一。数据库相关的
1.索引相关
1.1 哪些字段需要建索引,索引的好处,及弊端
建索引注意点: 经常作为查询字段的,经常需要group by分组和order by排序的字段
经常更新的表,数据量小的,不同值少比如性别这些情况不建议用索引。
好处:查询快,分则和排序快,唯一索引可以保证字段唯一性
坏处: 占内存,索引是存放排序后地址的数据结构。表修改需要维护索引。创建和维护都需要时间。
索引分类:普通索引和唯一索引(主键索引就是),单列索引和组合索引
1.2 哪些情况不走索引,还有oracle的数据类型隐式转换
like语句: %不能放前面
使用函数: 例如 select * from student where left(s_name, 9)="99999ssss" ;
可以对索引列不使用函数,对常数项使用。上面这个不适用。
数据类型隐式转换:
测试表 t_test3 , 字段 c1 varchar2(20), 字段上创建了索引
select * from t_test3 where c1=11; -- 结果:观察执行计划,不使用索引,全表扫描,执行的时候做的转换为 (TO_NUMBER("C1")=11)
测试表 t_test4 , 字段 c1 number, 字段上创建了索引
select * from t_test4 where c1='11'; -- 结果:观察执行计划,使用了索引,转换为 "C1"=11
类型转换有隐式和显示
oracle--to_char(), to_number(), to_date()
1.3 索引保存的数据结构
索引是存放数据按B+Tree排序后 地址的数据结构,以文件形式存放
详细:https://blog.csdn.net/bible_reader/article/details/100007292
2. 数据库优化
- 读写分离
- 使用缓存
- 不要select *
- 每张表设置个ID,最好是INT类型 AUTO_INCREMENT,即使有唯一的VARCHAR类型字段也不要使用,因为VARCHAR类型会使主键性能降低
- 字段太多的表拆分多个表,将常用字段和不常用字段分开,不常用的字段会使查询变慢
- 增加中间表,经常联合查询的数据插入到中间表,查询时直接查中间表
3.sql题目
3.1 用户购买商品表,查询每个人购买最多的商品
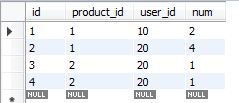
-- 查询每个商品购买数量及购买人数 select product_id, sum(num), count(distinct user_id) from test_user_order group by product_id; -- 查询每个人购买最多的商品 select t1.* from (select t.user_id,t.product_id,sum(num) nums from test_user_order t group by t.user_id,t.product_id) t1 join (select user_id ,max(nums) max_nums from (select t.user_id,t.product_id,sum(num) nums from test_user_order t group by t.user_id,t.product_id) t group by user_id ) t2 on t1.user_id =t2.user_id and t1.nums =t2.max_nums; -- 购买超过1种商品的用户 select user_id, count(distinct product_id) from test_user_order group by user_id having count(distinct product_id) >1
二。 JAVA
1.ThreadLocal的实现
线程内存储变量,每个线程读取的变量是相互独立的。线程间隔离了。


public void set(T value) { Thread t = Thread.currentThread(); ThreadLocalMap map = getMap(t); if (map != null) map.set(this, value); else createMap(t, value); } ThreadLocalMap getMap(Thread t) { // Thread中定义ThreadLocal.ThreadLocalMap threadLocals = null; // ThreadLocalMaps实际维护了一个数组Entry[] table; return t.threadLocals; }
实际是Thread, ThreadLocal, ThreadLocalMap三个类的关系
ThreadLocal定义了内部静态类ThreadLocalMap,Thread中实例变量ThreadLocalMap为每个Thread维护一个数组,数组的下标是ThreadLocal的hashcode变量,value为set方法设置的值。
map.set(this, value);方法
private void set(ThreadLocal<?> key, Object value) { // table就是ThreadLocalMap Entry[] tab = table; int len = tab.length; // 根据ThreadLocal的hashcode属性获取在数组中的位置 //同一线程不同ThreadLocal位置不一样 int i = key.threadLocalHashCode & (len-1); for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) { ThreadLocal<?> k = e.get(); if (k == key) { e.value = value; return; } if (k == null) { replaceStaleEntry(key, value, i); return; } } tab[i] = new Entry(key, value); int sz = ++size; if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash(); }
详细: https://www.jianshu.com/p/3c5d7f09dfbd
2.redis的持久化方式
有两种AOF和RDB。
AOF就是将修改命令追加到操作日志中,1s同步一次, 当文件很大时,根据现有的内存数据rewrite文件精简变小。性能低,一致性高。
RDB:就是半小时或几小时一次将内存数据快照到文件中。性能高IO少,一致性低
3.redis的数据类型
string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)
redis事务不具备原子性,只是批量执行,一个失败不影响其他。MULTI,EXEC.
