spring boot 2.X集成ES 进行CRUD操作 完整版
内容包括:
=========================================================================================
1.CRUD:单字段查询、复合查询、分页查询、评分查询√
2.时间范围查询√
3.GET方法传入时间类型解析不了的问题√
4.term和match查询的区别√
5.filter+query查询的区别√
6.自定义ES的mapping,自定义settings√
7.解决@Field注解 设置分词器无效的问题、解决@Document注解 设置分区 以及备份无效的问题√
8.pinyin查询以及繁简体转化查询的集成√
9.同一个字段设置多种分词器的解决方案√
10.不同分词器的区别。读时分词和写时分词√
11.索引数据迁移
12.keyword与text类型区别以及引出的相关问题√
13.index创建的索引状态为yellow以及启动集群后对于index状态、分片、备份的影响
=======================================================================================
要求:
spring boot 2.0.1
elasticsearch 6.5.4
spring-boot-starter-data-elasticsearch
es中要求已经安装了ik分词器、pingyin分词器、繁简体转化分词器[安装步骤]
=======================================================================================
注明:
下文中红色字体部分,即为集成过程中解决的问题。
=======================================================================================
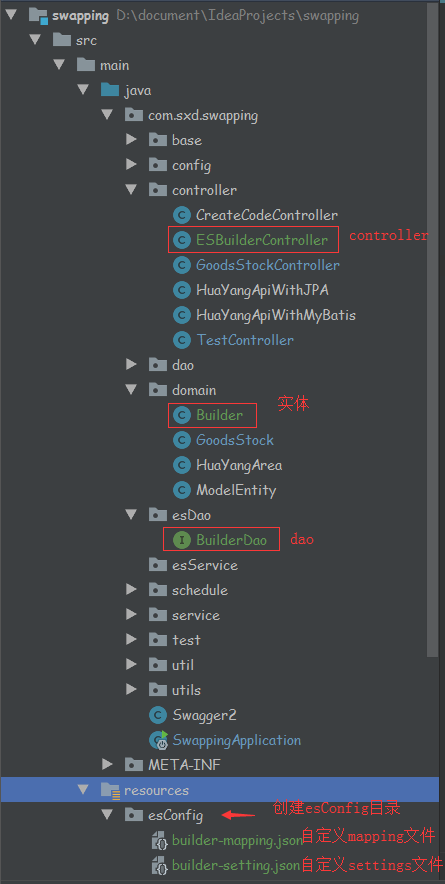
集成项目结构:
===================================================================================
正文
一、spring boot 集成ES基本操作的步骤
1.pom.xml引入jar包
<!-- spring-boot-starter-data-elasticsearch --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>
2.ES连接信息,配置在application.properties中
#elasticsearch相关配置
#es的cluster集群名称可以查看服务器安装的集群名称 curl http://192.168.92.130:9200 获取到集群名称
spring.data.elasticsearch.cluster-name=docker-cluster
#注意端口为9300 9300 是 Java 客户端的端口,支持集群之间的通信。9200 是支持 Restful HTTP 的接口
spring.data.elasticsearch.cluster-nodes=192.168.92.130:9300
3.测试实体Builder


package com.sxd.swapping.domain; import com.fasterxml.jackson.annotation.JsonFormat; import lombok.*; import org.springframework.data.elasticsearch.annotations.*; import javax.persistence.Id; import java.util.Date; /** * es的index的settings 和 mapping 设置,是最初的第一次设置。后续即使更改,也不起作用。 * 但是mapping中的属性名称以及属性个数如果更改了,会更新到ES中。这样会导致数据的丢失。需要注意。 */ @Setter @Getter //ES的三个注解 //指定index索引名称为项目名 指定type类型名称为实体名 @Document(indexName = "swapping",type = "builder") //相当于ES中的mapping 注意对比文件中的json和原生json 最外层的key是没有的 @Mapping(mappingPath = "/esConfig/builder-mapping.json") //相当于ES中的settings 注意对比文件中的json和原生json 最外层的key是没有的 @Setting(settingPath = "/esConfig/builder-setting.json") public class Builder { //id 测试长整型数据 注意与es中索引本身id区分开 @Id private Long id; //在创建初始化索引开始 就要去查看mapping是否ik分词创建成功 否则 需要进行索引数据的迁移操作 //指定查询分词器 为ik分词器 存储分词器为 ik分词器 //在@Field中指定的ik分词器没起作用,因此采用上面的两个注解 可以完全自定义类型Field的各个属性 //@Field(searchAnalyzer = "ik_max_word",analyzer = "ik_max_word") //类型定义为text 可测试ik分词 繁简体转化 pinyin分词 查询效果 //名称 测试字符串类型 private String buildName; //类型定义为text 可测试大文本 private String remark; //类型定义为keyword 可测试是否分词 以及查询效果 private String email; //数量 测试整型数据 private int buildNum; //时间也可以进行范围查询,但是查询传入参数,应该为mapping中定义的时间字段的 格式化字符串 或 时间戳 否则,ES无法解析格式会报错 //时间 测试时间类型 private Date buildDate; //积分比率 测试浮点型数据 private Double integral; //分页大小 private Integer pageNum = 0; //分页数量 private Integer pageSize = 10; }
