8.初始化管理器BlockManager
无论是Spark的初始化阶段还是任务提交、执行阶段,始终离不开存储体系。Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息、计算结果等数据存入内存,这极大地提升了系统的执行效率。正是因为这一关键决策,才让Spark能在大数据应用中表现出优秀的计算能力。BlockManager是在sparkEnv中被创建的,代码如下:
8.1 存储体系概述
8.1.1 块管理器BlockManager的实现
块管理器BlockManager是Spark存储体系中的核心组件。Driver Application和Executor都会创建BlockManager,BlockManager是在SparkEnv的创建过程中创建的,BlockManager的实现代码如下:

上面代码中声明的BlockManager主要由以下部分组成:
- shuffle客户端ShuffleClient;
- BlockManagerMaster(对存在于所有Executor上的BlockManager统一管理);
- 磁盘块管理器DiskBlockManager;
- 内存存储MemoryStor;
- 磁盘存储DiskStore;
- 非广播Block清理器metadataCleaner和广播Block清理器broadcastCleaner;
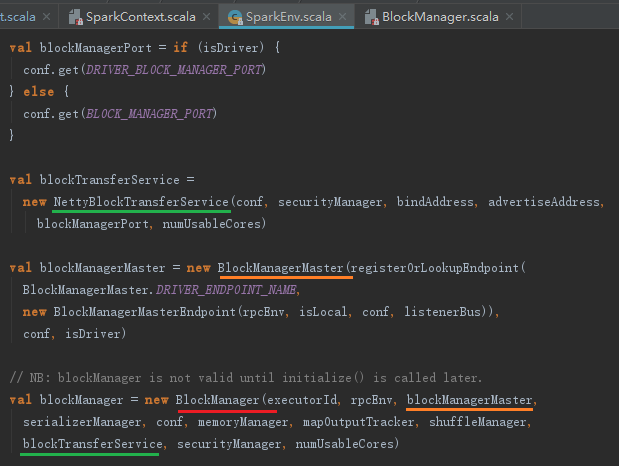
BlockManager要生效,必须要初始化。BlockManager初始化步骤如下:
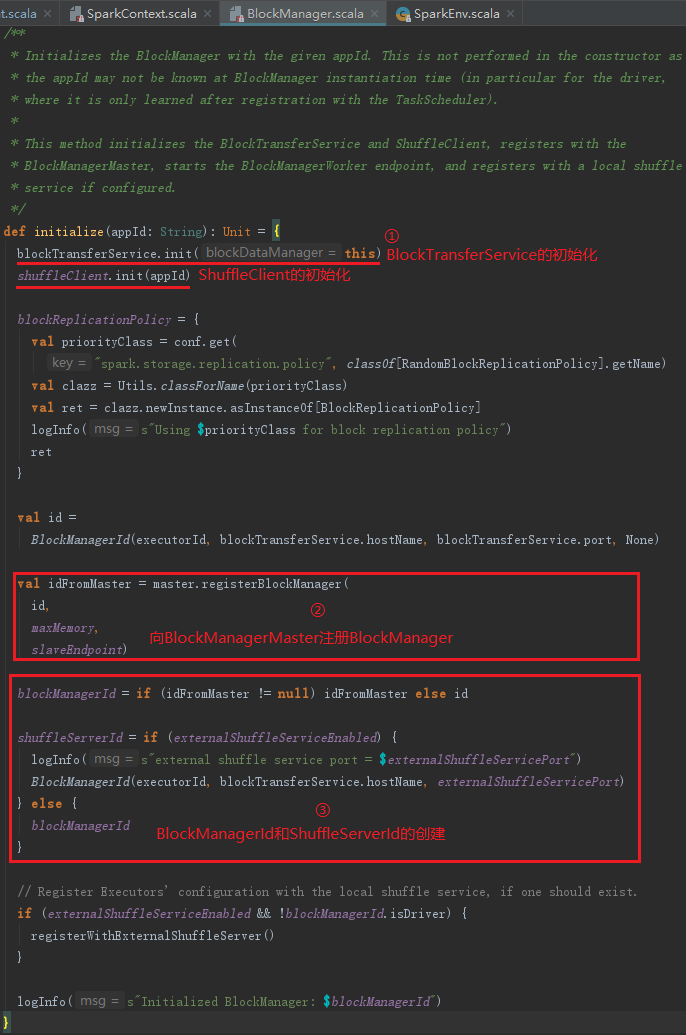
1) BlockTransferService的初始化和ShuffleClient的初始化。ShuffleClient默认是BlockTransferService,当有外部的ShuffleService时,调用外部ShuffleService的初始化方法。
2) 向BlockManagerMaster注册BlockManagerId。
3) BlockManagerId和ShuffleServerId的创建。当有外部的ShuffleService时,创建新的BlockManagerId,,否则ShuffleServerId默认使用当前BlockManager的BlockManagerId。
8.1.2 Spark存储体系架构
Spark存储体系的架构
略
- 记号①表示Executor的BlockManager与Driver的BlockManager进行消息通信,例如,注册BlockManager、更新Block信息、获取Block所在的BlockManager、删除Executor等;
- 记号②表示对BlockManager的读操作(例如get、doGetLocal以及BlockManager内部进行的MemoryStore、DiskStore、getValues等操作)和写操作(例如doPut、putSingle、putBytes以及BlockManager内部进行的MemoryStore、DiskStore、putArray、putIterator等操作);
- 记号③表示当MemoryStore的内存不足时,写入DiskStore,而DiskStore实际依赖于DiskBlockManager;
- 记号④表示通过访问远端节点的Executor的BlockManager中的TransportServer提供的RPC服务下载或者上传Block;
- 记号⑤表示远端节点的Executor的BlockManager访问本地Executor的BlockManager中的TransportServer提供的RPC服务下载或者上传Block;
- 记号⑥
Spark目前支持HDFS、Amazon S3两种主流分布式存储系统,还使用也诞生于UCBerkeley的AMP实验室的Tachyon这种高效的分布式文件系统作为缓存。
Spark定义了抽象类BlockStore,用于制定所有存储类型的规范。目前BlockStore的具体实现包括MemoryStore、DiskStore和TachyonStore。BlockStore的继承体系如图:
8.2 shuffle服务与客户端
为什么需要把由Netty实现的网络服务组件也放到存储体系里面?这是由于Spark是分布式部署的,每个Task最终都运行在不同的机器节点上。map任务的输出结果直接存储到map任务所在机器的存储体系中,reduce任务极有可能不在同一机器上运行,所以需要远程下载map任务的中间输出。因此将ShuffleClient放到存储体系是最合适的。
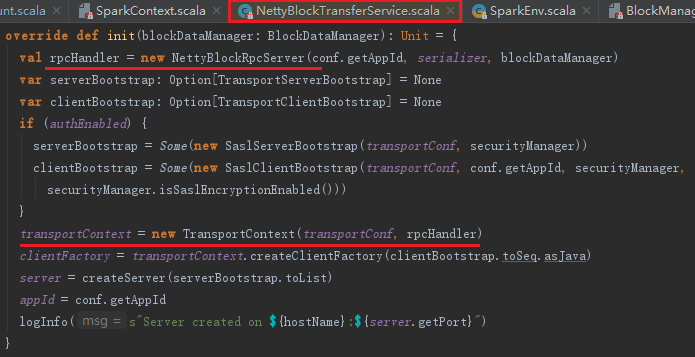
ShuffleClient并不像它的名字一样,是shuffle的客户端,它不光是将shuffle文件上传到其他Executor或者下载到本地的客户端,也提供了可以被其他Executor访问的shuffle服务。Spark与Hadoop一样,都采用Netty作为shuffle server。从BlockManager初始化代码中可知,当有外部的ShuffleClient时,新建ExternalShuffleClient,否则默认为BlockTransferService。BlockTransferService只有在其init方法被调用,即被初始化后才提供服务。以默认的NettyBlockTransferService的init方法为例。NettyBlockTransferService的初始化步骤如下:
1) 创建RpcServer;
2) 构造TransportContext;
3) 创建RPC客户端工厂TransportClientFactory;
4) 创建Netty服务器TransportServer,可以修改属性spark.blockManager.port(默认为0,表示随机选择)改变TransportServer的端口。
NettyBlockTransferService的初始化代码如下:
接下来我们逐步讲解Block的RPC,构造TransportContext,创建RPC客户端工厂TransportClientFactory,创建Netty服务器TransportServer的实现。此外还会介绍reduce任务是如何拉取map任务中间结果的(即shuffle过程的数据传输)。
8.2.1 Block的RPC服务
当map任务与reduce任务处于不同节点时,reduce任务需要从远端节点下载map任务的中间输出,因此NettyBlockRpcServer提供打开,即下载Block文件的功能;一些情况下,为了容错,需要将Block的数据备份到其他节点上,所以NettyBlockRpcServer还提供了上传Block文件的RPC服务,NettyBlockRpcServer的实现代码如下:

