cid,dogname) values('001','lily');
insert into temp3(cid,dogname) values('001','lucy');
insert into temp3(cid,dogname) values('002','xiaohua');
查一下数据长什么样:
select * from temp1;
select * from temp2;
select * from temp3;
temp1 temp2 temp3
二、左连接测试
--1.左连接,把左边的全部查出来,右边有的则匹配,没有则为null
select * from temp1 t1 left join temp2 t2 on t1.aid=t2.bid ;
select * from temp2 t2 left join temp1 t1 on t2.bid=t1.aid ;
--2.若是三张表,通过两个left join来连接,则把前面两张表先left join之后当作一张表,然后再与第三张表left join,同理,多张表的left join 以此类推
select * from temp1 t1 left join temp2 t2 on t1.aid=t2.bid left join temp3 t3 on t2.bid=t3.cid ;
select * from temp3 t3 left join temp1 t1 on t3.cid=t1.aid left join temp2 t2 on t3.cid=t2.bid;
--3.right join 与left join相对应,会将右边的数据全部查出来(例子略)
-- 一年多以后回过头来,发现第三张表的数据没有造好,也不想更正了,将就看吧,见谅
————————————————
版权声明:本文为CSDN博主「wheredata」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wheredata/article/details/87191983
distinct 排序_SQL | 汇总分析、排序、运行顺序
https://blog.csdn.net/weixin_39531688/article/details/110637221?utm_term=distinct%E4%BC%9A%E6%8E%92%E5%BA%8F&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~sobaiduweb~default-8-110637221&spm=3001.4430
1、汇总分析
COUNT 计数(某列有多少行)
SUM 列数据求和 AVG 列数据求平均
MAX 列数据最大值 MIN 列数据最小值
函数的功能:数据输入、自身的特性功能、数据输出
练习:
-
-------查询学生编号为‘0002’的总成绩
-
SELECT 学号, SUM(成绩) 总成绩
-
FROM course
-
WHERE 学号='0002';
结果:

练习:
-
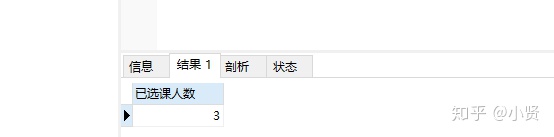
------查询选了课程的学生人数
-
SELECT COUNT(DISTINCT 学号) 已选课人数
-
FROM course;
结果:
2、分组
GROUP BY <字段>;分组子句
练习1:
-
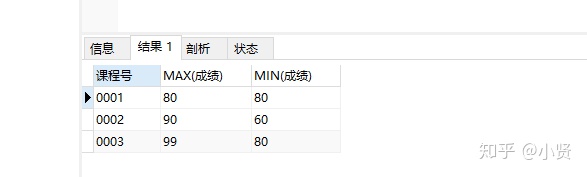
-----各科成绩最高和最低分
-
SELECT 课程号,MAX(成绩),MIN(成绩)
-
FROM course
-
GROUP BY 课程号;
结果:
练习2:
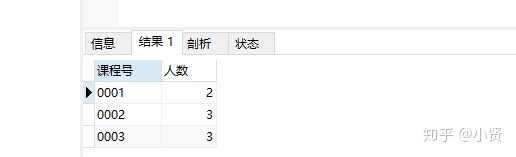
-
-----每门课程被选修的学生人数
-
SELECT 课程号, COUNT(学号) 人数
-
FROM course
-
GROUP BY 课程号;
结果:
练习3:
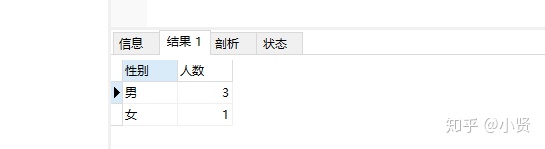
-
-----男生、女生人数
-
SELECT 性别,COUNT(学号) 人数
-
FROM student
-
GROUP BY 性别;
结果:
3、对分组结果指定条件
GROUP BY <字段> HAVING 汇总后条件;分组后筛选子句
练习1:
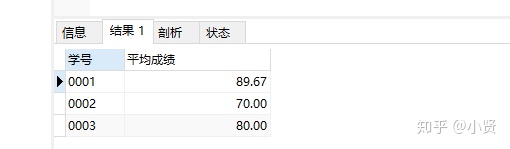
-
-----平均成绩大于60分学生的学号和平均成绩
-
SELECT 学号,ROUND(AVG(成绩),2) 平均成绩
-
FROM course
-
GROUP BY 学号 HAVING AVG(成绩)>'60';
结果:
练习2:
-
-----至少选修两门课的学生学号
-
SELECT 学号
-
FROM course
-
GROUP BY 学号 HAVING COUNT(课程号)>='2';
结果:
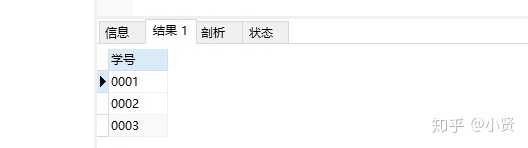
练习3:
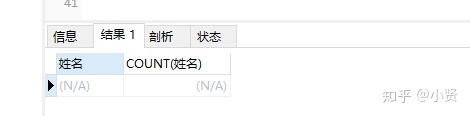
-
------同名同性学生名单并统计同名人数
-
SELECT 姓名,COUNT(姓名)
-
FROM student
-
GROUP BY 姓名 HAVING COUNT(姓名)='2' AND COUNT(性别)='1';
结果:
4、用SQL解决业务问题
翻译成自己能够看懂的句子——写出分析思路——写出对应的SQL子句
练习:
-
-----每门课程的平均成绩
-
SELECT 课程号,ROUND(AVG(成绩),'2') 平均成绩
-
FROM course
-
GROUP BY 课程号 HAVING AVG(成绩)>='80';
结果:

5、对查询结果排序
ORDER BY <字段>;-------升序
ORDER BY <字段> DESC;-----降序
可加多个列名,按照列名前后顺序依次排序。
空值排序在最前。
LIMIT 数字;从查询结果中取出指定行;
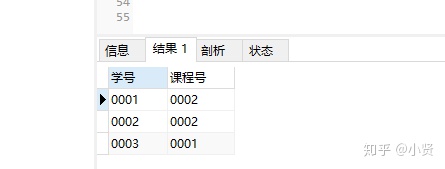
练习:
-
-------查询不及格的课程并按课程号从大到小排列
-
SELECT 学号,课程号
-
FROM course
-
WHERE 成绩<'60'
-
ORDER BY 课程号 DESC;
结果:
练习:
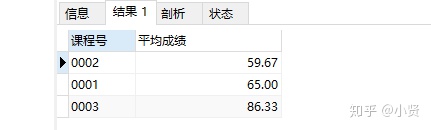
-
-------查询平均成绩,结果按平均成绩升序,相同则按课程号降序
-
SELECT 课程号,ROUND(AVG(成绩),'2') 平均成绩
-
FROM course
-
GROUP BY 课程号
-
ORDER BY AVG(成绩), 课程号 DESC;
结果:
6、SQL运行顺序&看懂报错信息
红蓝框中的运行顺序按书写顺序进行
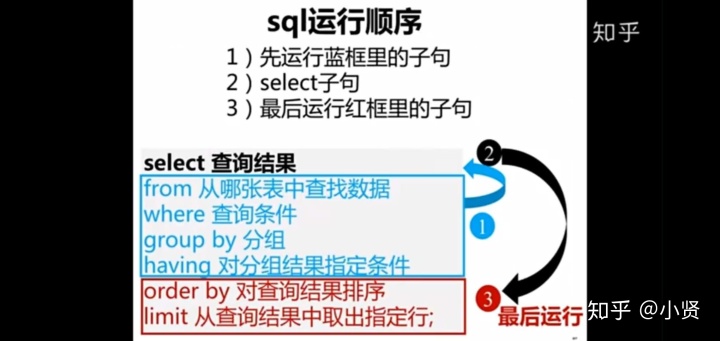
常见错误:
- 在GROUP BY中使用SELECT的别名
- 在WHERE中使用聚合函数
- 字符串类型的数字(字符串与数值类型的排列顺序不同)
-

sql中limit的用法
 涵一 2018-09-20 12:05:25
涵一 2018-09-20 12:05:25 99662
99662  收藏 31
收藏 31原创文章,转载请标明出处:https://blog.csdn.net/yihanzhi/article/details/82784770
limit子句用于限制查询结果返回的数量。
用法:【select * from tableName limit i,n 】
参数:
- tableName : 为数据表;
- i : 为查询结果的索引值(默认从0开始);
- n : 为查询结果返回的数量
示例:
1)查询student的数据:select * from student- 1
2)查询第一条数据
select * from student limit 1- 1
执行结果如下图所示:
3)查询第二条数据
select * from student limit 1,1- 1
执行结果如下图所示:
-



【MySQL】【8】IFNULL()和IF()
正文:
1,IFNULL(expr1, expr2):expr1不为null返回expr1,为null返回expr2
2,IF(expr1, expr2, expr3):如果expr1是TRUE(expr1<>0且expr1<>NULL),那么返回expr2,否则返回expr3
参考博客:
Mysql中类似于nvl()函数的ifnull()函数 - 花语苑 - 博客园
https://www.cnblogs.com/zrui-xyu/p/4819715.html