注释1:
@Document注解,注明index名字是 swapping 项目名;type名字是 builder 实体名。【都是可以自定义的,如果可以,在settings中设置也是可以的】
注释2:
注释3:
自定义mapping
@Field注解中指定分词器无效的问题,是通过设置自定义mapping解决的。
同样,自定义mapping也解决了同一个字段指定多种分词器的问题。
注释4:
自定义settings
自定义settings的设置目的是为了,创建分词器规则以及对于index的自定义设置。因为@Document注解中设置分区和备份 可能无效的问题。通过自定义setting也可以解决。
注释5:
对于实体的mapping和settings的设置,在初始化启动的第一次,就创建成功了。
之后即使程序中自定义的mapping更改了,对于ES中index的mapping的设置也不会发生改动。
这也就意味着,如果在第一次创建index的时候,如果属性类型指定错误,或者分词器未设置,或者@Field中设置ik分词器无效等这些问题。那这些问题就一直存在,因为ES中的index的mapping在创建成功后就不能更改了。
因此,如果需要解决上述的这些问题,
要么就是在初次创建的时候,就使用[注释3]中的方式,自定义mapping。
要么就是在出现问题之后,使用 elasticsearch 提供的 reindex api 来迁移数据,创建新的索引。这样可以实现不影响线上的访问,需要无缝切换到新的索引上。
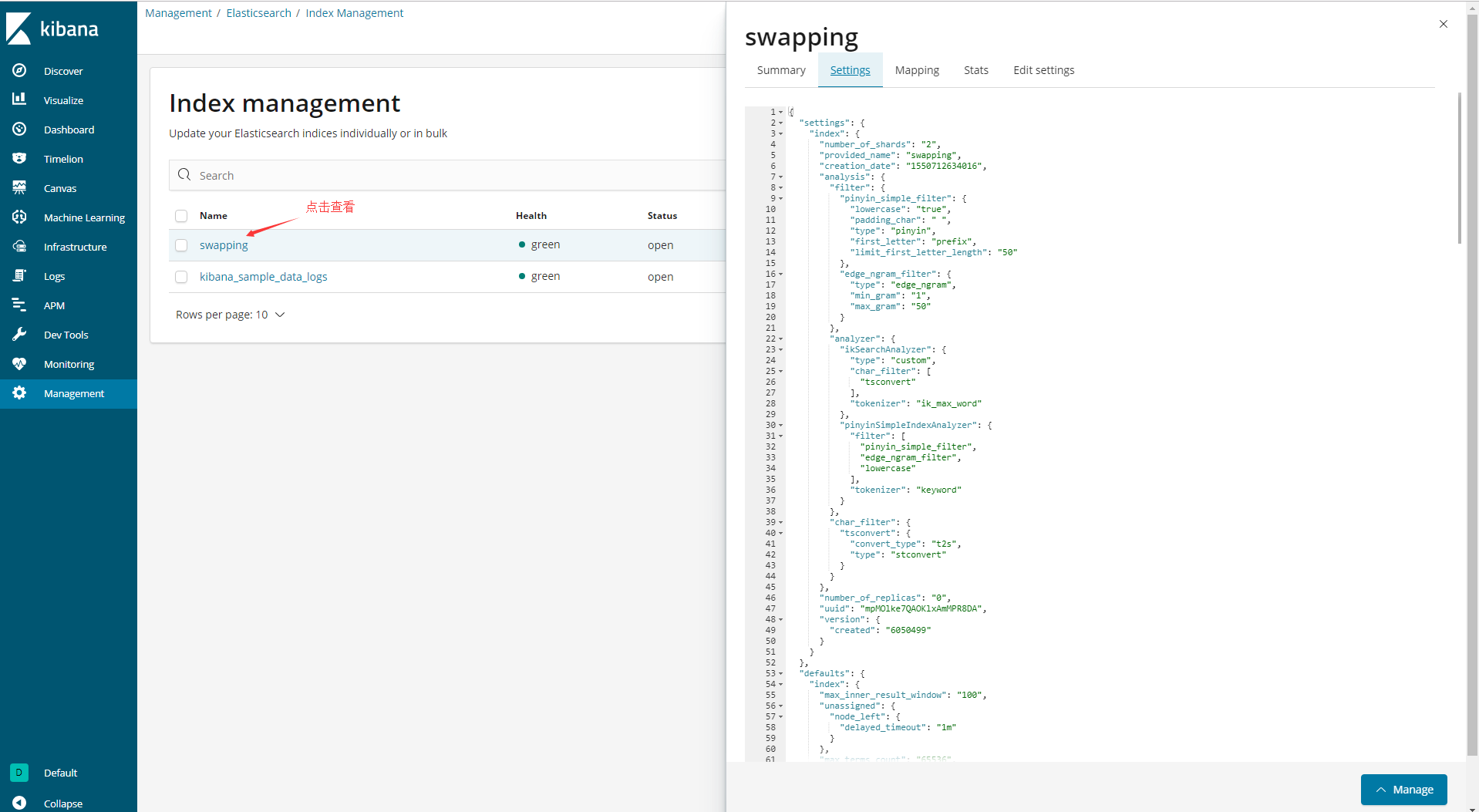
4.自定义index的settings
{
"index": {
"number_of_shards": "2",
"number_of_replicas": "0",
"analysis": {
"filter": {
"edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"pinyin_simple_filter": {
"type": "pinyin",
"first_letter": "prefix",
"padding_char": " ",
"limit_first_letter_length": 50,
"lowercase": true
}
},
"char_filter": {
"tsconvert": {
"type": "stconvert",
"convert_type": "t2s"
}
},
"analyzer": {
"ikSearchAnalyzer": {
"type": "custom",
"tokenizer": "ik_max_word",
"char_filter": [
"tsconvert"
]
},
"pinyinSimpleIndexAnalyzer": {
"tokenizer": "keyword",
"filter": [
"pinyin_simple_filter",
"edge_ngram_filter",
"lowercase"
]
}
}
}
}
}
注释1:
对比原生的settings,可以发现最外层的key是没有的。这里附上一份原生的settings,只做参考
{
"settings": {
"index": {
"refresh_interval": "1s",
"number_of_shards": "5",
"provided_name": "swapping",
"creation_date": "1550472518470",
"store": {
"type": "fs"
},
"number_of_replicas": "1",
"uuid": "e0UG1DH8RLG9_UYOzijSvw",
"version": {
"created": "6050499"
}
}
},
"defaults": {
"index": {
"max_inner_result_window": "100",
"unassigned": {
"node_left": {
"delayed_timeout": "1m"
}
},
"max_terms_count": "65536",
"routing_partition_size": "1",
"max_docvalue_fields_search": "100",
"merge": {
"scheduler": {
"max_thread_count": "1",
"auto_throttle": "true",
"max_merge_count": "6"
},
"policy": {
"reclaim_deletes_weight": "2.0",
"floor_segment": "2mb",
"max_merge_at_once_explicit": "30",
"max_merge_at_once": "10",
"max_merged_segment": "5gb",
"expunge_deletes_allowed": "10.0",
"segments_per_tier": "10.0",
"deletes_pct_allowed": "33.0"
}
},
"max_refresh_listeners": "1000",
"max_regex_length": "1000",
"load_fixed_bitset_filters_eagerly": "true",
"number_of_routing_shards": "5",
"write": {
"wait_for_active_shards": "1"
},
"mapping": {
"coerce": "false",
"nested_fields": {
"limit": "50"
},
"depth": {
"limit": "20"
},
"ignore_malformed": "false",
"total_fields": {
"limit": "1000"
}
},
"source_only": "false",
"soft_deletes": {
"enabled": "false",
"retention": {
"operations": "0"
}
},
"max_script_fields": "32",
"query": {
"default_field": [
"*"
],
"parse": {
"allow_unmapped_fields": "true"
}
},
"format": "0",
"sort": {
"missing": [],
