kNN 算法是一种基于向量间相似度的分类算法。
1. 算法原理
k 最近邻(k-Nearest Neighbor)算法是比较简单的机器学习算法。它采用测量不同特征值之间的距离方法进行分类。它的思想很简单:如果一个样本在特征空 间中的 k 个最邻近(最相似)的样本中的大多数都属于某一个类别,则该样本也属 于这个类别。k表示外部定义的近邻数量。
举例说明,下图中可以清晰的看到由四个点构成的训练集。它被分为两个类别: A 类--蓝色圆圈、B 类--红色三角形。因为红色区域内的点距比它们到蓝色区域内的点距要小得。
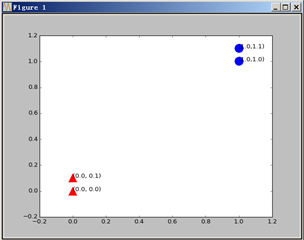
现在给定一个测试集,想要知道被划分为哪个分类,最简单的方法就是画图,把新加入的点加入图中。
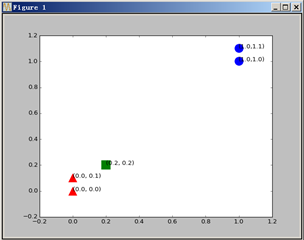
很清晰,从距离上看,它更接近红色三角的范围,应该归入B类。这就是kNN算法的基本原理。
由此可见,kNN算法的步骤如下:
(1)确定下 k 值(就是指最近邻居的个数)。一般是个奇数。
(2)确定的距离度量公式—文本分类一般使用夹角余弦,得出待分类数据点和 所有已知类别的样本点中,选择距离最近的 k 个样本。
(3)统计这 k 个样本点中,各个类别的数量,根据 k 个样本中,数量最多的样本是什么类别,我们就把这个数据点定为什么类别。
2. Python实现
(1)导入所需的库,数据的初始化
# -*- coding: utf-8 -*- import sys import os from numpy import * import numpyas np import operator from Nbayes_lib import * # 配置 utf-8 输出环境 reload(sys) sys.setdefaultencoding('utf-8') k=3
(2)实现夹角余弦的距离公式
# 夹角余弦距离公式 def cosdist(vector1,vector2): return dot(vector1,vector2)/(linalg.norm(vector1)*linalg.norm(vector2))
(3)实现kNN分类器
# 测试集:testdata;训练集:trainSet;类别标签:listClasses;k:k 个邻居数 def classify(testdata, trainSet, listClasses, k): dataSetSize = trainSet.shape[0] # 返回样本集的行数 distances = array(zeros(dataSetSize)) for indx in xrange(dataSetSize): # 计算测试集与训练集之间的距离:夹角余弦 distances[indx] = cosdist(testdata,trainSet[indx]) # 根据Th成的夹角余弦按从大到小排序,结果为索引号 sortedDistIndicies = argsort(-distances)
classCount={} for i in range(k): # 获取角度最小的前 k 项作为参考项 # 按排序顺序返回样本集对应的类别标签 voteIlabel = listClasses[sortedDistIndicies[i]] # 为字典 classCount 赋值,相同 key,其 value 加 1 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 # 对分类字典 classCount 按 value 重新排序 # sorted(data.iteritems(), key=operator.itemgetter(1), reverse=True) # 该句是按字典值排序的固定用法 # classCount.iteritems():字典迭代器函数 # key:排序参数;operator.itemgetter(1):多级排序 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] # 返回序最高的一项
3. 评估分类结果
使用 kNN 实现文本分类。
dataSet,listClasses = loadDataSet() nb = NBayes() nb.train_set(dataSet,listClasses) # 使用之前贝叶斯分类阶段的数据集,以及Th成的 tf 向量进行分类 print classify(nb.tf[3], nb.tf, listClasses, k)