4.concurrentHashMap的实现方式CAS加synchronized
由Node<K,V>[] table数组和链表和红黑树组成
先根据key算出hash值,根据hash值放在数组的某个位置上。若该位置Node为空没有元素,则使用CAS方式尝试添加根据该对象的偏移量判断当前值和期待的值一样则更新成新值。
如果该Node有元素则用synchronize锁定该Node,遍历列表修改或者添加末尾,红黑数的话就添加到树上。
更详细的: https://www.cnblogs.com/zerotomax/p/8687425.html#go0
5.创建线程的方式
(1)使用ThreadPoolExecutor类
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
corePoolSize:线程池的核心线程数;
maximumPoolSize:线程池的最大线程数;
keepAliveTime:线程池空闲时线程的存活时长;
unit:线程存活时长大单位,结合上个参数使用;
workQueue:存放任务的队列,使用的是阻塞队列;
threadFactory:线程池创建线程的工厂;
handler:在队列(workQueue)和线程池达到最大线程数(maximumPoolSize)均满时仍有任务的情况下的处理方式;
当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
(2)使用Executors类
本质上是一种方式,都是通过ThreadPoolExecutor类的方式
Java通过Executors提供四种线程池,分别为:
a、newFiexedThreadPool(int Threads):创建固定数目线程的线程池。
b、newCachedThreadPool():创建一个可缓存的线程池,不限制大小,调用execute 将重用以前构造的线程(如果线程可用)。如果没有可用的线程,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
c、newSingleThreadExecutor()创建一个单线程化的Executor。
d、newScheduledThreadPool(int corePoolSize)创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
6.JVM内存模型和垃圾回收机制???
https://www.cnblogs.com/xrq730/p/4827590.html
https://www.cnblogs.com/xrq730/p/4836700.html
三。spring
1.@Autowired注解与@Resource注解的区别
@Autowired:安照类型注入,默认依赖的对象必须存在,如果允许不存在设置required属性为false。
如果要按照名称注入,可以结合@Qualifier注解。
spring提供的。
@Resource:默认按照名称注入,不指定按照字段名称找,如果名称找不到对象就会通过类型找
指定了name或者type就只能按照名称或者类型找了。
jdk提供的
2.spring bean 初始化过程
https://www.jianshu.com/p/38032b0b9869 ?????
https://www.cnblogs.com/xrq730/p/5721366.html
3.spring 事务的隔离级别
@Transactional(isolation = Isolation.READ_UNCOMMITTED)
读取未提交数据(会出现脏读, 不可重复读) 基本不使用
@Transactional(isolation = Isolation.READ_COMMITTED)
读取已提交数据(会出现不可重复读和幻读)
@Transactional(isolation = Isolation.REPEATABLE_READ)
可重复读(会出现幻读)
@Transactional(isolation = Isolation.SERIALIZABLE)
串行化
脏读:读到其他事务未提交的数据。
不可重复读:一个事务内多次读数据不一样,因为同时另一个事务在UPDATE,DELETE并提交了。
幻读:同一个事务多次查询数目不一样,另一个事务inserte了
配置文件方式:
<tx:advice id="advice" transaction-manager="transactionManager"> <tx:attributes> <tx:method name="fun*" propagation="REQUIRED" isolation="DEFAULT"/> </tx:attributes> </tx:advice>
注解方式:
@Transactional(isolation=Isolation.DEFAULT) public void fun(){ dao.add(); dao.udpate(); }