"mode": [],
"field": [],
"order": []
},
"priority": "1",
"codec": "default",
"max_rescore_window": "10000",
"max_adjacency_matrix_filters": "100",
"gc_deletes": "60s",
"optimize_auto_generated_id": "true",
"max_ngram_diff": "1",
"translog": {
"generation_threshold_size": "64mb",
"flush_threshold_size": "512mb",
"sync_interval": "5s",
"retention": {
"size": "512mb",
"age": "12h"
},
"durability": "REQUEST"
},
"auto_expand_replicas": "false",
"mapper": {
"dynamic": "true"
},
"requests": {
"cache": {
"enable": "true"
}
},
"data_path": "",
"highlight": {
"max_analyzed_offset": "-1"
},
"routing": {
"rebalance": {
"enable": "all"
},
"allocation": {
"enable": "all",
"total_shards_per_node": "-1"
}
},
"search": {
"slowlog": {
"level": "TRACE",
"threshold": {
"fetch": {
"warn": "-1",
"trace": "-1",
"debug": "-1",
"info": "-1"
},
"query": {
"warn": "-1",
"trace": "-1",
"debug": "-1",
"info": "-1"
}
}
},
"throttled": "false"
},
"fielddata": {
"cache": "node"
},
"default_pipeline": "_none",
"max_slices_per_scroll": "1024",
"shard": {
"check_on_startup": "false"
},
"xpack": {
"watcher": {
"template": {
"version": ""
}
},
"version": "",
"ccr": {
"following_index": "false"
}
},
"percolator": {
"map_unmapped_fields_as_text": "false",
"map_unmapped_fields_as_string": "false"
},
"allocation": {
"max_retries": "5"
},
"indexing": {
"slowlog": {
"reformat": "true",
"threshold": {
"index": {
"warn": "-1",
"trace": "-1",
"debug": "-1",
"info": "-1"
}
},
"source": "1000",
"level": "TRACE"
}
},
"compound_format": "0.1",
"blocks": {
"metadata": "false",
"read": "false",
"read_only_allow_delete": "false",
"read_only": "false",
"write": "false"
},
"max_result_window": "10000",
"store": {
"stats_refresh_interval": "10s",
"fs": {
"fs_lock": "native"
},
"preload": []
},
"queries": {
"cache": {
"enabled": "true"
}
},
"ttl": {
"disable_purge": "false"
},
"warmer": {
"enabled": "true"
},
"max_shingle_diff": "3",
"query_string": {
"lenient": "false"
}
}
}
}
注释2:
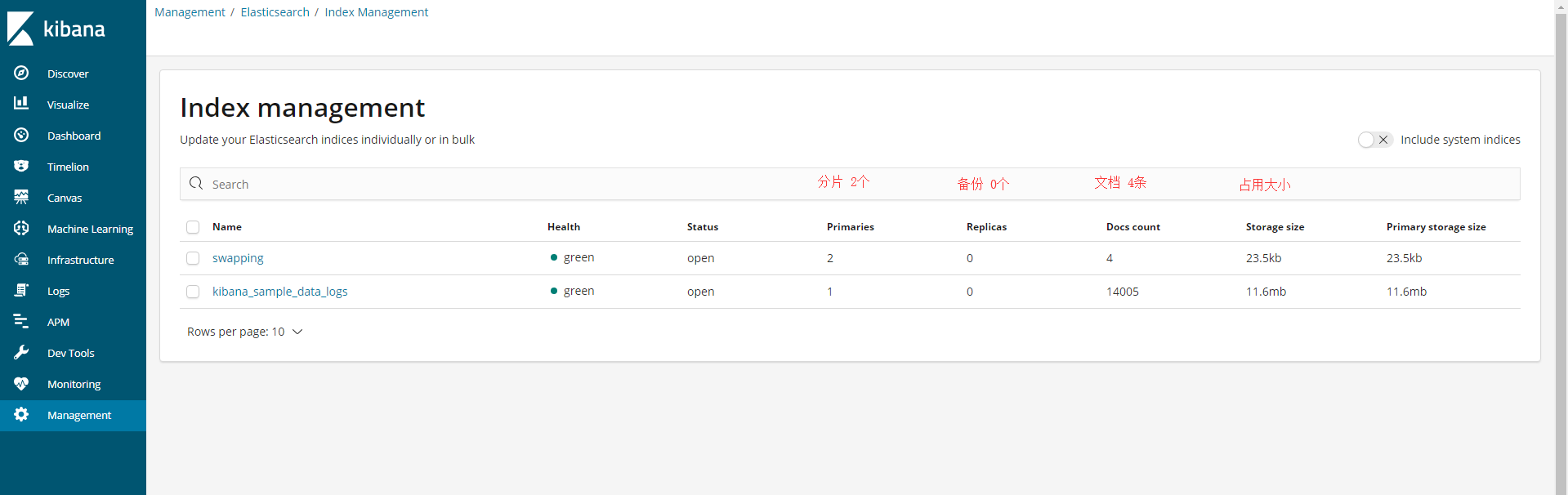
自定义settings中,设置分片是2,备份是0。如果是备份设置为1,则代表每个分片都有一个备份,则总共是4分。
因为ES只启动了一个node节点,所以会导致index的状态为yellow。因为一个节点,而分片又要创建备份的缘故,会导致备份创建无效。最后的index的state状态会显示为total=4,而success=2。虽然这样并不影响使用。
因此建议ES启动为多个nodes节点,启动为集群。
关于index设置分区和备份数量分别为多少,需要慎重!
注释3:
自定义setting中,JSON作用是创建两个分析器名为ikSearchAnalyzer,pinyinSimpleIndexAnalyzer,前者使用ik中文分词器加繁体转简体char_filter过滤,使得引用此分词器的字段在设置时,将会自动对中文进行分词和繁简体转换。
pinyinSimpleIndexAnalyzer 使用pinyin分词器,并进行edge_ngram 过滤,大写转小写过滤。
注释4:
通过自定义setting,实现了对同一字段设置多种分词器
注释5:
关于ES的内置分词器,可以详细看看。
注释6:
ES的分词器,其实就是插件,是工具。而对于分词的使用,其实可以分为读时分词和写时分词。
读时分词,发生在用户查询时,ES 会即时地对用户输入的关键词进行分词,分词结果只存在内存中,当查询结束时,分词结果也会随即消失。
写时分词,发生在文档写入时,ES 会对文档进行分词后,将结果存入倒排索引,该部分最终会以文件的形式存储于磁盘上,不会因查询结束或者 ES 重启而丢失。
看到这里,其实就明白了。写时分词,是在自定义mapping中指定的,而且一经指定就不能再修改,若要修改必须新建索引。
所以,查询的时候,我们可以自定义按照哪种想要的分词效果进行查询。没有指定,就是mapping中指定的查询分词。
写的时候就是按照mapping中指定的分词进行存储,如果没有指定,则按照ES默认的分词器进行分词存储!