8.2.2 构造传输上下文TransportContext
TransportContext用于维护传输上下文,它的构造器如下。

TransportContext既可以创建Netty服务,也可以创建Netty访问客户端。TransportContext的组成如下:
- TransportConf:主要控制Netty框架提供的shuffle的I/O交互的客户端和服务端线程数量;
- RpcHandler:负责shuffle的I/O服务端在接收到客户端的RPC请求后,提供打开Block或者上传Block的RPC处理,此处即为NettyBlockRpcServer;
- decoder:在shuffle的I/O服务端对客户端传来的ByteBuf进行解析,防止丢包和解析错误;
- encoder:在shuffle的I/O客户端对消息内容进行编码,防止服务端丢包和解析错误。
8.2.3 RPC客户端工厂TransportClientFactory
TransportClientFactory是创建Netty客户端TransportClient的工厂类,TransportClient用于向Netty服务端发送RPC请求。TransportContext的createClientFactory方法用于创建TransportClientFactory,实现如下:


从上述代码清单可以看到,TransportClientFactory由以下部分组成:
- clientBootstraps:用于缓存客户端列表;
- connectionPool:用于缓存客户端连接;
- numConnectionsPerPeer:节点之间取数据的连接数,可以使用属性spark.shuffle.io.numConnectionsPerPeer来配置,默认为1;
- socketChannelClass:客户端channel被创建时使用的类,可以使用属性spark.shuffle.io.mode来配置,默认为NioSocketChannel;
- workerGroup:根据Netty的规范,客户端只有work组,所以此处创建workerGroup,实际是NioEventLoopGroup;
- pooledAllocator:汇集ByteBuf但对本地线程缓存禁用的分配器。
TransportClientFactory里大量使用了NettyUtils。
8.2.4 Netty服务器TransportServer
TransportServer提供了Netty实现的服务器端,用于提供RPC服务(比如上传、下载等)。创建TransportServer的代码如下:

TransportServer的构造器如下:

上面代码中的init方法用于对TransportServer初始化,通过使用Netty框架的EventLoopGroup、ServerBootstrap等API创建shuffle的I/O交互的服务端,init的主要代码见代码清单:

ServerBootstrap的childHandler方法调用了TransportContext的initializePipeline。initializePipeline中创建了TransportChannelHandler,并将它绑定到SocketChannel的pipeline的handler中,见代码如下:

8.2.5 获取远程shuffle文件
NettyBlockTransferService的fetchBlocks方法用于获取远程shuffle文件,实际是利用NettyBlockTransferService中创建的Netty服务,见代码如下:

8.2.6 上传shuffle文件
NettyBlockTransferService的uploadBlock方法用于上传shuffle文件到远程Executor,实际上也是利用NettyBlockTransferService中创建的Netty服务,见代码如下。NettyBlockTransferService上传Block的步骤如下:
1) 创建Netty服务的客户端,客户端连接的hostname和port正是我们随机选择的BlockManager的hostname和port。
2) 将Block的存储级别StorageLevel序列化。
3) 将Block的ByteBuffer转化为数组,便于序列化。
4) 将appId、execId、blockId、序列化的StorageLevel、转换为数组的Block封装为UploadBlock,并将UploadBlock序列化为字节数组。
5) 最终调用Netty客户端的sendRpc方法将字节数组上传,回调函数RpcResponseCallback根据RPC的结果更改上传状态。

8.3 BlockManagerMaster对BlockManager的管理
Driver上的BlockManagerMaster对存在于Executor上的BlockManager统一管理,比如Executor需要向Driver发送注册BlockManager、更新Executor上Block的最新信息、询问所需要Block目前所在的位置以及当Executor运行结束需要将此Executor移除等。但是Driver与Executor却位于不同机器上,该怎么实现呢?Driver上的BlockManagerMaster会持有BlockManagerMasterEndpoint,所有Executor也会从RpcEnv中获取BlockManagerMasterEndpoint的引用,所有Executor与Driver关于BlockManager的交互都依赖于它。
8.3.1 BlockManagerMasterEndpoint
BlockManagerMasterEndpoint只存在于Driver上。Executor从RpcEnv获取BlockManagerMasterEndpoint的引用,然后给BlockManagerMasterEndpoint发送消息,实现和Driver交互。BlockManagerMasterEndpoint的实现见代码如下:

上面代码展示了BlockManagerMasterEndpoint维护的很多缓存数据结构:
- blockManagerInfo:缓存所有的BlockManagerId及其BlockManager的信息;
- blockManagerIdByExecutor:缓存executorId与其拥有的BlockManagerId之间的映射关系;
- blockLocations:缓存Block与BlockManagerId的映射关系。
在上述代码中,receiveAndReply作为匹配BlockManagerMasterEndpoint接收到消息的偏函数;属性spark.blockManagerSlaveTimeoutMs和spark.executor.heartbeatInterval共同决定Slave节点,即BlockManager的超时时间;属性spark.storage.blockManagerTimeoutIntervalMs指定检查BlockManager超时的时间间隔。
8.3.2 询问Driver并获取回复方法
在Executor的BlockManager中,所有与Driver上BlockManagerMaster的交互方法最终都调用askWithRetry,可见它是一个最基础的方法,封装为updateId方法,它的代码如下:

此外,tell方法作为askWithRetry的代理也经常被调用,代码如下:

8.3.3 向BlockManagerMaster注册BlockManagerId
Executor或者Driver自身的BlockManager在初始化时,需要向Driver的BlockManagerMaster注册BlockManager信息,代码如下:

从上面代码看到,消息内容包括BlockManagerId、最大内存、BlockManagerSlaveEndpoint。消息体带有BlockManagerSlaveEndpoint是为了便于接受BlockManagerMasterEndpoint回复的消息。这些消息被封装为RegisterBlockManager,并调用刚刚8.3.2节介绍的updateId方法。根据之前的分析,RegisterBlockManager消息会被BlockManagerMasterEndpoint匹配并执行register方法注册BlockManager,并在register方法执行结束后向发送者BlockManager,并在register方法执行结束后向发送者BlockManagerslaveEndpoint发送一个简单的消息true。注册BlockManager的实现代码如下:

register方法确保blockManagerInfo持有消息中的blockManagerId及对应信息,并且确保每个Executor最多只能有一个blockManagerId,旧的blockManagerId会被移除。最后向listenerBus中post(推送)一个SparkListenerBlockManagerAdded事件。
8.4 磁盘块管理器DiskBlockManager
8.4.1 DiskBlockManager的构造过程
BlockManager初始化时会创建DiskBlockManager,DiskBlockManager的构造步骤如下:
1) 调用createLocalDirs方法创建本地文件目录,然后创建二维数组subDirs,用来缓存一级目录localDirs及二级目录,其中二级目录的数量根据配置spark.diskStore.subDircectories获取,默认为64.以笔者本地为例,创建的目录为:C:Users{username}AppDataLocalTempspark-012f256-5040-b0ch-24434342391df0sdspark-34663dsf,其中spark-012f256-5040-b0ch-24434342391df0sd是一级目录,spark-34663dsf是二级目录,见代码如下:


注意:createLocalDirs方法具体创建目录的过程实际调用了Utils的createDirectory方法。
2) 添加运行时环境结束时的钩子,用于在进程关闭时创建线程,通过调用DiskBlockManager的stop方法,清除一些临时目录,见代码如下:

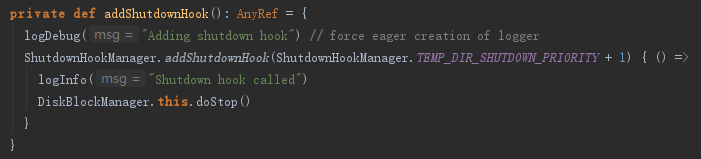
DiskBlockManager为什么要创建二级目录结构呢?这是因为二级目录用于对文件进行散列存储,散列存储可以使所有文件都随机存放,写入或删除文件更方便,存取速度快,节省空间。
8.4.2 获取磁盘文件方法getFile
很多代码中都使用DiskBlockManager的getFile方法,获取磁盘上的文件,通过对getFile的分析,能够掌握spark磁盘散列文件存储的实现机制。getFile方法的实现见代码如下,其处理步骤为:
1) 根据文件名计算哈希值。
2) 根据哈希值与本地文件一级目录的总数求余数,记为dirId。
3) 根据哈希值与本地文件一级目录的总数求商数,此商数与二级目录的数目再求余数,记为subDirId。
4) 如果dirId/subDirId目录存在,则获取dirId/subDirId目录下的文件,否则新建dirId/subDirId目录。

8.4.3 创建临时Block方法createTempShuffleBlock
当ShuffleMapTask运行结束需要把中间结果临时保存,此时就调用createTempShuffleBlock方法创建临时的Block,并返回TempShuffleBlockId与其文件的对偶,见代码如下,TempShuffleBlockId的生成规则:“temp_shuffle_”后加上UUID字符串。

8.5 磁盘存储DiskStore
当MemoryStore没有足够空间时,就会使用DiskStore将块存入磁盘。DiskStore继承自BlockStore,并实现了getBytes、putBytes、putArray、putIterator等方法。
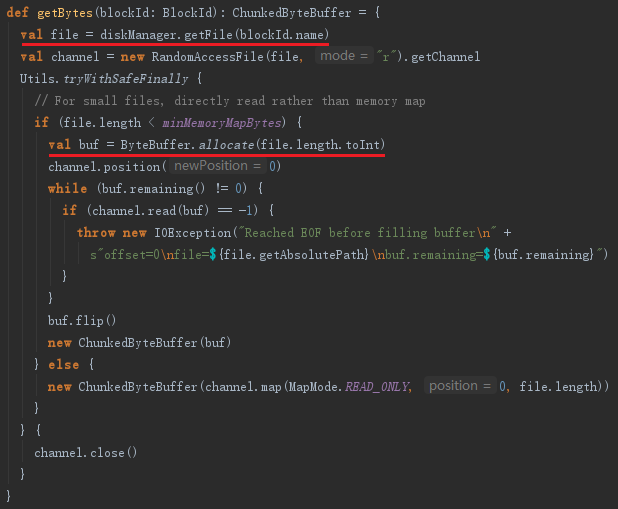
8.5.1 NIO读取方法getBytes
DiskStore的getBytes方法通过DiskBlockManager的getFile方法获取文件。然后使用NIO将文件读取到ByteBuffer,见代码如下:
8.5.2 NIO写入方法putBytes
putBytes方法的作用是通过DiskBlockManager的getFile方法获取文件。然后使用NIO的Channel将ByteBuffer写入文件,见代码如下:

8.6 内存存储MemoryStore
MemoryStore负责将没有序列化的Java对象数组或者序列化的ByteBuffer存储到内存中。我们先来看看MemoryStore的数据结构,见代码如下:

MemoryStore的内存模型图
从图中看出,整个MemoryStore的存储分为两块:一块是被很多MemoryEntry占据的内存currentMemory,这些MemoryEntry实际是通过entries(即LinkedHashMap[BlockId, MemoryEntry])持有的;另一块是unrollMemoryMap通过占座方式占用的内存currentUnrollMemory。所谓占座,好比教室里空着的座位,有人在座位上放上书本,以防在需要坐的时候,却发现没有位置了。比起人的行为,unrollMemoryMap占座的出发点是“高尚”的,这样可以防止在向内存真正写入数据时,内存不足发生溢出。每个线程实际占用的空间,其实是vector(即SizeTrackingVector)占用的大小,但是unrollMemoryMap的大小会稍大些。
结合代码和图解释一些概念:
- maxUnrollMemory:当前Driver或者Executor最多展开的Block所占用的内存,可以修改属性spark.storage.unrollFraction改变大小;
- maxMemory:当前Driver或者Executor的最大内存;
- currentMemory:当前Driver或者Executor已经使用的内存;
- freeMemory:当前Driver或者Executor未使用的内存,freeMemory = maxMemory - currentMemory;
- currentUnrollMemory:unrollMemoryMap中所有展开的Block的内存之和,即当前Driver或者Executor中所有线程展开的Block的内存之和;
- unrollMemoryMap:当前Driver或者Executor中所有线程展开的Block都存入此Map中,key为线程Id,value为线程展开的所有块的内存的大小总和。
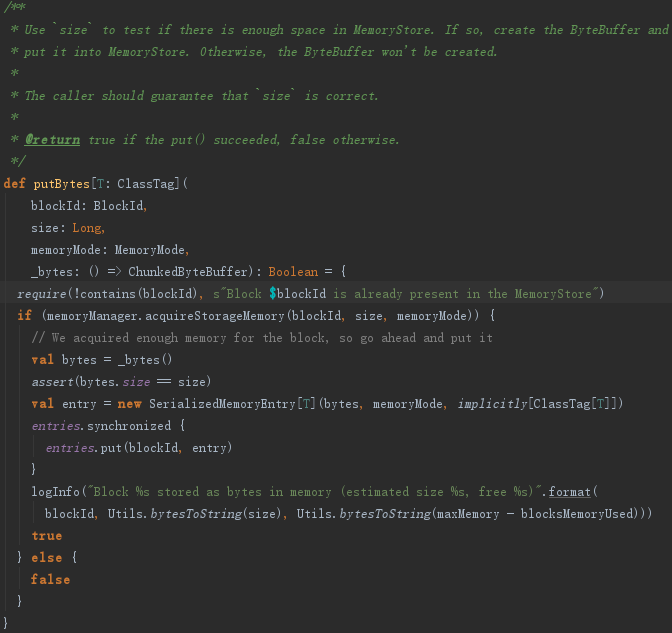
8.6.1 数据存储方法putBytes
如果Block可以被反序列化(即存储级别StorageLevel.Deserialized等于true),那么先对Block序列化,然后调用putIterator;否则调用tryToput方法,见代码如下:
8.6.2 Iterator写入方法putIteratorAsBytes详解
MemoryStore的putIteratorAsBytes方法的实现见如下。
8.6.3 安全展开方法unrollSafely
8.6.4 确认空闲内存方法ensureFreeSpace
8.6.5 内存写入方法putArray
8.6.6 尝试写入内存方法tryToPut
8.6.7 获取内存数据方法getBytes
getBytes方法用于从entries中获取MemoryEntry,见代码如下:

