本文將探討在使用SQL Server時有那些原因可能會造成過度消耗CPU資源,若CPU使用率管理不善或過度使用CPU資源的話,可能會對SQL Server有明顯的影響,建議您需要增加或更換CPU。。
一般來說檢測資料庫伺服器CPU是否遭遇瓶頸很容易觀察,在使預SQL Server時,若 CPU持續15分鐘維持在70~80%以上的使用率(排除突發性狀況),且後效能逐漸下降,那麼就可以判定資料庫伺服器可能遭遇CPU瓶頸。本文章提供您參考有那些原因可能會造成過度消耗CPU資源,若CPU使用率管理不善或過度使用CPU資源的話,可能會對SQL Server有明顯的影響,建議您需要增加或更換CPU了。
主要常被使用來檢測的工具有兩種,第一種『效能監視器 (Performance Monitor)』,第二種是DMV。
一、 效能監視器(Performance Monitor) 只要在資料庫伺服器機器上,在開始命令框中輸入perfmon按確認鍵即可打開效能監視器,如下圖1所示。
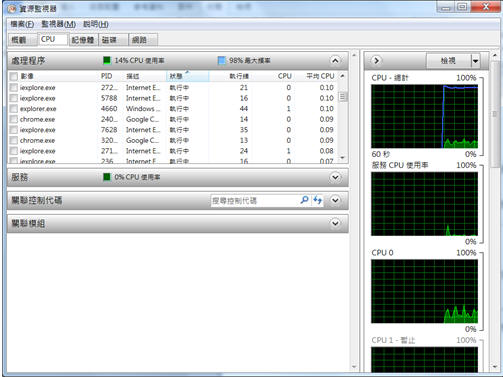 圖1:效能監視器
圖1:效能監視器
使用者可以透過效能監視器中的Processor:% Processor Time計數器來判定CPU的使用量,此值最好不要超出80%,此計數器可監視CPU花費在執行非閒置執行緒上的時間,若狀態大於80%則表示可能必須將 CPU升級或增加更多的處理器。
另外,也可以使用下列計數器監視CPU的使用狀態: Processor / % Privileged Time 相當於處理器花費在執行 Microsoft Windows 系統核心命令的時間百分比。 Processor/ %User Time 相當於處理器花費在執行使用者命令 (如 SQL Server I/O請求) 的時間百分比。 Process (sqlserver.exe)/ %Processor Time 每一個處理序包含所有執行序所花費CPU執行時間總和。
上述資料來源可參考Microsoft SQL Server 文件庫,有更詳細的說明。
二、 DMV 我們可透過下面兩項DMV相關的CPU統計資料來分析高CPU使用率的原因。
sys.dm_os_wait_stats : 傳回執行中之執行緒所遇到之所有等候的相關資訊sys.dm_os_waiting_tasks:查詢現階段所等待的任務
下面的語句可以查詢排名前10名的各類資源等待的時間比率及查詢結果(如圖2所示)。
SELECT TOP 10 wait_type, waiting_tasks_count, ( wait_time_ms - signal_wait_time_ms ) as resource_wait_time, max_wait_time_ms, case when waiting_tasks_count = 0 then 0 else wait_time_ms / waiting_tasks_count end as avg_wait_time FROM sys .dm_os_wait_stats WHERE wait_type NOT LIKE '%SLEEP%' AND wait_type NOT LIKE 'XE%' AND wait_type NOT IN ( 'PREEMPTIVE_OS_AUTHENTICATIONOPS', 'BROKER_TO_FLUSH','KSOURCE_WAKEUP', 'BROKER_TASK_STOP', 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'DBMIRROR_EVENTS_QUEUE', 'SQLTRACE_BUFFER_FLUSH', 'CLR_MANUAL_EVENT', 'SQLTRACE_BUFFER_FLUSH', 'CLR_AUTO_EVENT', 'BROKER_EVENTHANDLER', 'BAD_PAGE_PROCESS', 'BROKER_TRANSMITTER', 'CHECKPOINT_QUEUE','ONDEMAND_TASK_QUEUE', 'REQUEST_FOR_DEADLOCK_SEARCH' , 'LOGMGR_QUEUE', 'BROKER_RECEIVE_WAITFOR', 'PREEMPTIVE_OS_GETPROCADDRESS' ) ORDER BY wait_time_ms DESC