注释7:
analyzer中设置的自定义的分词器的名字在mapping中会被引用
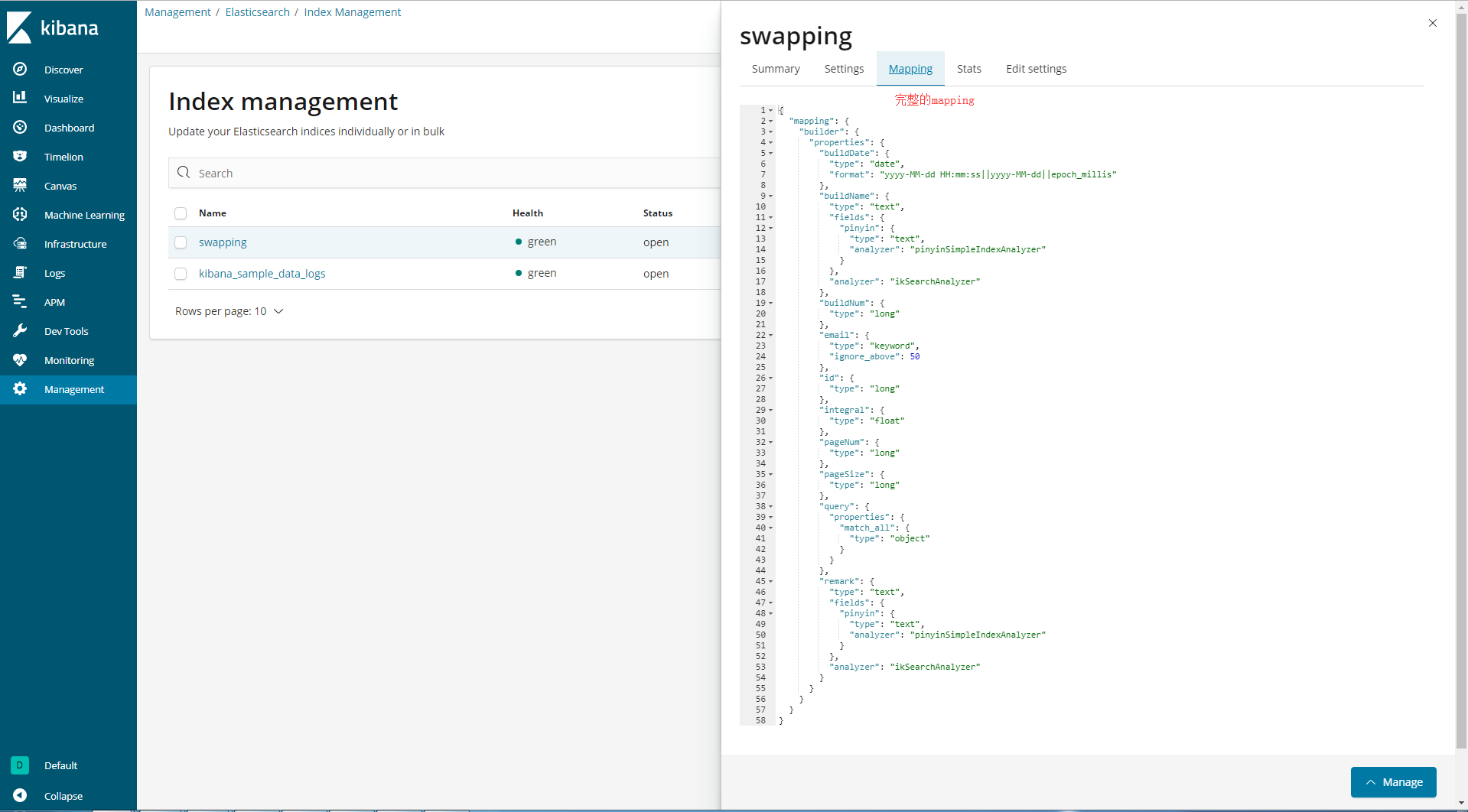
5.自定义Index的mapping
{
"builder": {
"properties": {
"id": {
"type": "long"
},
"buildName": {
"type": "text",
"analyzer": "ikSearchAnalyzer",
"search_analyzer": "ikSearchAnalyzer",
"fields": {
"pinyin": {
"type": "text",
"analyzer": "pinyinSimpleIndexAnalyzer",
"search_analyzer": "pinyinSimpleIndexAnalyzer"
}
}
},
"remark": {
"type": "text",
"analyzer": "ikSearchAnalyzer",
"search_analyzer": "ikSearchAnalyzer",
"fields": {
"pinyin": {
"type": "text",
"analyzer": "pinyinSimpleIndexAnalyzer",
"search_analyzer": "pinyinSimpleIndexAnalyzer"
}
}
},
"email": {
"type": "keyword",
"ignore_above": 50
},
"buildNum": {
"type": "long"
},
"buildDate": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"integral": {
"type": "float"
},
"pageNum": {
"type": "long"
},
"pageSize": {
"type": "long"
},
"query": {
"properties": {
"match_all": {
"type": "object"
}
}
}
}
}
}
注释1:
mapping中只要是对实体的各个属性对应的类型,以及分词器进行指定。
注释2:
尤其是时间字段,类型需要设置为date,时间格式需要设置为文件中指定的。
时间类型设置为date的目的,是对时间进行范围查询是可操作的。如果类型设置为text类型,则时间范围查询就无法实现。
时间格式的指定,是需要解析ES对接java程序,进行查询时候,传入参数可以是"yyyy-MM-dd"的时间字符串,也可以是时间戳。
需要注意的是:时间字段在ES中存储是时间戳,因此想要进行精准的时间查询以及时间范围查询,其实可以通过传入时间戳进行查询。后面的controller中有具体的方法。
注释3:
这里需要注意的是字符串类型的两种数据类型text和keyword。
text类型:支持分词、全文检索,不支持聚合、排序操作。适合大字段存储,如:文章详情、content字段等.
keyword类型:支持精确匹配,支持聚合、排序操作。适合精准字段匹配,如:url、name、email、title等字段.
keyword支持的最大长度为32766个UTF-8字符,且如果超过了ignore_above设置的字符串最大长度后,数据将不会被索引,无法通过term精确匹配查询.
