上篇(webRTC中音频相关的netEQ(一):概述)是netEQ的概述,知道了它主要是用于解决网络延时抖动丢包等问题提高语音质量的,也知道了它有两大单元MCU和DSP组成。MCU 主要是把从网络收到的语音RTP包放进packet buffer内,同时也会根据计算出来的网络延时和抖动缓冲延时以及DSP单元反馈过来的信息决定给DSP发什么控制命令(命令主要有正常播放、加速、减速、丢包补偿、融合等),也会把语音包从packet buffer里取出来给DSP单元处理。DSP主要是对取出来的语音包解码并根据MCU给出的控制命令做信号处理。本篇我们继续讲netEQ,讲主要的数据结构。
要研究一个模块,首先得搞清楚它的数据结构。netEQ中最顶层的结构体是MainInst_t(也就是netEQ结构体),它主要包含两个成员变量,一个是DSPInst_t,另一个是MCUInst_t,正好对应netEQ的两个单元DSP和MCU。具体见图1(这里把次要的成员变量忽略掉了,下同)。在netEQ初始化时生成netEQ的实例,实例中包含DSP和MCU两个子实例。
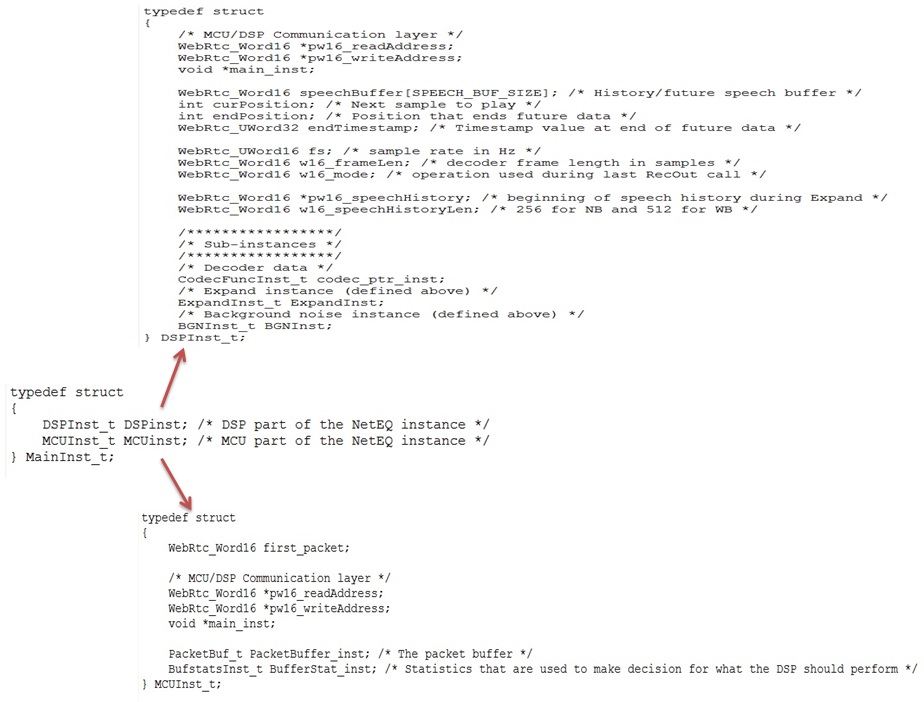
图 1
先看DSP结构体,见图1。pw16_readAddress 和pw16_writeAddress用于与MCU交互数据。MCU中也有这两个成员变量,先说一下MCU和DSP是怎么交互的。MCU会给DSP发控制命令执行何种信号处理算法,就把命令相关的数据写在自己的pw16_writeAddress的地址上,让 DSP到这个地址上取数据,即DSP的pw16_readAddress就是MCU的pw16_writeAddress。DSP处理完一帧后会给MCU发反馈数据,反馈数据就写在自己的pw16_writeAddress地址上,MCU就从这个地址上去读反馈数据, 即MCU的pw16_readAddress就是DSP的pw16_writeAddress。main_inst指向父结构体netEQ(MainInst_t),这是一种常见的操作手法,便于找到父结构体实例。speechBuffer(语音buffer)用于存放经过解码和信号处理过的语音数据。它分两块,一块是已经播放过的语音数据,另一块是未播放过将要播放的语音数据,成员变量curPosition是分界点。另一成员变量endPosition表示语音buffer的大小,这依据采样率来定。可以用图2表示这三个成员变量的关系:
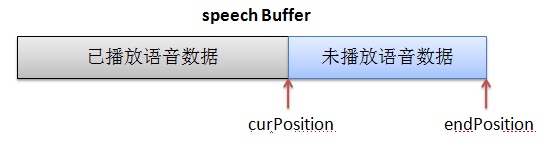
图 2
endTimestamp用于记录语音buffer中未播放的语音数据的最后的时间戳(MCU给DSP的控制命令中会带当前帧的时间戳,解码后通过换算就可以得到endTimestamp)。fs是采样率。w16_frameLen是每帧的采样点数。w16_mode是当前帧的处理方法(是加速处理还是减速处理等),这个值会带给MCU,MCU根据这和网络延时抖动缓冲延时等决定下一帧的处理命令。pw16_speechHistory和w16_speechHistoryLen用于丢包补偿(PLC,控制命令是EXPAND),pw16_speechHistory放最近播放过的历史语音数据,要做PLC时就以这些历史语音数据作为参考数据产生补偿的语音数据。w16_speechHistoryLen是放历史语音数据的buffer(即pw16_speechHistory)的长度,是个定值,依采样率而定。DSP结构体中还有几个子实例,主要有decoder实例(CodecFuncInst_t)、丢包补偿实例(ExpandInst_t)和背景噪声生成实例(BGNInst_t)。
上面说到MCU和DSP的数据交互,我们看一下交互的是什么数据。MCU发给DSP的是控制命令,控制命令数据占3个short大小,第一个short是命令相关的,第二三个是timestamp的高16位和低16位。DSP发给MCU的是反馈数据,反馈数据的结构体如图3:

图 3
playedOutTS表示语音buffer中最后数据的时间戳,等于DSP结构体中的endTimestamp。samplesLeft表示语音buffer总未播放的数据长度。lastMode表示上一帧的处理方法,等于DSP结构体中的w16_mode。frameLen表示上一帧解码后成长度。
再看MCU结构体,见图1。first_packet在初始化时置成1,后来收到包后置成0。用它主要是对收到第一个包后给MCU的一些成员变量(比如SSRC)赋值。pw16_readAddress 和pw16_writeAddress用于与DSP交互数据,同DSP中的一样。main_inst也同DSP中的一样。MCU中也有两个主要的实例,一个是PacketBuffer_inst,它用于存放从网络收到的语音包。另一个是BufferStat_inst,它用于统计网络延时等。这两个均是非常重要的结构体。先说PacketBuffer_inst,它的定义如图4:

图 4
初始化时会分配一块可以存放最大个数(最大个数事先定义好了)语音包的buffer。存放的内容有timeStamp/payloadLocation(包的payload放的地址,指向payload)/seqNumber/payloadType/payloadLengthBytes/rcuPlCntr/waitingTime/payload等(见上图的红框内部分)。存放时并不是每个包的timestamp/payload等放在一起,而是所有包的timestamp放在一起,所有包的sequence number放在一起,其他也是,这样就得到了如下的buffer分布图5:

图 5
图5看起来不直观。netEQ中有slot的概念,每个包的timestamp/payload等放在同一个slot内,这样图5就可以表示成图6(图中每块 buffer都是连续的,上一块buffer的尾部就是下一块buffer的首部,比如timestamp的尾部就是payload location的首部),这样看起来就直观多了。要获取某个包的属性或者payload,就可以通过slot_index得到。比如要获取第0个包的timestamp,就可以表示成timestamp[0]。怎样存放包搞清楚了就可以很好的理解这个结构体内的其他成员变量了。packSizeSamples表示上一解码的包有多少个采样点。startPayloadMemory表示放payload的起始地址。memorySizeW16表示分配的buffer还剩下的memory size。currentMemoryPos表示放下一个包的payload的起始地址,这个值会放在下一个包的对应的payloadLocation里。等下一个包来后,currentMemoryPos会加上这个包的payload长度重新赋给currentMemoryPos,并作为放下下个包的payload的起始地址。numPacketsInBuffer表示packet buffer里放了多少个包。insertPosition表示下一个包要放的位置。maxInsertPositions表示packet buffer最大可放的包个数。discardedPackets表示主动丢弃的包个数。

图 6
再说BufferStat_inst,它的定义如图7:

图 7
w16_noExpand表示上一包的处理是不是EXPAND。avgDelayMsQ8表示平均缓冲延时。maxDelayMs表示最大缓冲延时。AutomodeInst_t是BufferStat_inst的子实例,,主要用于计算网络延时和抖动缓冲延时。它的定义如图8:

图 8
成员变量主要分三部分,一是iat(inter-arrival time,相邻包到的时间间隔)统计相关的, iat以包个数为单位,假设一个包20Ms,两个相邻包到的时间间隔是40Ms,iat就为2。有一个大小为65的数组来存放iat(iat从0到64)个数统计的值,基于这些值算网络延迟统计值。二是iat峰值统计相关的,用两个长度为8的数组来存放iat的峰值,一个用来存放峰值幅度,另一个用来存放峰值间隔。峰值间隔是automode结构体中另一个参数peakIatCountSamp,它用于统计当前探测到的峰值距离上次峰值的时间间隔,以采样点个数为单位。三是包相关的,有lastSeqNo(上一个收到包的sequence number)、lastTimeStamp(上一个收到包的timestamp)等。这些都是为了计算optBufLevel(网络延时)和buffLevelFilt(抖动缓冲延时)。MCU发给DSP的控制命令就是根据网络延时和抖动缓冲延时以及上一次的处理方式等得到的。需要注意的是这些变量中一些是以Q格式(Q格式相关的可以见我前面的文章Android手机上Audio DSP频率低 memory小的应对措施)表示的,算网络延时和抖动缓冲延时都是用Q格式算的,这加大了理解的难度。