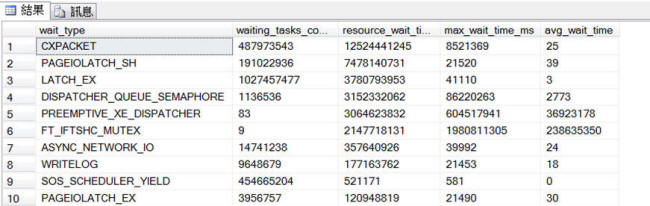 圖2:排名前10名的各類資源等待的時間比率查詢結果
圖2:排名前10名的各類資源等待的時間比率查詢結果
與CPU相關的等待類型主要有SOS_SCHEDULER_YIELD、CXPACKET和CMEMTHREAD。
-
SOS_SCHEDULER_YIELD:若出現此種等待類型且整體等待時間相當高的話,就表示有高密集的CPU查詢,這時需優化及調校相關高成本CPU查詢語法,或是SERVER的CPU資源真的不足夠。換句話說,如果系統有足夠的CPU資源便可以執行相關任務,則此類型的等待時間應會是相當低的。
-
CXPACKET:此種等待類型表示可能有查詢誤用平行化處理。採取平行化處理的時機應是在接受少量查詢並含有大量資料時。當OLTP存在很多小量查詢或交易時,使用平行化處理反而會影響效能。
-
CMEMTHREAD:一般來說,CMEMTHREAD這類的等待不常見,就算有,其整體等待時間應該也很低。所以說如果等待時間很高,表示系統存在過多動態或ad hoc的查詢,因為過高的快取大小可能會造成過度使用CPU資源。
sys.dm_exec_query_stats 、sys.dm_exec_sql_text:用來查詢高成本CPU語法。
下面的語句可以查詢出最耗時的前50個SQL指令。
SELECT TOP 50 *, (total_worker_time / execution_count) AS avgworkertime FROM sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) ORDER BY avgworkertime DESC
下面的語句可以查詢出最常使用的前50個SQL指令。
SELECT TOP 50 * FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st ORDER BY qs.plan_generation_num DESC
除此之外,資料庫伺服器最常執行的指令應是屬於SQL查詢語句。下面語句可以找出佔用CPU時間最長的SQL查詢指令及查詢結果(如圖3所示)。
SELECT TOP 10 substring(ST.text, ( QS.statement_start_offset / 2 ) + 1, ( ( case statement_end_offset when -1 then DATALENGTH (st.text) else QS.statement_end_offset end - S.statement_start_offset ) / 2 ) + 1 ) as statement_text , total_worker_time / 1000 as total_worker_time_ms, execution_count, ( total_worker_time / 1000 ) / execution_count as avg_worker_time_ms, total_logical_reads, total_logical_reads / execution_count as avg_logical_reads, qp.query_plan FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle ) st CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp ORDER BY total_worker_time DESC
 圖3:佔用CPU時間的TOP 10查詢結果
圖3:佔用CPU時間的TOP 10查詢結果
我們盡可能的去最佳化這些SQL語句。充分地利用查詢計畫等工具,便可以大大地提高查詢效率及改善資料庫伺服器的效能。
本篇文章提供您參考有那些原因可能會造成SQL Server過度消耗CPU資源,若CPU使用率管理不善或過度使用CPU資源的話,可能會對SQL Server有明顯的影響。一般來說,在10~15分鐘內,CPU的使用率不應持續超過70%~80%以上,但如果不幸發生這樣的情況時,第一步要先確認CPU資源是否都為SQL Server所使用,之後再找出高CPU使用率的問題主因。若透過SQL Tuning(建立索引、改善不良語法及優化常用語法..等)或改變相關設定值後,依然無法降低資料庫伺服器的CPU使用率,那麼可能資料庫伺服器CPU已經遭遇到瓶頸了,建議您需要增加或更換CPU了。