text则不受长度限制
本点相关联的问题:
问题1:设置为keyword类型的字段,插入很长的大段内容后,报字符超出异常,无法插入。
问题2:检索超过ignore_above设定长度的字段后,无法返回结果
注释4:
在自定义mapping中实现了对同一字段设置多个分词器。
注释5:
对于上面字段中fields的设置,例如 pinyin,是自定义的,会在controller中查询时候,指定按照mapping中设置好的分词器查询时候,用到。
QueryBuilder ikSTQuery = QueryBuilders.matchQuery("buildName",pinyinStr).boost(1f);
QueryBuilder pinyinQuery = QueryBuilders.matchQuery("buildName.pinyin",pinyinStr);
当然,除了可以用mapping中预先设定好的强大的分词器之外,也可以自己指定分词器进行查询。[前提是你的ES中默认有或者你自己安装了的分词器]
QueryBuilder matchBuilder = QueryBuilders.matchQuery( "buildName" ,str).analyzer("ik_max_word");
这里的分词器,可以参考4中注释5的 ES中默认的分词器 进行赋值。甚至更多。
注释6:
这里的分词器名称,采用自定义settings中预先设置的分词器名称。
6.继承ElasticsearchRepository的BuilderDao
package com.sxd.swapping.esDao; import com.sxd.swapping.domain.Builder; import org.springframework.data.elasticsearch.repository.ElasticsearchRepository; public interface BuilderDao extends ElasticsearchRepository<Builder,Long>{ }
7.controller层CRUD
package com.sxd.swapping.controller; import com.sxd.swapping.base.UniVerResponse; import com.sxd.swapping.domain.Builder; import com.sxd.swapping.esDao.BuilderDao; import org.elasticsearch.index.query.*; import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.propertyeditors.CustomDateEditor; import org.springframework.data.domain.Page; import org.springframework.data.domain.PageRequest; import org.springframework.data.domain.Pageable; import org.springframework.data.domain.Sort; import org.springframework.data.elasticsearch.core.query.SearchQuery; import org.springframework.web.bind.WebDataBinder; import org.springframework.web.bind.annotation.*; import java.text.SimpleDateFormat; import java.util.*; /** * 使用方式有两种: * 1.一种是经过 SpringData 封装过的,直接在 dao 接口继承 ElasticsearchRepository 即可 * 2.一种是经过 Spring 封装过的,直接在 Service/Controller 中引入该 bean 即可 ElasticsearchTemplate */ @RestController @RequestMapping("/es") public class ESBuilderController { @Autowired BuilderDao builderDao; /** * 方式1 * * 单个保存索引 * @return */ @RequestMapping(value = "/save", method = RequestMethod.POST) public UniVerResponse<Builder> save(@RequestBody Builder builder){ builder = builder == null ? new Builder() : builder; UniVerResponse<Builder> res = new UniVerResponse<>(); Builder builder2 = builderDao.save(builder); res.beTrue(builder2); return res; } /** * 方式1 * * 根据ID获取单个索引 * @param id * @return */ @RequestMapping(value = "/get", method = RequestMethod.GET) public UniVerResponse<Builder> get(Long id){ UniVerResponse<Builder> res = new UniVerResponse<>(); Optional<Builder> get = builderDao.findById(id); res.beTrue(get.isPresent() == false ? null : get.get()); return res; } /** * ============================单条件查询================================== */ /** * 方式1 * * 通过match进行模糊查询 * 根据传入属性值,检索指定属性下是否有匹配 * * 例如: * name:中国人 * 那么查询会将 中国人 进行分词, 中国 人 国人 等。