8.6.8 获取数据方法getValues
getValues也用于从内存中获取数据,即从entries中获取MemoryEntry,并将value返回

8.7 块管理器BlockManager
已经介绍了BlockManager中的主要组件,现在来看看BlockManager自身的实现。
8.7.1 移出内存方法dropFromMemory
当内存不足时,可能需要腾出部分内存空间。dropFromMemory实现了这个功能,它的处理步骤如下:
1) 从blockInfo:HashMap[BlockId, BlockInfo]中检查是否存在要迁移的blockId。如果存在,从BlockInfo中获取Block的StorageLevel。
2) 如果StorageLevel允许存入硬盘,并且DiskStore中不存在此文件,那么调用DiskStore的putBytes方法,将此Block存入硬盘。
3) 从MemoryStore中清除此BlockId对应的Block。
4) 使用getCurrentBlockStatus方法获取Block的最新状态。如果此Block的tellMaster属性为true,则调用reportBlockStatus方法给BlockManagerMasterEndpoint报告状态。
5) 更新TaskMetrics中Block的状态。

8.7.2 状态报告方法reportBlockStatus
reportBlockStatus用于向BlockManagerMasterEndpoint报告Block的状态并且重新注册BlockManager。reportBlockStatus的实现见代码,它的处理步骤如下:
1) 调用tryToReportBlockStatus方法,tryToReportBlockStatus调用了BlockManagerMaster的updateBlockInfo方法向BlockManagerMasterEndpoint发送UpdateBlockInfo消息更新Block占用的内存大小、磁盘大小、存储级别等信息。
2) 如果BlockManager还没有向BlockManagerMasterEndpoint注册,则调用asyncReregister方法,asyncReregister调用了reregister,最后reregister实际调用了BlockManagerMaster的registerBlockManager方法和reportAllBlocks方法,reportAllBlocks方法实际也是调用了tryToReportBlockStatus。




BlockManagerMaster的updateBlockInfo,代码如下:
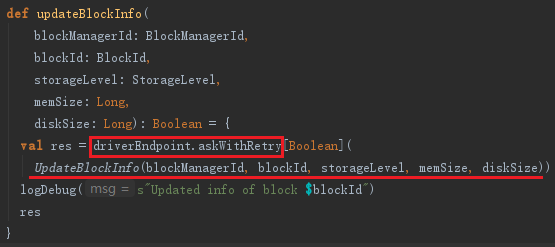
从上面updateBlockInfo方法的实现中发现它也调用了我们熟悉的askDriverWithReply方法,只不过消息是UpdateBlockInfo。BlockManagerMasterEndpoint接收后会调用updateBlockInfo方法更新blockManagerInfo及blockLocations等信息。
8.7.3 单对象块写入方法putSingle
putSingle方法用于将由一个对象构成的Block写入存储系统。putSingle经过调用,实际调用了doPut方法,见代码如下:



8.7.4 序列化字节块写入方法putBytes
putBytes方法用于将序列化字节组成的Block写入存储系统,putBytes实际也调用了doPut方法,见代码如下:

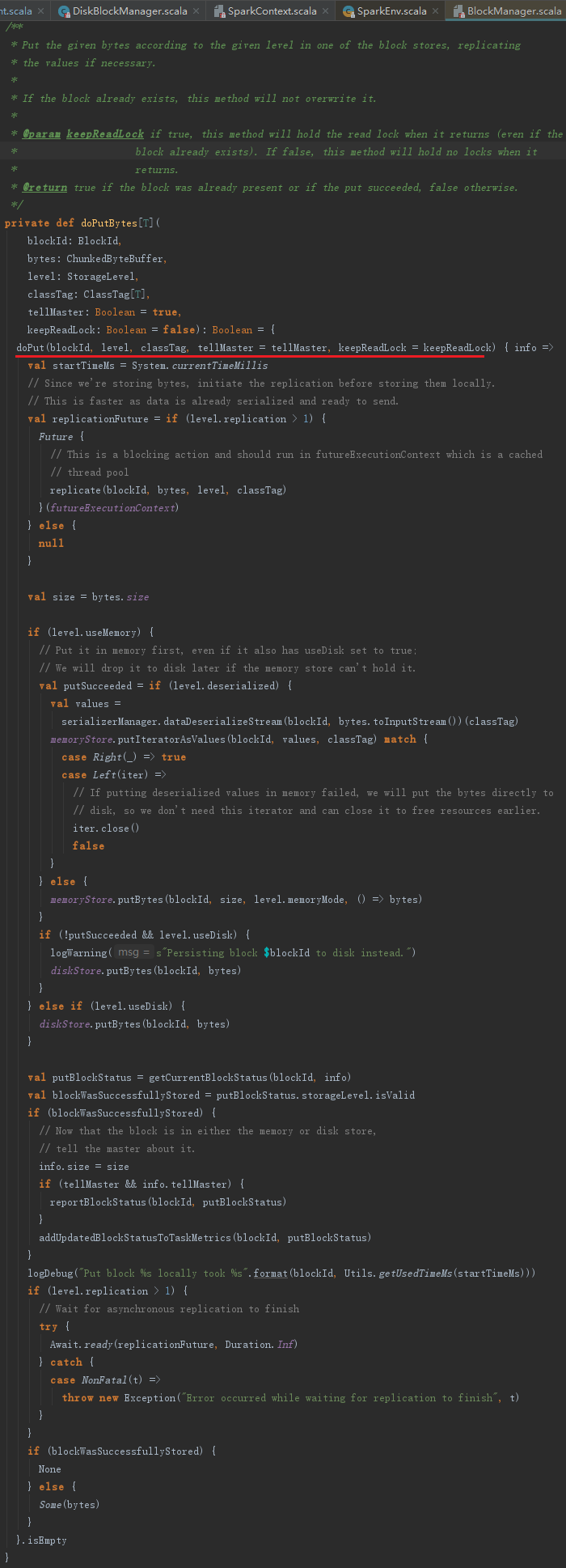
8.7.5 数据写入方法doPut
putSingle、putBytes等方法真正的数据写入实际由doPut实现,doPut的处理流程如图:
略
doPut的处理步骤如下:
1) 获取putBlockInfo。如果blockInfo中已经缓存了BlockInfo,则使用缓存的BlockInfo,否则使用新建的BlockInfo。获取PutBlockInfo的实现,见代码如下:

2) 获取块最终使用的存储级别putLevel,根据putLevel判断块写入的BlockStore,从代码中可以看到,优先使用MemoryStorce;
3) xxxxxx
4) 如果putLevel.replication大于1,即为了容错考虑,数据的备份数量大于1的时候,需要将记录写入日志;

8.7.7 创建DiskBlockObjectWriter的方法getDiskWriter
getDiskWriter用于创建DiskBlockObjectWriter,见代码。属性spark.shuffle.sync决定写操作是同步还是异步。

8.7.8 获取本地Block数据方法getBlockData
getBlockData用于从本地获取Block的数据,见代码如下:

getBlockData的处理实现如下:
1) 如果Block是ShuffleMapTask的输出,那么多个partition的中间结果都写入了同一个文件,怎样读取不同partition的中间结果?IndexShuffleBlockManager的getBlockData方法解决了这个问题。
2) 如果Block是ResultTask的输出,则使用doGetLocal来获取本地中间结果数据。
8.7.9 获取本地shuffle数据方法doGetLocal
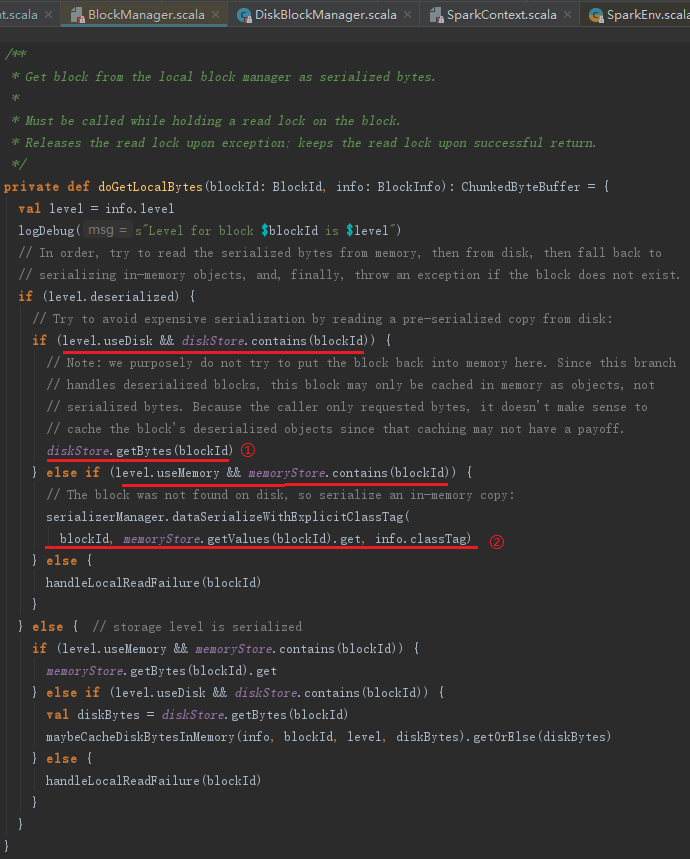
当reduce任务与map任务处于同一节点时,不需要远程拉取,只需调取doGetLocalBytes方法从本地获取中间处理结果即可。doGetLocalBytes的实现见代码如下,其处理步骤如下:
1) 如果Block允许使用内存,则调用MemoryStore的getValues或者getBytes方法获取。
2) 如果Block允许使用DiskStore,则调用DiskStore的getBytes方法获取。
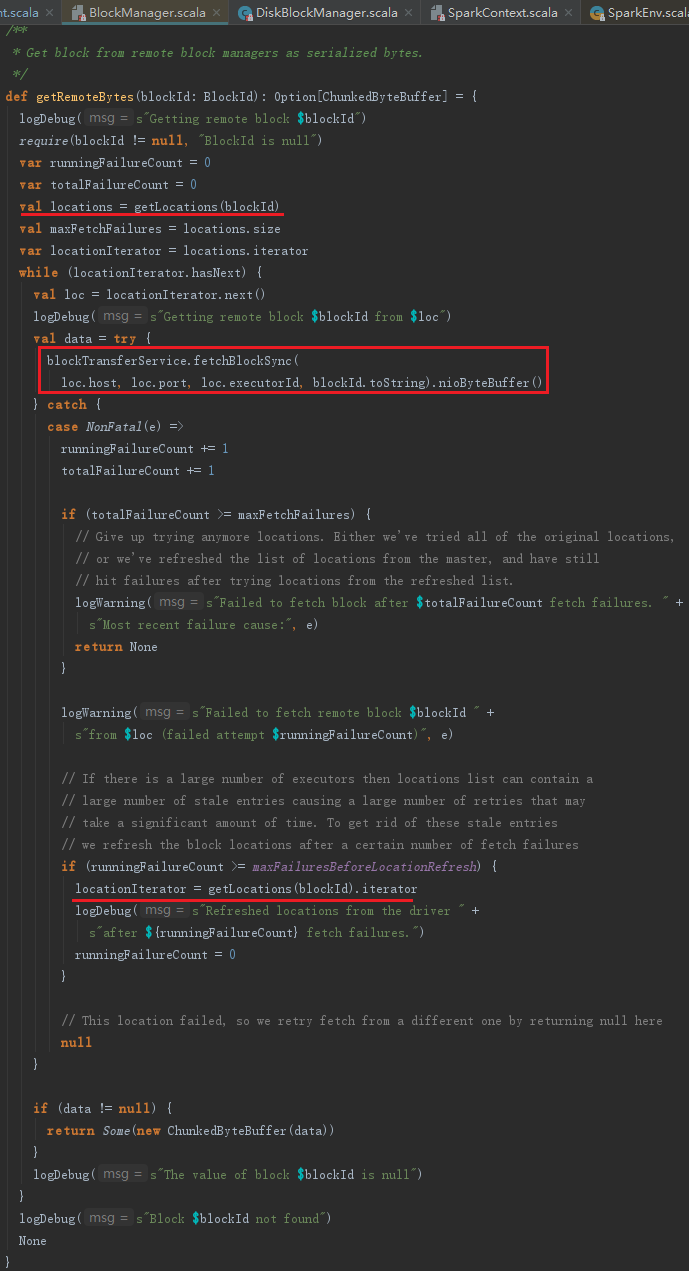
8.7.10 获取远程Block数据方法doGetRemote
getRemoteBytes用于从远端节点上获取Block数据,见代码如下。其处理步骤如下:
1) 向BlockManagerMasterEndpoint发送GetLocations消息获取Block数据存储的BlockManagerId。如果Block数据复制份数多于1个,则会返回多个BlockManagerId,对这些BlockManagerId洗牌,避免总是从一个远程BlockManager获取Block数据。发送GetLocations消息使用了getLocations方法,代码如下:

2) 根据返回的BlockManagerId信息,使用BlockTransferService远程同步获取Block数据。
8.7.11 获取Block数据方法get
get方法用于通过BlockId获取Block。get方法在实现上首先从本地获取,如果没有则去远程获取,见代码如下:

8.7.12 数据流序列化方法dataSerializeStream
如果写入存储体系的数据本身是序列化的,那么读取时应该对其反序列化。dataSerializeStream方法使用compressionCodec对文件输入流进行压缩和序列化处理,见代码如下:

4.9 metadataCleaner和broadcastCleaner
为了有效利用磁盘空间和内存,metadataCleaner和broadcastCleaner分别用于清除blockInfo(HashMap[BlockId, BlockInfo])中很久不用的非广播和广播Block信息。
8.10 缓存管理器CacheManager
8.11 压缩算法
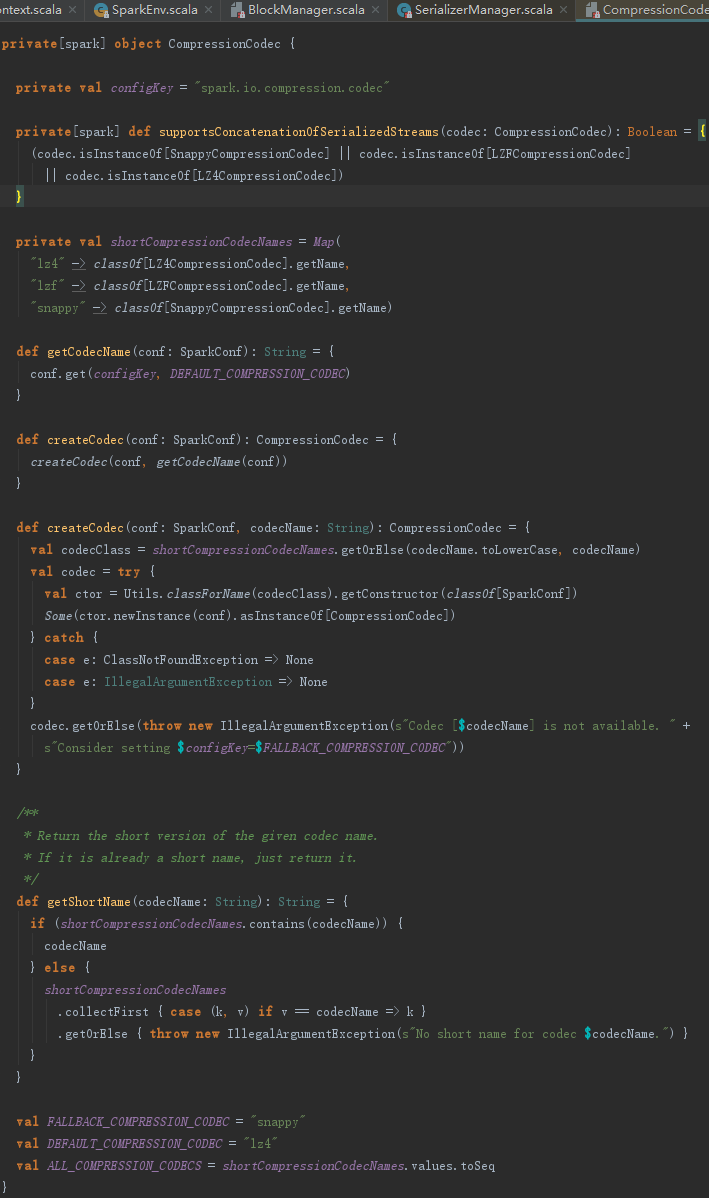
为了节省磁盘存储空间,有些情况下需要对Block进行压缩。根据配置属性spark.io.compression.codec来确定要使用的压缩算法(默认为snappy,此压缩算法在牺牲少量压缩比例的条件下,却极大地提高了压缩速度),并生成SnappyCompressionCodec的实例,见代码:
8.12 磁盘写入实现DiskBlockObjectWriter
DiskBlockObjectWriter被用于输出Spark任务的中间计算结果。在DiskBlockObjectWriter的commitAndGet方法中创建文件分片FileSegment(FileSegment记录分片的起始、结束偏移量),代码如下:

下面我们逐个讲解DiskBlockObjectWriter的其他方法,包括open、write、close、commitAndGet。
1. 打开一个文件输出流
DiskBlockObjectWriter的open方法,利用NIO、压缩、缓存、序列化方式打开一个文件输出流,见代码:

2. 写入文件
DiskBlockObjectWriter的write方法用于将数据写入文件,并更新测量信息,见代码如下:

3. 关闭文件输出流
DiskBlockObjectWriter的close方法用于关闭文件输出流,并更新测量信息,见代码如下:

4. 缓存数据提交
DiskBlockObjectWriter的commitAndGet方法将缓存数据写入磁盘并关闭缓存,然后更新测量数据,见代码如下:

8.13 块索引shuffle管理器IndexShuffleBlockResolver
IndexShuffleBlockResolver通常用于获取Block索引文件,并根据索引文件读取Block文件的数据。
1. 获取shuffle文件方法getBlockData
有时候我们不知道Block的BlockId,所以无法使用BlockManager的get方法获取Block。如果知道ShuffleBlockId,我们依然可以通过ShuffleBlockId记录的shuffleId和mapId获取Block。ShuffleBlockId的格式如下。

按照此格式生成的ShuffleBlockId能够关联shuffleId、mapId和reduceId的信息,例如,shuffle_0_0_0、shuffle_0_1_0等。
getBlockData方法根据shuffleId和mapId(即partitionId)读取索引文件,从索引文件中获得partition计算中间结果写入文件的偏移量和中间结果的大小,根据此偏移量和大小读取文件中partition的中间计算结果,见代码如下:

2. 获取shuffle数据文件方法getDataFile
getDataFile的实现代码如下:

getDataFile的实质是调用diskBlockManager的getFile方法。
3. 索引文件偏移量记录方法writeIndexFileAndCommit
writeIndexFileAndCommit方法用于在Block索引文件中记录各个partition的偏移量信息,便于下游Stage的任务读取,见代码如下:

8.14 shuffle内存管理器ShuffleMemoryManager
ShuffleMemoryManager用于执行shuffle操作的线程分配内存池。每种磁盘溢出集合(如ExternalAppendOnlyMap和ExternalSorter)都能从这个内存池获得内存。当溢出集合的数据已经输出到存储系统,获得的内存会释放。当线程执行的任务结束,整个内存池都会被Executor释放。ShuffleMemoryManager会保证每个线程都能合理地共享内存,而不会使得一些线程获得了很大的内存,导致其他线程经常不得不将溢出的数据写入磁盘。
尝试获得内存方法tryToAcquire
此方法用于当前线程尝试获得numBytes大小的内存,并返回实际获得的内存大小,见代码如下:
好像没有这个类ShuffleMemoryManager