一.了解Map集合吗?Map集合都有哪些实现
1.HashMap
2.HashTable
3.LinkedHashMap
4.TreeMap
5.ConcurrentHashMap
二.HashMap和HashTable之间的区别
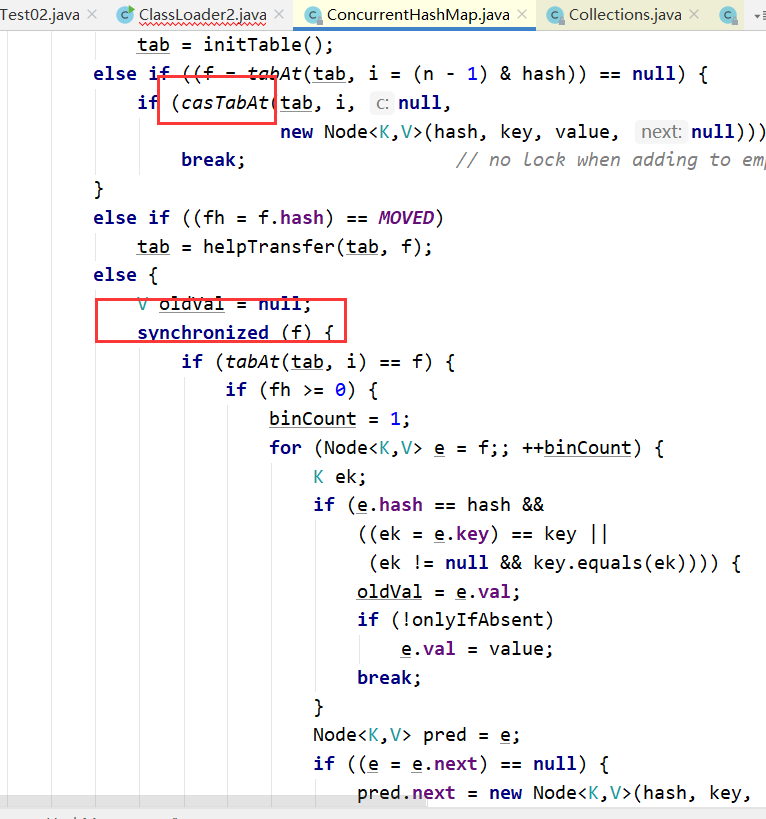
1.HashMap:底层基于数组+单向链表(红黑树),非线程安全,默认容量为16,允许有空的键和值
数组:Node<K,V> [] table ,每一个元素都是一个Node
单向链表:Node<K,V> next,当发生Hash碰撞,会追加链表,当链表长度大于8,
那就转换为红黑树
2.HashTable:底层基于哈希表实现,线程是安全的,默认容量为11,不允许有空的键和值
三.hashCode()和equals()方法使用场景
hashCode():
顶级父类Object当中的方法,返回值类型为int类型的值,根据一定的规则(存储地址,字段,长
度等等)生成一个数组,数据保存的就是Hash值
equals():
顶级类Object中的方法,根据一定的比较规则,判断对象是否一致,底层一般逻辑:
1.判断两个对象的内存地址是否一样
2.非空判断和Class类型判断
3.强转
4.对象中的字段一一匹配
public class UserInfo { private Integer uid; private String uname; public Integer getUid() { return uid; } public void setUid(Integer uid) { this.uid = uid; } public String getUname() { return uname; } public void setUname(String uname) { this.uname = uname; } //重写HashCode @Override public int hashCode(){ return Objects.hash(uid,uname); } //重写equals @Override public boolean equals(Object obj){ //潘丹 两个对象对峙是否一致 if (this==obj){ return true; } //非空判断和class类类型判断 if (obj==null||obj.getClass()!=getClass()){ return false; } //强转 UserInfo info=(UserInfo)obj; //判断对象字段值是否都是一致的 return uid==info.uid && Objects.equals(uname,((UserInfo)obj).uname); } }
四.HashMap和TreeMap应该如何选择
HashMap:
底层采用数组+链表(红黑树)结构,可以实现快速的存储和检索,但是数据是无序的,
适用于在Map当中插入删除或者获取元素
TreeMap:
存储结构是一个平衡二叉树,具体实现方式为红黑树,默认采用自然排序,
可以自定义排序规则,但是需要实现Comparator接口
能够便捷的实现内部元素的各种排序,但是性能比HashMap差,适用于按照自然排序和自定义排序规则
五.Set和Map的关系
Set核心就是保存不重复的元素,存储一组唯一的对象
set当中每一种实现都对应Map
HashSet对应的HashMap,TreeSet对应的TreeMap
进入HashSet源码

底层实际上是创建 了一个HashMap集合

进入HashMap源码

实际上HashMap底层调用的是Set
六.常见的Map排序规则
按照添加规则使用LinkedHashMap,按照自然排序或者自定义规则排序可以采用TreeMap
七.如何保证Map线程安全
多线程环境下,可以使用concurrent包下有一个ConcurrentHashMap或者是使用
Collections.synchronizedList(newHashMap<K,V>());
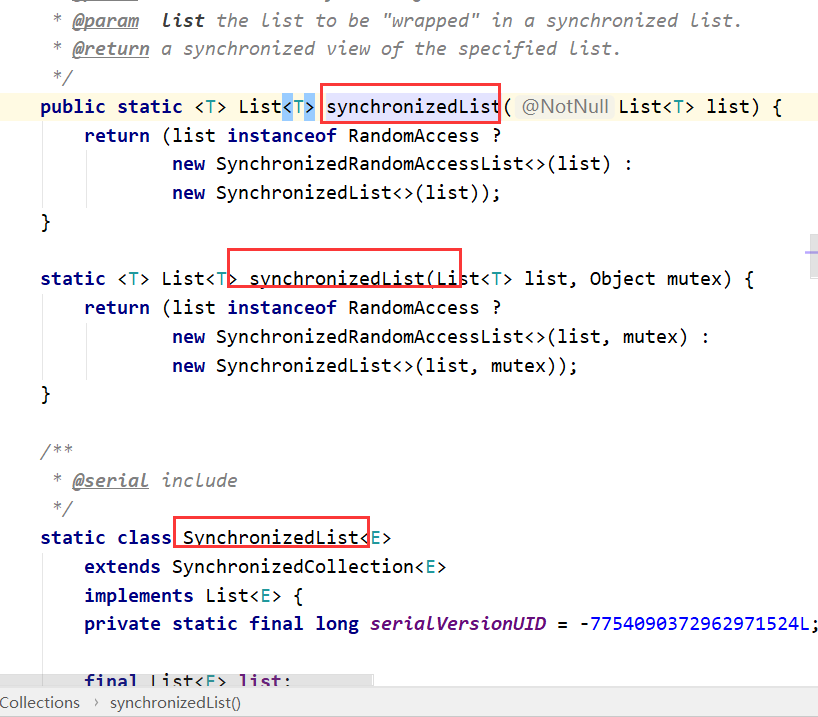
ConcurrentHashMap保证线程安全,效率比HashTable高,采分段锁