之后再进行查询匹配 * * @param name * @return */ @RequestMapping(value = "/searchNameByMatch", method = RequestMethod.GET) public UniVerResponse<List<Builder>> searchNameByMatch(String name){ UniVerResponse<List<Builder>> res = new UniVerResponse<>(); MatchQueryBuilder matchBuilder = QueryBuilders.matchQuery("buildName",name); Iterable<Builder> search = builderDao.search(matchBuilder); Iterator<Builder> iterator = search.iterator(); List<Builder> list = new ArrayList<>(); while (iterator.hasNext()){ list.add(iterator.next()); } res.beTrue(list); return res; } /** * 方式1 * * 通过term进行全量完全匹配查询 * 根据传入属性值,检索指定属性下是否有属性值完全匹配的 * * 例如: * name:中国人 * 那么查询不会进行分词,就是按照 包含完整的 中国人 进行查询匹配 * * 此时ik中文分词 并没有起作用【此时是在@Field注解 指定的ik分词器】 * 例如存入 张卫健 三个字,以ik_max_word 分词存入,查询也指定以ik查询,但是 以张卫健 查询 没有结果 * 以 【张】 或 【卫】 或 【健】 查询 才有结果,说明分词是以默认分词器 进行分词 ,也就是一个中文汉字 进行一个分词的效果。 * * * * @param name * @return */ @RequestMapping(value = "/searchNameByTerm", method = RequestMethod.GET) public UniVerResponse<List<Builder>> searchNameByTerm(String name){ UniVerResponse<List<Builder>> res = new UniVerResponse<>(); TermQueryBuilder termBuilder = QueryBuilders.termQuery("buildName",name); Iterable<Builder> search = builderDao.search(termBuilder); Iterator<Builder> iterator = search.iterator(); List<Builder> list = new ArrayList<>(); while (iterator.hasNext()){ list.add(iterator.next()); } res.beTrue(list); return res; } /** * 方式1 * * 根据range进行范围查询 * * 时间也可以进行范围查询,但时间传入值应该为yyyy-MM-dd HH:mm:ss 格式的时间字符串或时间戳 或其他定义的时间格式 * 只有在mapping中定义的时间格式,才能被ES查询解析成功 * * @param num * @return */ @RequestMapping(value = "/searchNumByRange", method = RequestMethod.GET) public UniVerResponse<List<Builder>> searchNumByRange(Integer num){ UniVerResponse<List<Builder>> res = new UniVerResponse<>(); RangeQueryBuilder rangeBuilder = QueryBuilders.rangeQuery("buildNum").gt(0).lt(num); Iterable<Builder> search = builderDao.search(rangeBuilder); Iterator<Builder> iterator = search.iterator(); List<Builder> list = new ArrayList<>(); while (iterator.hasNext()){ list.add(iterator.next()); } res.beTrue(list); return res; } //处理GET请求的时间转化 @InitBinder public void initBinder(WebDataBinder binder) { SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd"); dateFormat.setLenient(false); binder.registerCustomEditor(Date.class, new CustomDateEditor(dateFormat, true)); } /** * ============================复合条件查询================================== */ /** * 方式1 * * 使用bool进行复合查询,使用filter比must query性能好 * * filter是过滤,1.文档是否包含于结果 2.不涉及评分 3.更快 * query是查询,1.文档是否匹配于结果 2.计算文档匹配评分 3.速度慢 * * * @param builder * @return */ @RequestMapping(value = "/searchByBool", method = RequestMethod.GET) public UniVerResponse<Page<Builder>> searchByBool(Builder builder){ UniVerResponse<Page<Builder>> res = new UniVerResponse<>(); BoolQueryBuilder boolBuilder = QueryBuilders.boolQuery(); //多个字段匹配 属性值 must query MultiMatchQueryBuilder matchQueryBuilder = QueryBuilders.multiMatchQuery(builder.getBuildName(),"buildName","buildName2"); boolBuilder.must(matchQueryBuilder); //filter 分别过滤不同字段,缩小筛选范围 TermQueryBuilder numQuery = QueryBuilders.termQuery("buildNum",builder.getBuildNum()); boolBuilder.filter(numQuery); RangeQueryBuilder dateQuery = QueryBuilders.rangeQuery("buildDate").lt(builder.getBuildDate().getTime()); boolBuilder.filter(dateQuery); //排序 + 分页 Sort sort = Sort.by(Sort.Direction.DESC,"buildNum"); PageRequest pageRequest = PageRequest.of(builder.getPageNum()-1,builder.getPageSize(),sort); Page<Builder> search = builderDao.search(boolBuilder, pageRequest); res.beTrue(search); return res; } /** * 方式1 * 时间范围查询 * ES中时间字段需要设置为 date类型,才能查询时间范围 * 时间范围要想准确查询,需要将时间转化为时间戳进行查询 * * ES中date字段存储是 时间戳存储 * * * from[包含] - to[包含] * gt - lt * gte - lte * * * * @return */ @RequestMapping(value = "/searchByTimeRange", method = RequestMethod.GET) public UniVerResponse<List<Builder>> searchByTimeRange(Builder builder){ UniVerResponse<List<Builder>> res = new UniVerResponse<>(); QueryBuilder queryBuilder = QueryBuilders.rangeQuery("buildDate").from(builder.getBuildDate().getTime()); Iterable<Builder> search = builderDao.search(queryBuilder); Iterator<Builder> iterator = search.iterator(); List<Builder> list = new ArrayList<>(); while (iterator.hasNext()){ list.add(iterator.next()); } res.beTrue(list); return res; } /** * 方式1 * * 检索所有索引 * @return */ @RequestMapping(value = "/searchAll", method = RequestMethod.GET) public UniVerResponse<List<Builder>> searchAll(){ UniVerResponse<List<Builder>> res = new UniVerResponse<>(); QueryBuilder queryBuilder = QueryBuilders.boolQuery(); Iterable<Builder> search = builderDao.search(queryBuilder); Iterator<Builder> iterator = search.iterator(); List<Builder> list = new ArrayList<>(); while (iterator.hasNext()){ list.add(iterator.next()); } res.beTrue(list); return res; } /** * 方式1 * * 根据传入属性值 全文检索所有属性 * 关于QueryStringQueryBuilder的使用,如果不指定分词器,那么查询的时候,会使用ES默认的分词器进行查询。 * 结果就是 会查询出与查询内容丝毫不相干的结果。 * * * 关于ES内置分词器: * https://blog.csdn.net/u013795975/article/details/81102010 * * * * @return */ @RequestMapping(value = "/findByStr", method = RequestMethod.GET) public UniVerResponse<List<Builder>> findByStr(String paramStr){ UniVerResponse<List<Builder>> res = new UniVerResponse<>(); QueryStringQueryBuilder qsqb = new QueryStringQueryBuilder(paramStr).analyzer("standard"); Iterable<Builder> search = builderDao.search(qsqb); Iterator<Builder> iterator = search.iterator(); List<Builder> list = new ArrayList<>(); while (iterator.hasNext()){ list.add(iterator.next()); } res.beTrue(list); return res; } /** * 方式1 * * 选择用term或match方式查询 * 查询字段buildName或者buildName2 * 指定以分词器 ik_max_word 或 ik_smart 或 standard[es默认分词器] 或 english 或 whitespace 分词器进行分词查询 * * * * @param analyzer 分词器 * @param str 查询属性值 * @param param 指定是参数1[buildName] 还是 参数2[remark] * @return */ @RequestMapping(value = "/searchByIK", method = RequestMethod.GET) public UniVerResponse<List<Builder>> searchByIK(String analyzer,String str,Integer param){ UniVerResponse<List<Builder>> res = new UniVerResponse<>(); QueryBuilder matchBuilder = QueryBuilders.matchQuery(param ==1 ? "buildName" : "remark",str).analyzer(analyzer); Iterable<Builder> search = builderDao.search(matchBuilder); Iterator<Builder> iterator = search.iterator(); List<Builder> list = new ArrayList<>(); while (iterator.hasNext()){ list.add(iterator.next()); } res.beTrue(list); return res; } /** * 方式1 * * 繁简体转化查询、拼音查询,并且加入评分查询 * 评分规则详情:https://blog.csdn.net/paditang/article/details/79098830 * @param pinyinStr * @return */ @RequestMapping(value = "/searchByPinYin",method = RequestMethod.GET) public UniVerResponse<List<Builder>> searchByPinYin(String pinyinStr){ UniVerResponse<List<Builder>> res = new UniVerResponse<>(); DisMaxQueryBuilder disMaxQuery = QueryBuilders.disMaxQuery(); QueryBuilder ikSTQuery = QueryBuilders.matchQuery("buildName",pinyinStr).boost(1f); QueryBuilder pinyinQuery = QueryBuilders.matchQuery("buildName.pinyin",pinyinStr); disMaxQuery.add(ikSTQuery); disMaxQuery.add(pinyinQuery); Iterable<Builder> search = builderDao.search(disMaxQuery); Iterator<Builder> iterator = search.iterator(); List<Builder> list = new ArrayList<>(); while (iterator.hasNext()){ list.add(iterator.next()); } res.beTrue(list); return res; } /** * * @param builder * @return */ @RequestMapping(value = "/delete", method = RequestMethod.POST) public UniVerResponse<Builder> delete(@RequestBody Builder builder){ UniVerResponse<Builder> res = new UniVerResponse<>(); builderDao.deleteById(builder.getId()); res.beTrue(builder); return res; } }
注释1:
注意GET请求接受时间转化
注释2:
filter和query的区别
filter是过滤,1.文档是否匹配 2.不涉及评分 3.更快 4.会自动缓存,下次查询速度会更快
query是查询,1.文档是否匹配查詢,相关度高不高 2.计算文档匹配评分 3.速度慢 4.查询的结果要比filter可能更多一些,因为涉及评分,所以更精确
注释3:
term和match的区别
* 通过match进行模糊查询 * 根据传入属性值进行分词,检索指定属性下是否有匹配 * * 例如: * name:中国人 * 那么查询会将 中国人 进行分词, 中国 人 国人 等。之后再进行查询匹配
* 通过term进行全量完全匹配查询 * 根据传入属性值,检索指定属性下是否有属性值完全匹配的 * * 例如: * name:中国人 * 那么查询不会进行分词,就是按照 完整的 中国人 进行查询匹配
============================================================================
二、kibana管理index
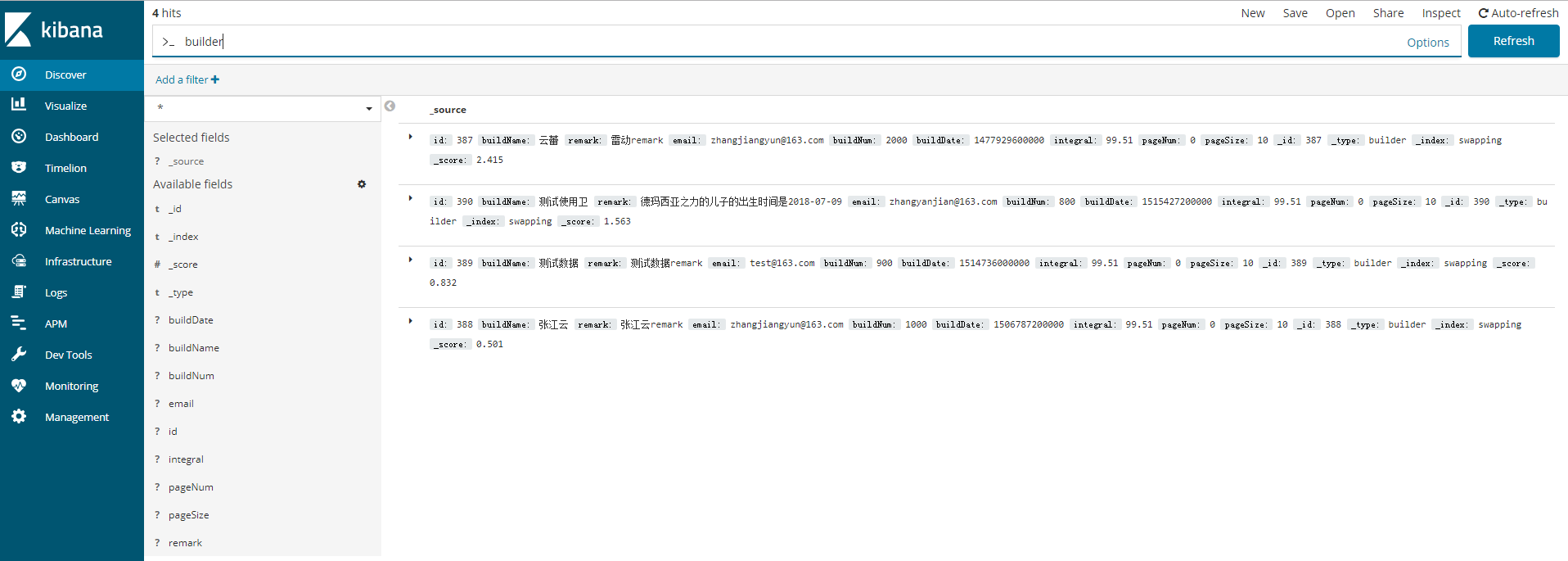
1.Discover下查询
1.1输入上面操作的type名builder,可以看到ES中已经存入的document
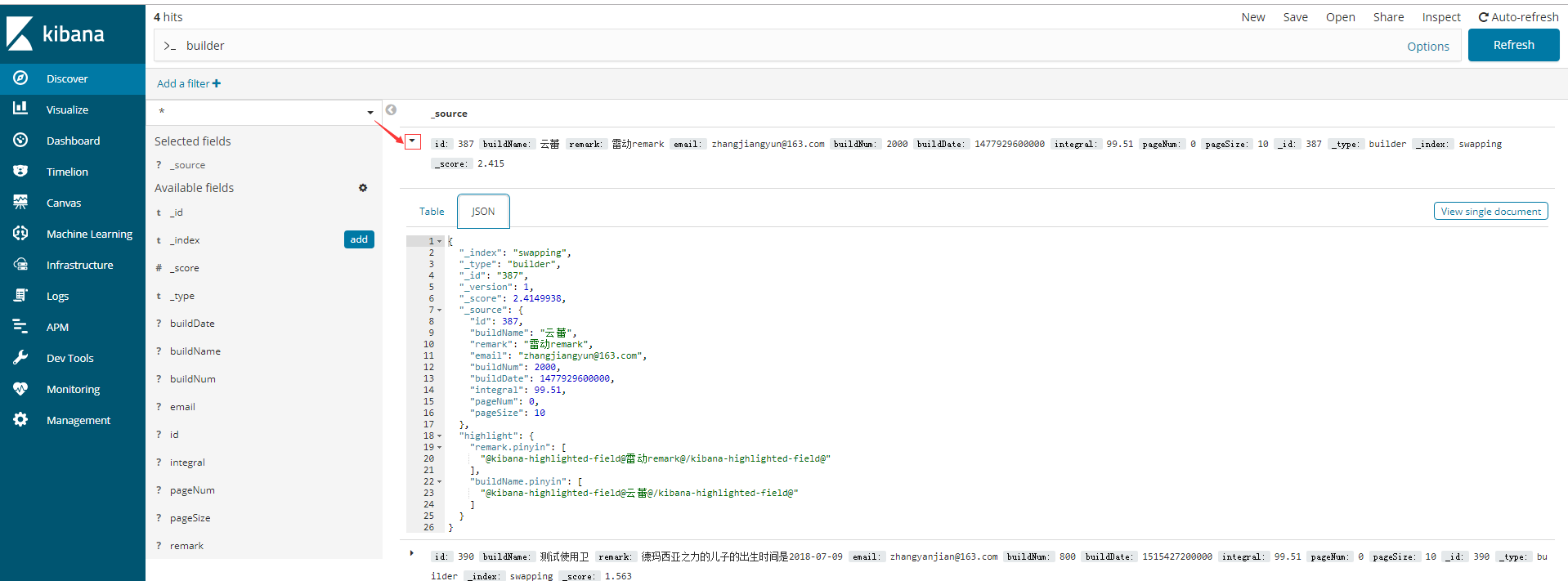
1.2点击每一条Document左侧的三角,可以下拉查看document详情
2.Monitoring下管理
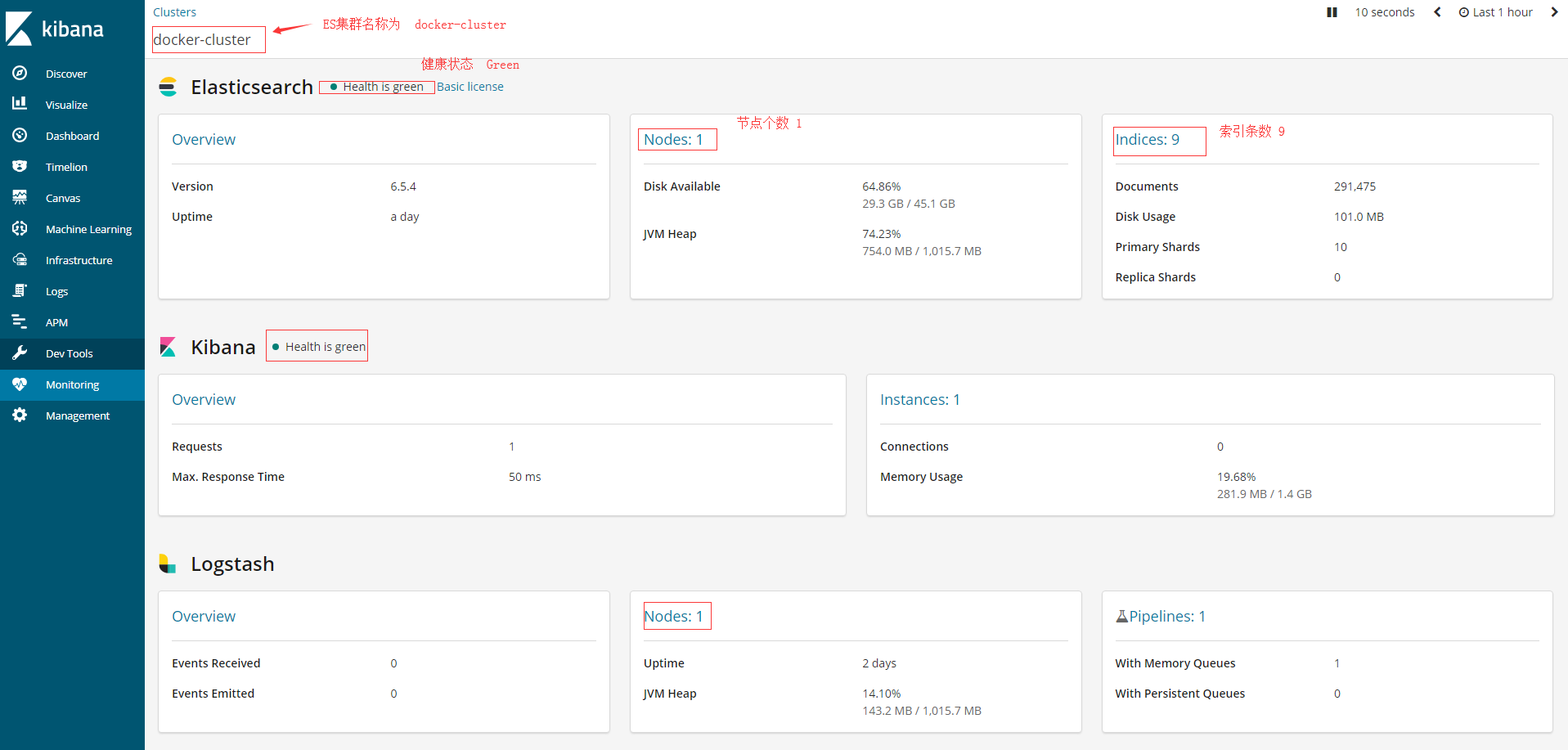
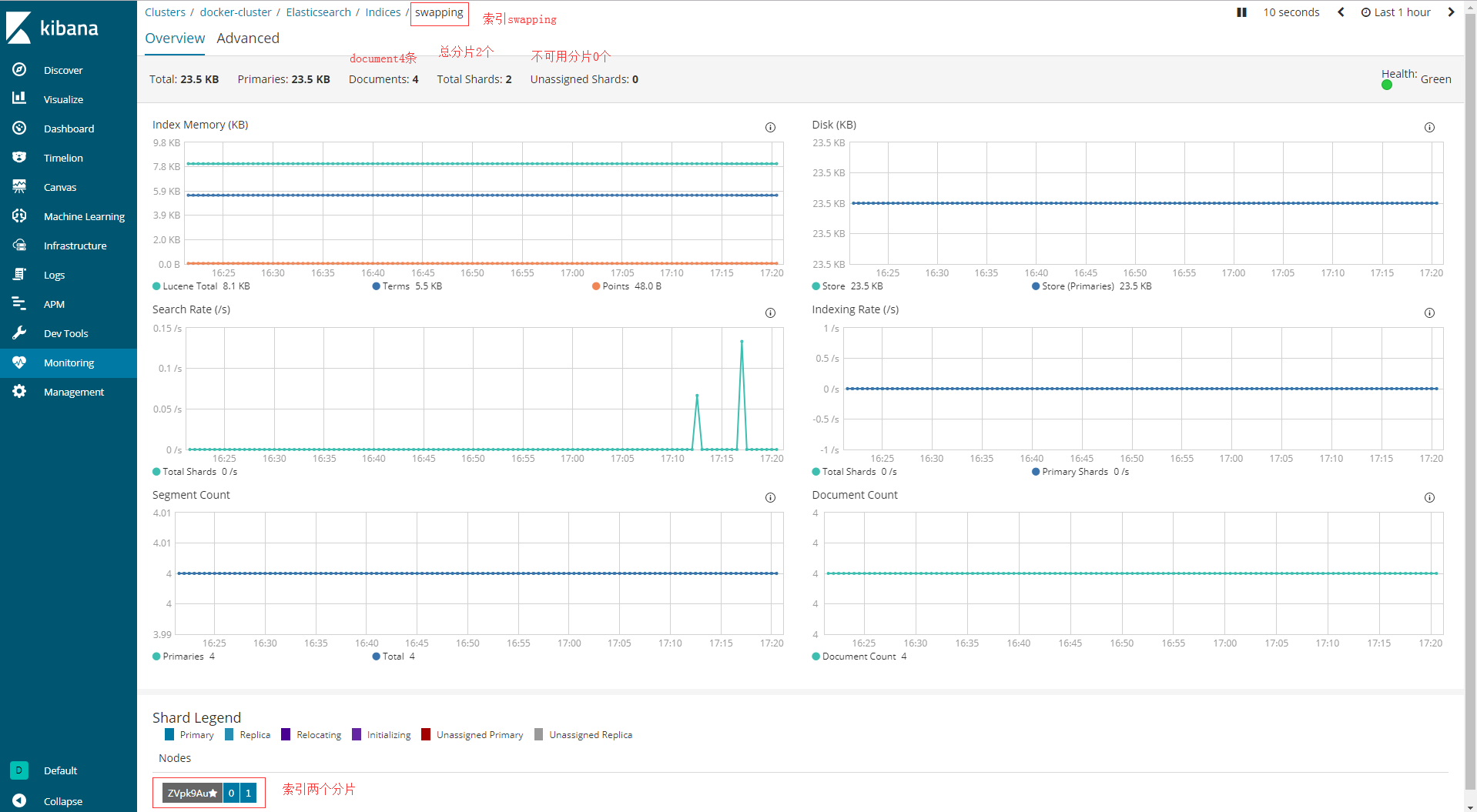
3.Management管理

=================================告一段落================================================